On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
| Note |
|---|
MySQL account settings have been shared across different MySQL Snaps and the batch size settings varies the performance for some of the Snaps. We recommend changing the batch size setting (within the account details) to 100k or 200k for only the MySQL Bulk Load Snap (these batch size settings for bulk load may vary based on the environment settings but this range should be ideal). |
| Note |
|---|
The bulk load feature is disabled by default for MySQL 8.0 and higher versions. To use the MySQL Bulk Load Snap with MySQL v8 and higher, enable the server and the Snap as a client of the Bulk Load feature in the JDBC driver. To enable the bulk load feature in the JDBC driver, perform the following actions:
|
Snap type: | Write | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Description: | Snap executes MySQL bulk load. This Snap uses the LOAD DATA INFILE statement internally to perform the bulk load action. The file is first copied to JCC node, then to MySQL server under tmp directory and finally to the target MySQL table.
| |||||||||||||
| Note |
|---|
|
[None]
Does not work in Ultra Pipelines.
| Multiexcerpt include macro | ||||
|---|---|---|---|---|
|
This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See MySQL Account for information on setting up this type of account.
| Note |
|---|
MySQL account settings have been shared across different MySQL Snaps and the batch size settings varies the performance for some of the Snaps. We recommend changing the batch size setting (within the account details) to 100k or 200k for only the MySQL Bulk Load Snap (these batch size settings for bulk load may vary based on the environment settings but this range should be ideal). |
| Input | This Snap has one document input view by default. A second view can be added for metadata for the table as a document so that the target absent table can be created in the MySQL database with a similar schema as the source table. This schema is usually from the second output of a database Select Snap. If the schema is from a different database, there is no guarantee that all the data types would be properly handled. |
|---|---|
| Output | This Snap has at most one document output view. |
| Error | This Snap has at most one document error view and produces zero or more documents in the view. |
Settings
Label
Schema name
The database schema name. In case it is not defined, then the suggestion for the Table name will retrieve all tables names of all schemas. The property is suggestible and will retrieve available database schemas during suggest values.
| Note |
|---|
The values can be passed using the pipeline parameters but not the upstream parameter. |
Example: SYS
Default value: [None]
Table name
Required. Table on which to execute the bulk load operation.
| Note |
|---|
The values can be passed using the pipeline parameters but not the upstream parameter. |
Example: people
Default value: [None]
Create table if not present
Whether the table should be automatically created if it is not already present.
Default value: Not selected
Partitions
This is used to specify a list of one or more partitions and/or subpartitions. When used, if any input document cannot be inserted into any of the partitions or subpartitions named in the list, the input document will be ignored.
Default value: Not selected
Columns
When no column list is provided, input documents are expected to contain a field for each table column. When a column list is provided, the Snap will load only the specified columns.
Default value: Not selected
Set Clause
Required. This is used to assign values to columns. For example, you can use "COLUMN1 = 1" to insert integer 1 to column COLUMN1 for each input document. See this link for more information.
Default value: [None]
On duplicates
Required. Specifies the action to be performed when duplicate records are found. In other words, rows that have the same value for a primary key or unique index as an existing row. If you choose REPLACE, input rows replace the existing rows. If you choose IGNORE, input rows are ignored.
Default value: IGNORE
Concurrency Option
Specifies how to handle the load process when other clients are reading from the table.
Available concurrency options are:
- LOW_PRIORITY - If this option is selected, the loading process is delayed until no other clients are reading from the table. This affects only storage engines that use only table-level locking (such as MyISAM, MEMORY, and MERGE).
- CONCURRENT - If this option is used with a MyISAM table that satisfies the condition for concurrent inserts (that is, it contains no free blocks in the middle), other threads can retrieve data from the table while MySQL Bulk Load Snap is executing. This affects the performance of the MySQL Bulk Load Snap a bit, even if no other thread is using the table at the same time.
Default value: None
Character Set
The MySQL server uses the character set indicated by the character_set_database system variable to interpret the information in the inputs. If the contents of the inputs use a character set that differs from the default, it is recommended that you specify the character set of the inputs with this property. A character set of binary specifies "no conversion".
| Note |
|---|
It is not possible to load data that uses the ucs2, utf16, utf16le, or utf32 character set. |
Default: [None]
Chunk size
Specifies the number of records to be loaded at a time.
Note: This property will override the "Batch size" property of the account
Default: 100000
| Multiexcerpt include macro | ||||
|---|---|---|---|---|
|
| Multiexcerpt include macro | ||||
|---|---|---|---|---|
|
| Note |
|---|
When invalid data is passed to the Snap, the Snap execution fails. The database administrator can set a global variable that can either handle an invalid case by passing a default value (such as, if strings are passed for integers, then pass the value 0) , or by displaying an error. See Load Data Syntax for more information. |
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|
Example
The following example illustrates the usage of the MySQL Bulk Load Snap. In this pipeline, we map the data using the Mapper Snap, insert it into the target table using the MySQL Bulkload Snap, read the data using the MySQL Select Snap and additionally sending the first document to the output view using the Head Snap.
The pipeline:
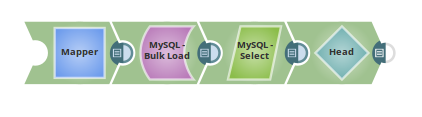
1. The mapper Snap maps the data and writes the result to the target path, enron numeric_table.
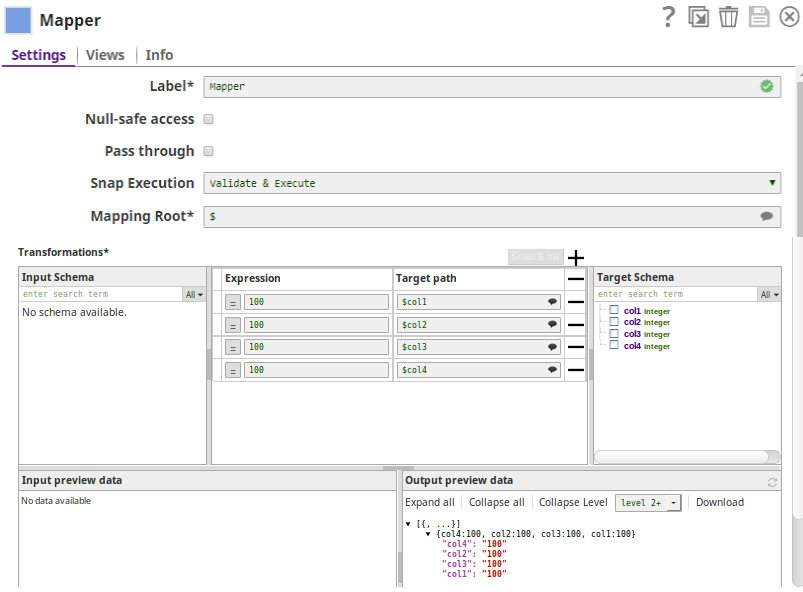
2. The MySQL Bulk Load Snap loads inputs to the table, enron numeric_table.
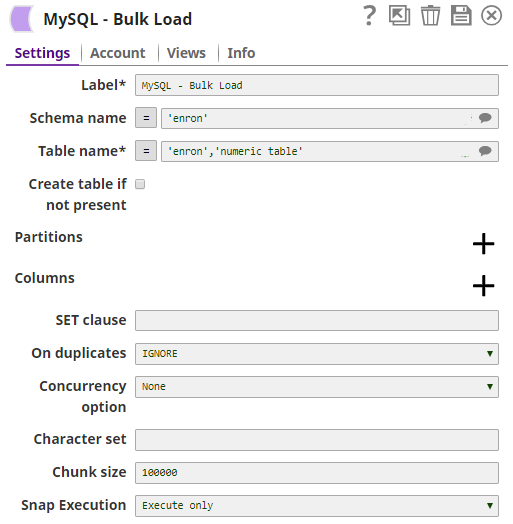
3. The MySQL Select Snap gets records from the table, enron numeric_table where the clause is col1= 100.
4. The Head Snap is set to1, meaning it would send the first document to the output view, and hence the MySQL Select Snap passes the first document only.
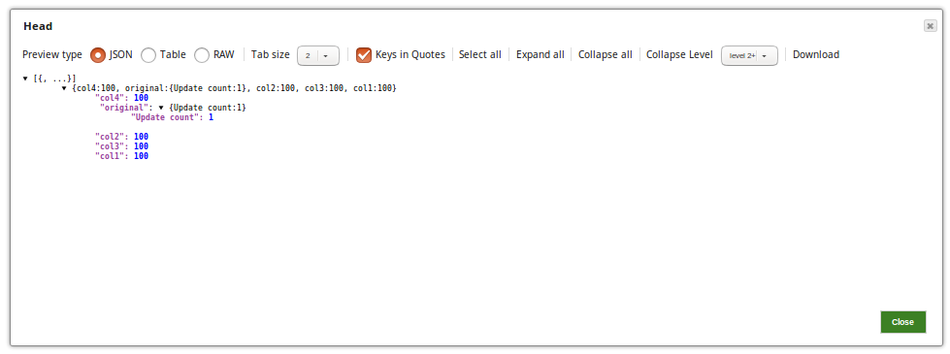
Successful execution of the pipeline gives the following output preview.
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|