On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
Snap type: | Format | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Description: | This Snap reads the documents, converts them into .XLSX format using a specified sheet and writes out binary data. | |||||||||||||
Prerequisites: | If you are using OpenJDK 11 in the Snaplex on which you want to execute Excel Formatter Snaps, you must install Fontconfig on the Snaplex. if you execute a Pipeline on a Snaplex that does not have Fontconfig installed, you may see the following null pointer exception: To install Fontconfig, run the following command:
| |||||||||||||
| Support and limitations: | None. | |||||||||||||
| Account: | Accounts are not used with this Snap. | |||||||||||||
| Views: |
| |||||||||||||
Settings | ||||||||||||||
Label | Required. The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | |||||||||||||
Sheet name | The name of the Excel sheet. Example: Members | |||||||||||||
Write header | Required. This option specifies whether or not the Snap should write the header to the output. | |||||||||||||
Ignore empty stream | If the property is unchecked, an empty array will be written to the output view in case no documents were received on the input view. If the property is checked, the then the Snap will write nothing to the output view in case no documents were received on the input view. Default value: Not selected | |||||||||||||
| Convert numeric string to number | This property sets the behavior of the Snap when a value in the input document is a numeric string. If selected, the Snap converts the value to a numeric-type cell. If not selected, the Snap sets the value to a string-type cell. Default value: Selected | |||||||||||||
| Translate date and time types | This property sets the behavior of the Snap when a value in the input document is a date and/or datetime type. If selected, the Snap does not convert the date and/or datetime types to text/string and instead converts it to Excel date numeric type with date format style. Default value: Not selected | |||||||||||||
| Include all columns | The Snap uses the first input document to write the header. If subsequent input documents have additional fields, truncate rows or columns in between, they are not included in the output. If this property is selected, the Snap detects those additional fields in all the input documents, updates the header and includes all values in the output. If not selected, and the subsequent input document has any truncate values, an empty output data preview is displayed. Default value: Not selected | |||||||||||||
|
| |||||||||||||
Example
Updating Excel Sheets with the Headers Including All the Values
In the below pipeline, the Excel Formatter Snap used the setting Include all columns, that enables the Snap update the Excel sheet with the headers including all the values:
Writing to Multiple Excel Sheets in the Output
This example demonstrates how you can use the Excel Formatter Snap to classify Excel data and route it to different worksheets in the output file based on the values in a specific field.

Download the Pipeline.
In the sample Pipeline, the JSON Generator Snap output contains records with two values for the country field, Canada and United States.
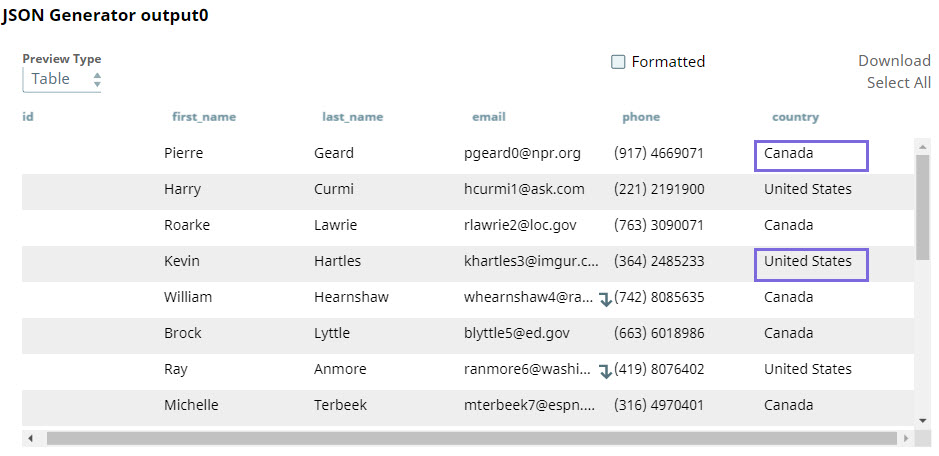
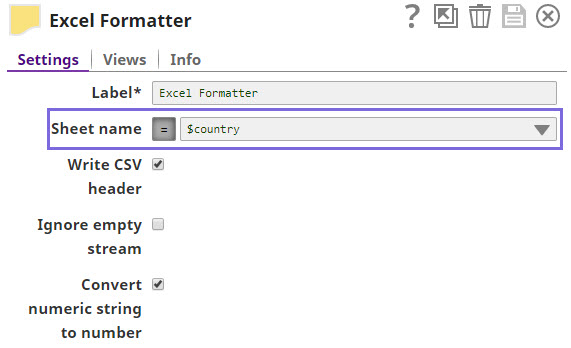
In the Excel Formatter Snap, if you select the value $country in the Sheet name field, the input data is organized into two sheets based on each unique value in the country field.
The Snap's output preview shows records for Canada grouped together in one sheet:
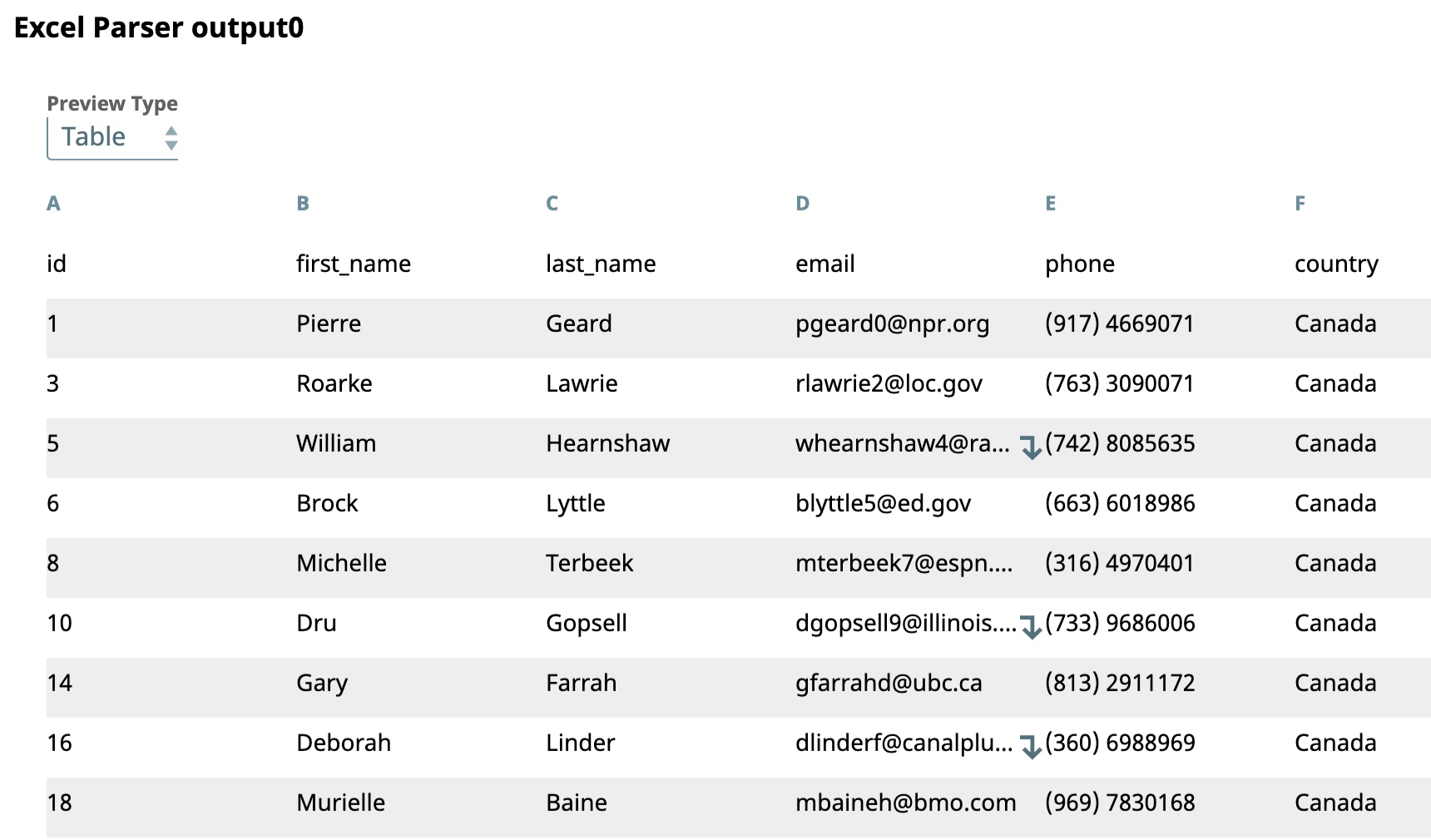
The final output shows an Excel file containing two worksheets, one for Canada and the other for United States.
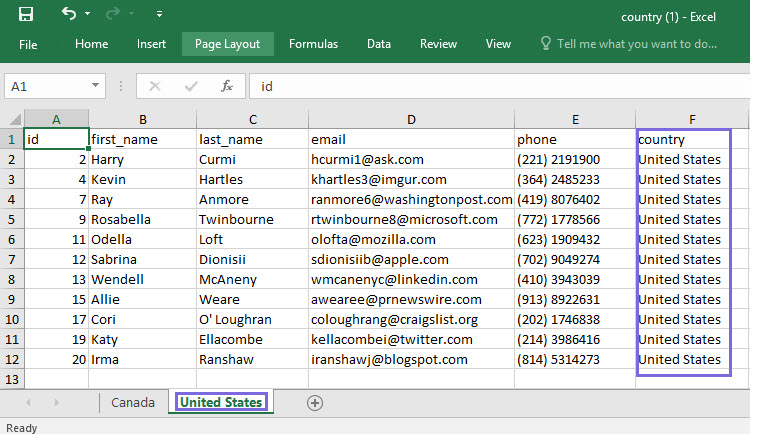
Similarly, you can select any field in the Sheet name drop-down list to create an output file with separate sheets for each unique value of the field.
Downloads
| Attachments | ||||
|---|---|---|---|---|
|
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|