On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
Overview
Snap type | Transform | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Description | This Snap joins two or more data streams. It supports inner, left outer, and outer joins. If input data streams are sorted (ascending or descending), it is a streaming Snap at highly optimized performance. If the data streams are not sorted, you may use a Sort Snap in front of the Join Snap or select UNSORTED for the Sorted streams property. Please note that all documents in the same input view must have the same set of fields, otherwise, the naming of the fields in the output documents may appear to be inaccurate.
| |||||||||||||
| Prerequisites | All documents in the same stream should have the same set of fields. | |||||||||||||
| Known Issue, support and limitations | Known Issue: When the upstream Snaps of the Join Snap contains Copy, Router, Aggregate, or similar Snaps, it is likely that the data flow of a branch in the Pipeline gets blocked until another branch completes streaming the document . The Join Snap might hang if its upstream Snap has a blocked branch. Workaround: Set Sorted streams to Unsorted in the Join Snap to effectively buffer all documents in all input views internally—this unblocks the document flow of all the upstream branches. The internal sorters sort the input documents from the input views into the local temporary stage. Limited support in Ultra Task Pipelines:
| |||||||||||||
| Account | Accounts are not used with this Snap. | |||||||||||||
| Views |
| |||||||||||||
Settings | ||||||||||||||
Label | Required. The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | |||||||||||||
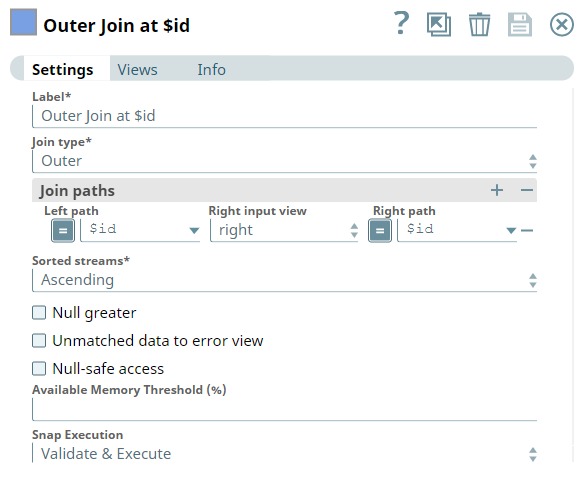
Join Type
| Required.The type of join to execute. The options available include:
Default value: Inner
| |||||||||||||
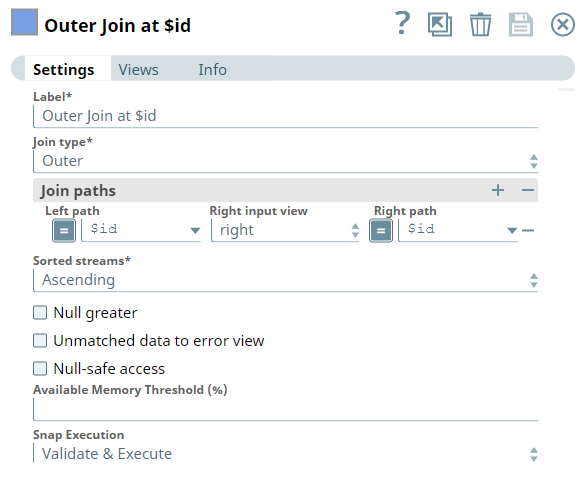
Join paths | JSON paths to use for left and right sides of the join. Each row in the table defines a relationship between the left-field and one of the right fields. To use a partial set of join path relationships, use multiple Join Snaps. Default value: [None] | |||||||||||||
Left path | Required. The JSON path to a value in a document of the first input view. One of the suggested field names should be selected. This property does not support expressions. | |||||||||||||
Right input view | Required. Right input view name which is the second or another next input view. | |||||||||||||
Right path | Required. The JSON path to a value in a document of the second or another next input view. One of the suggested field names should be selected. This property does not support expressions. | |||||||||||||
| Sorted streams | Required. How the data is sorted. Options available are Ascending, Descending, or Unsorted. If an Unsorted data stream is selected, the Snap sorts input data streams before it starts the join operation. Default value: Ascending | |||||||||||||
Null greater | If selected, null values are considered greater than non-null values. In conjunction with Sort streams:
Default value: Not selected | |||||||||||||
Unmatched data to error view | If selected, unmatched left input documents are passed to the error view only if the Join type is 'Inner'. Default value: Not selected (false) | |||||||||||||
Null-safe access | If selected, the Snap will ignore missing data when accessing the join path. For example, a join path is '$id', but the 'id' key does not exist in the input data. In this case, the Snap will assume its value is null and continue. If unselected, the Snap will write an error to the error view for missing data and stop the execution. Default value: Not selected (false) | |||||||||||||
| Available Memory Threshold (%) | The Snap keeps all the Right input view documents with the same join-path values in memory until the join operation is done for the specific join-path values. When the Right input view has more than 10,000 input documents with the same join-path values, the Snap checks if the available memory is less than the threshold value mentioned in this property. If so, it starts to store input data into local temporary files to prevent the node from out of memory.
| |||||||||||||
|
| |||||||||||||
| Multiexcerpt macro | ||
|---|---|---|
| ||
Temporary FilesDuring execution, data processing on Snaplex nodes occurs principally in-memory as streaming and is unencrypted. When larger datasets are processed that exceeds the available compute memory, the Snap writes Pipeline data to local storage as unencrypted to optimize the performance. These temporary files are deleted when the Snap/Pipeline execution completes. You can configure the temporary data's location in the Global properties table of the Snaplex's node properties, which can also help avoid Pipeline errors due to the unavailability of space. For more information, see Temporary Folder in Configuration Options. |
Examples
Providing Consistent Input Schema to Get Correct Joined Output
This example Pipeline demonstrates how you can get expected output joined data from two inputs by providing a consistent input schema. We use the Join Snap to accomplish this task.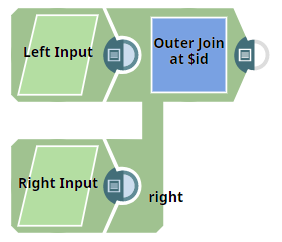
First, we provide input documents with consistent input schema using JSON Generator Snaps as shown below.
| Left Input Schema | Right Input Schema |
|---|---|
 |
|
Upon validation, the Snap displays the following joined output as a result of providing a consistent input schema. The key name of the right view is the same as in the left view; hence, the Join Snap prefixes it with the right view label in the output data, right_id, right_field1 and right_field2.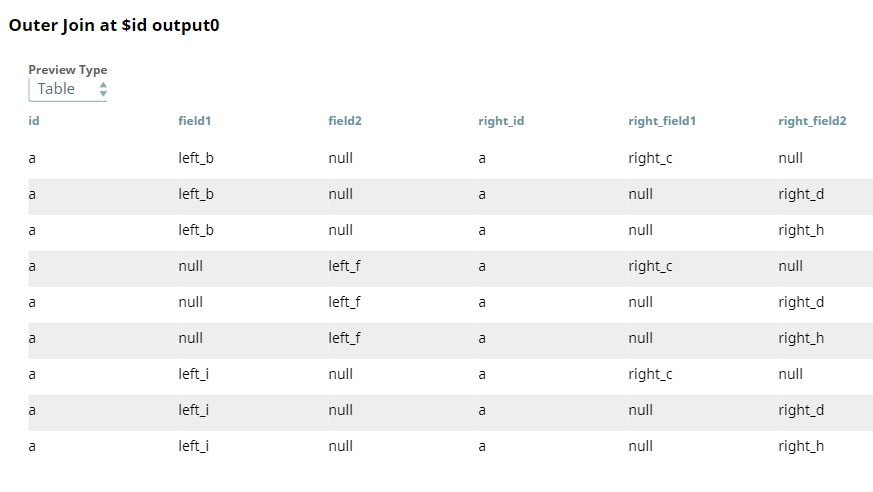
Inconsistent Joined Output Data as a Result of Inconsistent Input Schema
This example Pipeline demonstrates how the Join Snap generates inconsistent output joined data by providing inconsistent input schema in your inputs.
First, we provide input documents with inconsistent input schema using JSON Generator Snaps.
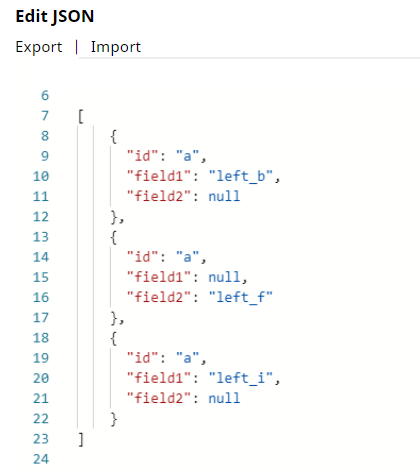
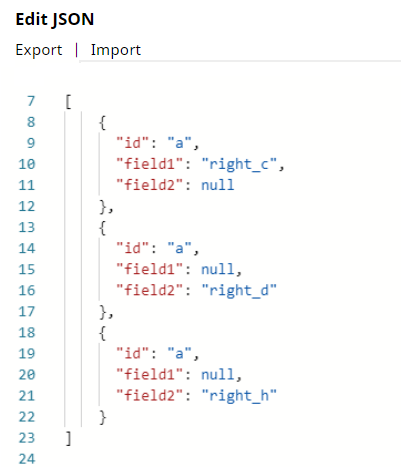
The complete key set of input documents is {“id”, “field1”, “field2”}. Note that field2 entry is missing in the first left input document, the field1 entry is missing in the second left input document, and so on. The missing entries with null values cause unexpected results in the joined output data.
| Left Input Schema | Right Input Schema |
|---|---|
|
|

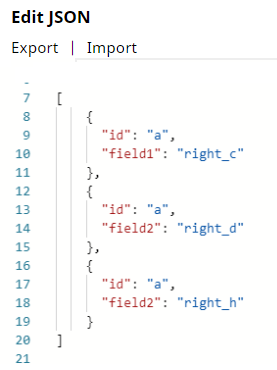
Upon validation, the Snap displays inconsistent output result, because the input documents contain incomplete key sets. The value right_c appears in the column field1 and the values right_d and right_h appear in the column field2, wherein they should be under right_field1 and right_field2 columns respectively.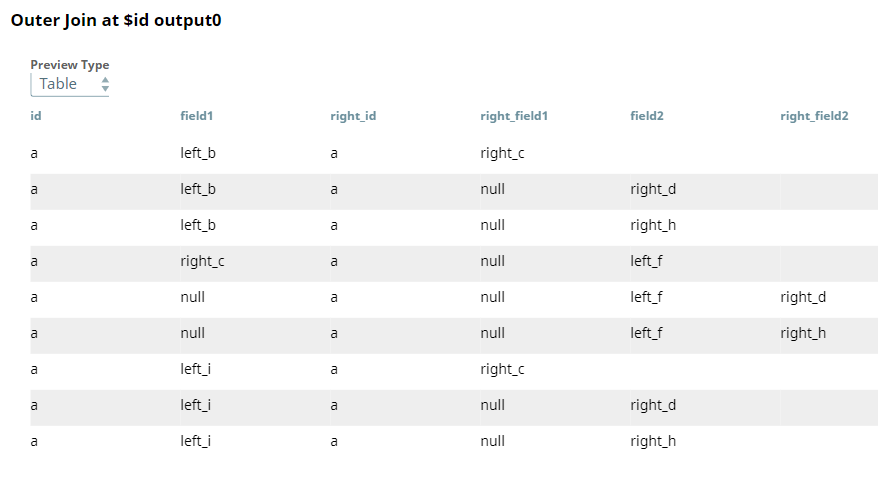
Merging Documents
You can use the Merge Join type to merge documents.
In this example:
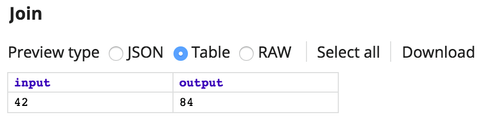
- $input comes into input0 and contains a value of 42
- $output comes into input1 and contains a value of 84
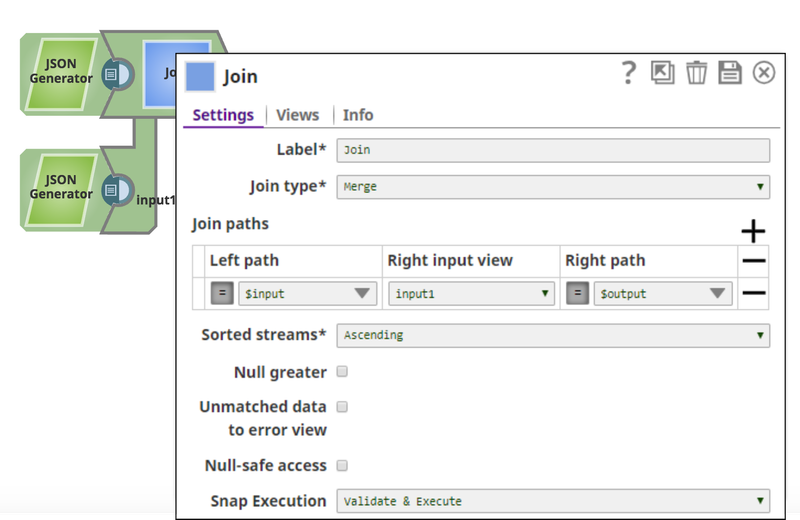
- Join type: Merge
- Join Path:
- Left path: (expression toggle on) $input
- Right input view: input1
- Right path: (expression toggle on) $output
- Sorted streams: Ascending
Merge Result:
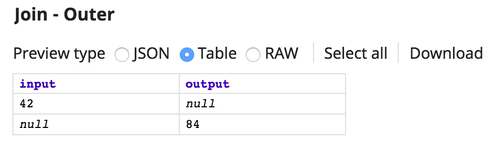
If the Join type is changed to Outer, the result is:
If the Join type is changed to Left Outer, the result is:
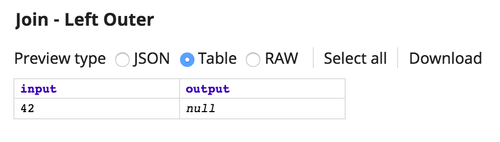
If the Join type is changed to Inner, no results are returned because there are no shared records.
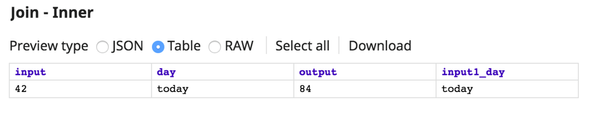
If both inputs have a record of $day with a value of today added, set the paths to $day and the Join type to Inner. The result will look like this:
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|