On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
Snap type: | Transform | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Description: | This Snap converts binary data at the input view to a document data at the output view.
| |||||||||||||
| Prerequisites: | [None] | |||||||||||||
| Support and limitations: |
| |||||||||||||
| Account: | Accounts are not used with this Snap. | |||||||||||||
| Views: |
| |||||||||||||
Settings | ||||||||||||||
Label | Required. The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | |||||||||||||
Encode or Decode | Required. Select if the content should be encoded or decooded. The options are:
If the input "content" data has already been Base64-encoded and ENCODE_BASE64 is selected, the Snap will not encode the content again. In the same way, if the input "content" data has not been Base64-encoded and DECODE_BASE64 is selected, the Snap will not attempt to decode the content. The format option DOCUMENT allows you to serialize the document into a SnapLogic-specific JSON represenation, which allows you to deserialize types such as Dates when read back using a BinaryToDocument Snap. BYTE_ARRAY is used to pass raw binary data. For example, a compressed .zip file can be created in many formats. The safest way to convert such a file between binary and document is with BYTE_ARRAY. When NONE is selected, the Snaplex's default platform specific encoding is used.This can be used for string text such as a .xml or a .csv format. Because this uses platform specific encoding, it can vary between Snaplexes; therefore it is not advised to use NONE when passing data between pipelines that may be running in Snaplexes which run different operating systems.
| |||||||||||||
Ignore empty stream | If selected, the Snap will do nothing when no document has been received in the input view. Example: Selected Default value: Not selected | |||||||||||||
|
| |||||||||||||
Example
Uploading a PDF File Attachment to a Salesforce Account Record
To upload a PDF file attachment to a Salesforce Account record, prepare a pipeline of File Reader Snap + Binary to Document Snap + Mapper (Data) Snap + Structure Snap + Salesforce Create Snap.
- File Reader Snap: Enter a pdf file URL in the File property.
- Binary to Document Snap: Select "ENCODE_BASE64" for the Encode or Decode property.
- Mapper (Data) Snap: Enter one row of "$Id" in the Target path property and an ID of an existing Account SObject record.
Structure Snap: Mapping table property
Source path Operation Target path $original.content-location move $Name $Id move $Id $original.content-type move $ContentType $content move $Body - Salesforce Create Snap: Enter "Attachment" in the Object type property.
The following pipeline reads the binary data from the upstream and converts it into document data in the output preview.
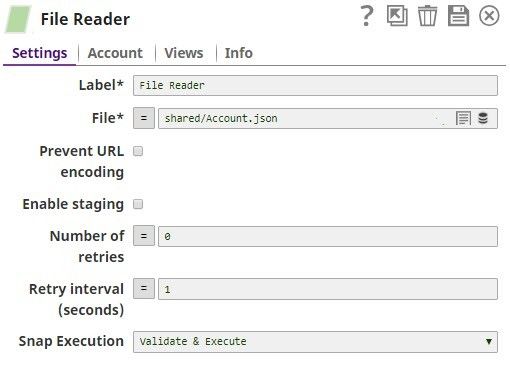
The File Reader Snap reads the binary data to be converted:
The output preview when ENCODE_BASE64 is selected:

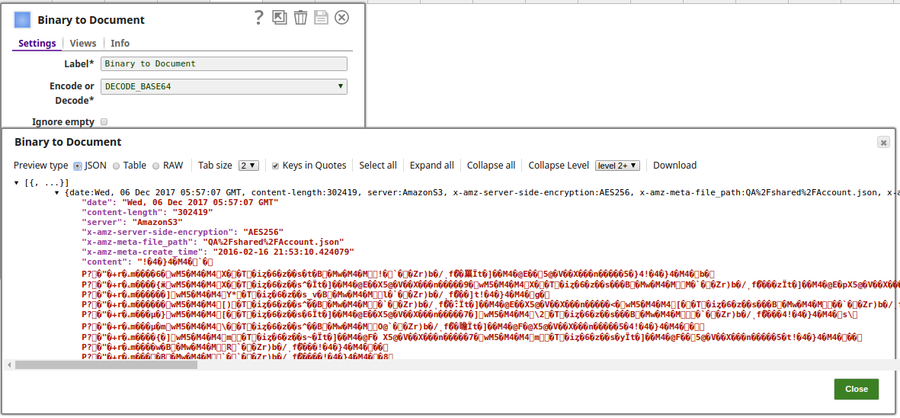
The output preview when DECODE_BASE64 is selected:
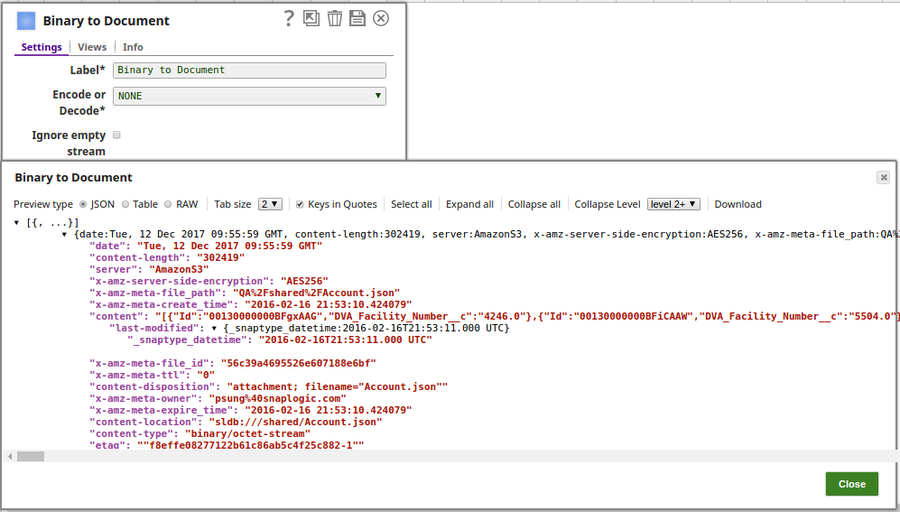
The output preview when NONE is selected:
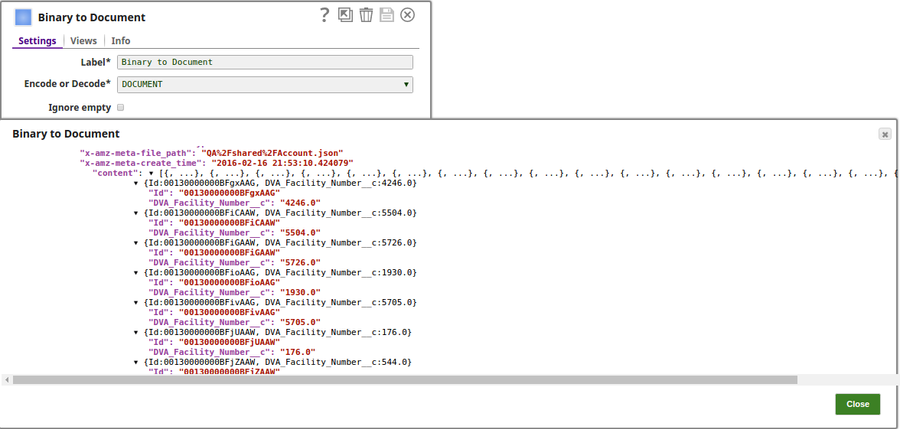
The output preview when DOCUMENT is selected:
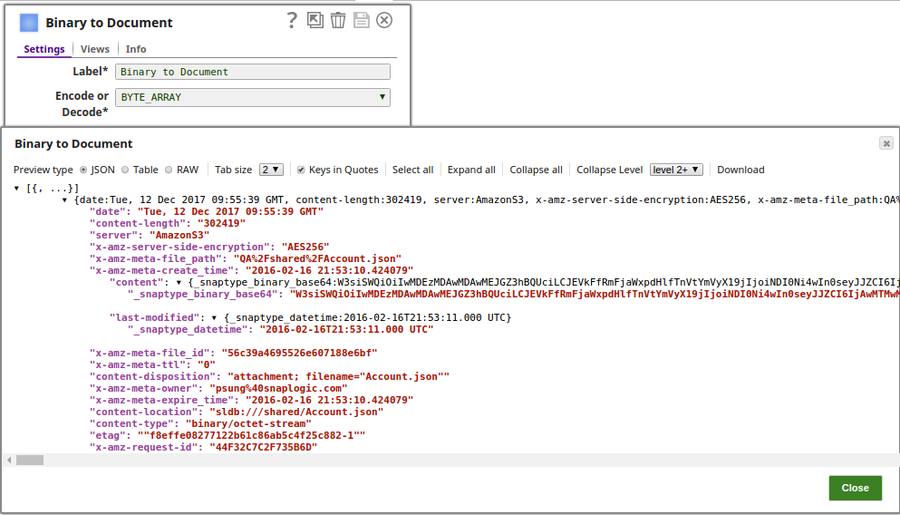
The output preview when BYTE_ARRAY is selected:
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|