On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
Snap type: | Transform | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Description: | The Snap groups Snap groups data from multiple input documents into batches of output documents by size(number)each output document. Each batch is an output document with a list contains an array of input Map data as a value at the location specified by the Target field property. The size of the list of input Map data an array is specified by the Group size property. The number of output documents is, the number of input documents divided by the Group size, rounded up, except when the Memory Sensitivity property is set to Dynamic, which allows the group size to vary dynamically.
| |||||||||||||
| Prerequisites: | All input documents should be of Map data type. | |||||||||||||
| Support and limitations: | Does not work in Ultra Pipelines. | |||||||||||||
| Account: | Accounts are not used with this Snap. | |||||||||||||
| Views: |
| |||||||||||||
Settings | ||||||||||||||
Label | Required. The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | |||||||||||||
Target field | Required.Target field name to be used as a key in the output document or a JSON path where a list of input Map data would be located Specifies the JSON path where the group array should be located within each output document. Example: "grouped_data", "$group", "$group.list" Default value: "group" | |||||||||||||
| Memory Sensitivity | Required. Indicates the Snap's behavior towards memory changes. Choose one of the available options:
| |||||||||||||
Group size | Required. Enter the number of input documents to be grouped into a single output document. A value of 0 instructs the Snap to group all the input documents into a single document. When Memory Sensitivity is Dynamic, this field specifies the maximum size of the group.
Example: 15000 Minimum value: 0 Maximum value: No maximum value. Default value: 10 | |||||||||||||
| Min Group Size | Activated when Memory Sensitivity is set to Dynamic. Enter the minimum number of input documents to be grouped into a single output document.
| |||||||||||||
| Flush Timeout | Required. Enter a non-zero value in this field to specify the number of seconds which can pass with no new input before the Snap should output a partial group, a group containing fewer than Group Size input documents.
Example: 10 Default value: 0 | |||||||||||||
|
| |||||||||||||
Examples
| Expand | ||||
|---|---|---|---|---|
| ||||
Input and Output Documents in CodeAssume an input stream of five documents as follows:
If we set the Group size property to "2" and the Target field property to "$group.list", there will be three output documents as follows:
|
| Expand | ||
|---|---|---|
| ||
Input and Output Documents in a PipelineIn this pipeline, the Group By N Snap groups the input documents into batches by the group size. The File Reader Snap passes the input documents to be parsed and sorted by the Group By N Snap.
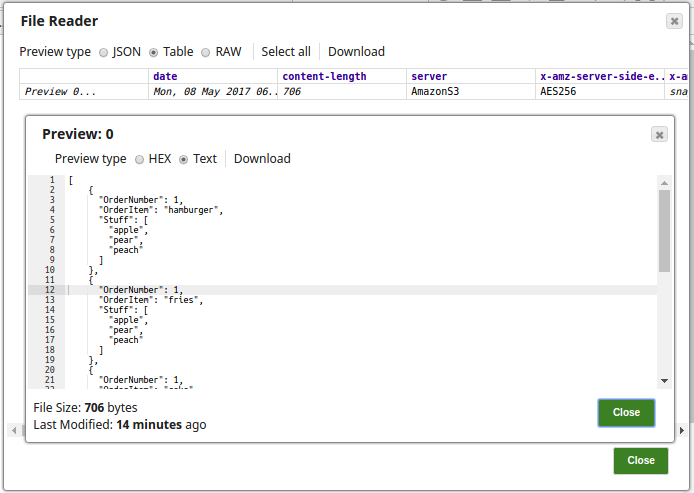
The File Reader Snap passes the input document order.json to be grouped into batches by size.
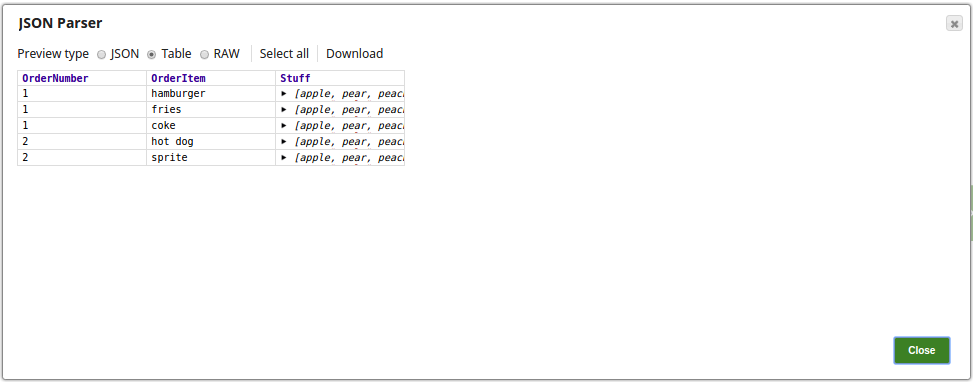
The JSON Parser Snap parses the binary input from the File Reader Snap:
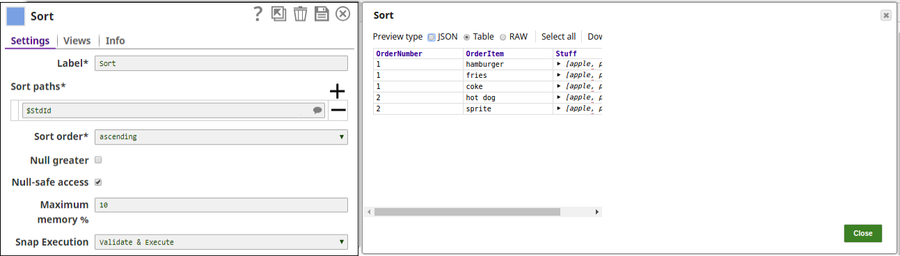
The Sort Snap sorts the input documents in ascending order. The respective output preview:
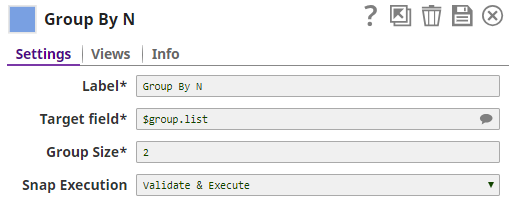
The Group By N Snap groups the Target Field $group.list in the size of 2 meaning each group will have a batch of two output documents.
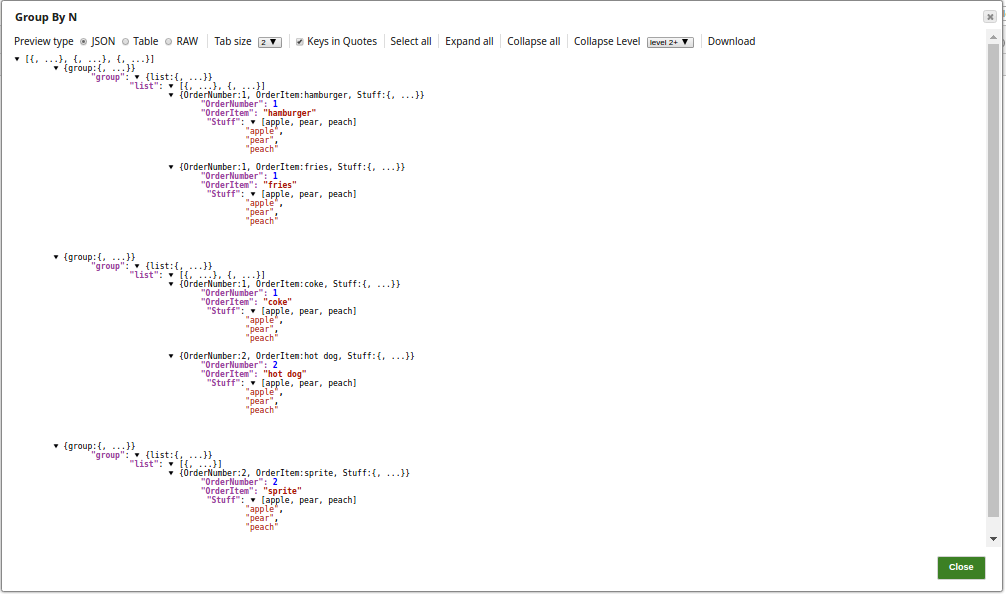
The output preview from the Group By N Snap with the grouping into batch of output documents by Group size 2:
|
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|