In this article
| Table of Contents | ||||||||
|---|---|---|---|---|---|---|---|---|
|
Overview
You can use this Snap to transform incoming data using the given mappings and produce new output data. This Snap evaluates an expression and writes the result to the specified target path. If an expression fails to evaluate, use the Views tab to specify error handling.
...
Structural Transformations
The following structural transformations from the Structure Snap are supported in the Mapper Snap:
Move - A move is equivalent to a mapping without a pass-through. The source value is read from the input data and placed into the output data. As the Pass through is disabled, the input data is not copied to the output. Also, the source value is treated as an expression in the Mapper, but it is a JSONPath in the Structure Snap. A jsonPath() function was added to the expression language that can be used to execute a JSONPath on a given value. If Pass through is enabled, then you should delete the old value.
Delete - Write a JSONPath in the source column and leave the target column blank.
Update - All of the cases for update can be handled by writing the appropriate JSONPath. For example:
Update value:
target path = $last_nameUpdate map:
target = $address.first_nameUpdate list:
target = $names[(value.length)]The '(value.length)' evaluates to the current length of the array, so the new value will be placed there at the end.
Update list of maps:
target = $customers[*].first_nameThis translates into "write the value into the 'first_name' field in all elements of the 'customers' array".
Update list of lists:
target = $lists_of_lists[*][(value.length)]
...
For performance reasons, the Mapper does not make a copy of any arrays or objects written to the Target Path. If you write the same array or object to more than one target path and plan to modify the object, make the copy yourself. For example, given the array "$myarray" and the following mappings:
$myarray -> $MyArray$myarray -> $OtherArray
...
Any future changes made to either "$MyArray" or "$OtherArray" are in the both arrays. In that case, make a copy of the array as shown below:
$myarray -> $MyArray [].concat($myarray) -> $OtherArray
...
The same is true for objects, except you can make a copy using the ".extend()" method as shown below:
$myobject -> $MyObject $myobject.extend({}) -> $OtherObject
Passing Binary Data
You can convert binary data to document data by adding the Binary-to-Document Snap upstream of the Mapper Snap. Similarly, to convert the document output of the Mapper Snap to binary data, add the Document-to-Binary Snap downstream of the Mapper Snap.
You can also transform binary data to document data within the Mapper Snap itself by using the
$contentexpression.
Binary Input and Output
If you are only working with a binary stream as both input and output, you must set both source and target fields with
$content, then manipulate the binary data using the Expression Builder. If you do not specify this mapping, then the binary stream from the binary input document is passed through without any change.
Snap Type
Mapper Snap is a Transform-type Snap that transforms data and passes it to the downstream Snap.
Prerequisites
None.
Support for Ultra Pipelines
Works in Ultra Pipelines.
Limitation
Expressions used in this Snap, downstream of any Snowflake Snaps, that evaluate to very large values such as EXP(900) are displayed as Infinity in the input/output previews. However, you can see the exact evaluated values in the validation previews. Learn more: Java Script Limitations in Displaying Numbers.
Snap Views
...
Type
...
Format
...
Number of Views
...
Examples of Upstream and Downstream Snaps
...
Description
...
Input
Document
Binary
...
Min: 0
Max: 1
...
Binary-to-Document
...
This Snap can have a most one document or binary input view. If you do not specify an input view, the Snap generates a downstream flow of one row.
By default, this Snap has Document as Input Type. You can select Binary type if your input is in Binary format.
...
Output
Document
Binary
...
Min: 1
Max: 1
...
Any Document Snap
...
This Snap has exactly one document or binary output view.
By default, this Snap has Document as Output Type. You can select Binary type to view the output in Binary format.
...
Error
...
Error handling is a generic way to handle errors without losing data or failing the Snap execution. You can handle the errors that the Snap might encounter when running the Pipeline by choosing one of the following options from the When errors occur list under the Views tab. The available options are:
Stop Pipeline Execution: Stops the current pipeline execution when the Snap encounters an error.
Discard Error Data and Continue: Ignores the error, discards that record, and continues with the remaining records.
Route Error Data to Error View: Routes the error data to an error view without stopping the Snap execution.
Learn more about Error handling in Pipelines.
Snap Settings
...
Field Name
...
Field Type
...
Description
Label*
Default Value: Mapper
Example: Mapper
...
String
...
The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your Pipeline.
Null-safe access
Default Value: Deselected
Example: Selected
...
Checkbox
...
Select this checkbox to set the target value to null in case the source path does not exist. For example, $person.phonenumbers.pop() ->$ lastphonenumber may result in an error if person.phonenumbers does not exist in the source data. Selecting this checkbox allows the Snap to write null to lastphonenumber instead of displaying an error.
If you deselect this checkbox, the Snap fails if the source path does not exist, ignores the record entirely, or writes the record to the error view depending on the setting of the error view field.
Pass through
...
Checkbox
...
This setting determines if data should be passed through or not.
If you select this checkbox, then all the original input data is passed into the output document together with the data transformation results.
If you deselect this checkbox, then only the data transformation results that are defined in the mapping section appear in the output document and the input data is discarded.
| Note |
|---|
This setting is impacted by Mapping Root. If Mapping Root is set to |
When to always select Pass through
Always select Pass through if you plan to leave the Target path field blank; else, the Snap displays an error that the field that you want to delete does not exist. This is the expected behavior.
For example, you have an input file that contains a number of attributes; but you need only two of these downstream. So, you connect a Mapper to the downstream Snap supplying the input file, select the two attributes you need by listing them in the Expression fields, leave the Target path field blank, and select Pass through. When you execute the Pipeline, this Snap evaluates the input documents/binary data and picks up the two attributes that you want, and passes the entire document/binary data through to the Target schema. From the list of available attributes in the Target Schema, the Mapper Snap picks up the two attributes you listed in the Expression fields, and passes them as output. However, if you had not selected the Pass through checkbox, the Target Schema would be empty, and the Mapper would display a No schema available error.
Transformations*
...
Use this field set to configure the settings for data transformations.
Mapping Root
Default Value: $
Example: $
...
String/Suggestion
...
Specify the sub-section of the input data to be mapped. Learn More: Understanding the Mapping Root.
...
Input Schema
...
Dropdown list
...
Select the input data (that comes from the upstream Snap) that you want to transform. Drag the item you want to map and place it under the Mapping table.
...
Mapping table
...
Use this field set to specify the source path, expression, and target path columns used to map schema structure.
Expression
Default Value: N/A
Example: $first.concat(" ", $last)
...
String/Expression
...
The function to use to transform the data. For example, combine, concatenate or flatten. Expressions that are evaluated replace the source targets at the end of the Pipeline runtime.
| Note |
|---|
Incoming fields from previous Snaps that are not expressly defined in the Mapping Table are passed through the Data Snap to the next Snap. However, when defining output fields in the Target Path, if the field name is the same as a field name that would otherwise Pass through, the field in the mapping table overrides the output. |
Lear More: Understanding Expressions in SnapLogic and Using Expressions for usage guidelines.
| Info |
|---|
Managing Numeric Inputs in Mapper Expressions While working with upstream numeric data, you may see some unexpected behavior. For example, consider a mapping that reads as follows: Expression: For example, the value being passed from upstream for $num is 20.05. You would expect the value of $numnew to now be 120.05. But, when you execute the Snap, the value of $numnew is shown as 20.05100. This happens because, as of now, the Mapper Snap reads all incoming data as strings, unless they are expressly listed as integers (INT) or decimals (FLOAT). So, to ensure that the upstream numeric data is appropriately interpreted, parse the data as a float. This will convert the numeric data into a decimal; and all calculations performed on the upstream data in the Mapper Snap will work as expected: Expression: The value of $numnew is now shown as 120.05. |
Target path
Default Value: N/A
Example: $FirstName
...
String/Suggestion
...
The target JSON path where the value from the evaluated expression is written. For example, after evaluation of the $person.firstname expression the Snap inserts the firstname for the person object.
Target Path Recommendation
| Info |
|---|
Iris simplifies configuring the Target path property in this Snap by recommending suggestions for the Expression and Target path fields mapping. To make these suggestions, Iris analyzes Expression and Target path mappings in other Pipelines in your Org and suggests the exact matches for the Expressions in your current Pipeline. The suggestions are displayed upon clicking |
For example, you have the Expression $Emp.Emp_Personal.FirstName in one of your Pipelines. And you have set the Target path for this expression as $FirstName. Now, if you use the expression $Emp.Emp_Personal.FirstName in a new Pipeline, then Iris suggests $FirstName as one of the recommended Target paths. This helps you standardize the naming standards within your org.
The following video illustrates how Iris recommends Target path in a Mapper Snap:
...
Snap Execution
...
Dropdown list
...
Select one of the three modes in which the Snap executes. Available options are:
Validate & Execute: Performs limited execution of the Snap, and generates a data preview during Pipeline validation. Subsequently, performs full execution of the Snap (unlimited records) during Pipeline runtime.
Execute only: Performs full execution of the Snap during Pipeline execution without generating preview data.
Disabled: Disables the Snap and all Snaps that are downstream from it.
Mapping Table
The mapping table makes it easier to do the followingIn this article
| Table of Contents | ||||||||
|---|---|---|---|---|---|---|---|---|
|
Overview
Use this Snap to transform incoming data with the specific mappings and produce new output data (binary or document). The Mapper Snap evaluates an expression and writes the result to the target path. Use the Views tab to specify error handling if an expression fails to evaluate.
...
Pass Binary Data
To convert binary data to document data add the Binary-to-Document Snap upstream of the Mapper Snap. Similarly, add the Document-to-Binary Snap downstream of the Mapper Snap to convert the document output to binary data.
You can also transform binary data to document data in the Mapper Snap itself with the
$contentexpression.
Binary Input and Output
If you only work with a binary stream as both input and output, you must set both source and target fields with
$content, then use the Expression Builder to manipulate the binary data. If you do not specify this mapping, then the binary stream from the binary input document passes through with no change.
Snap Type
The Mapper Snap is a Transform-type Snap that transforms data and passes it to the downstream Snap.
Support for Ultra Pipelines
Works in Ultra Pipelines.
Limitations
The Mapper Snap does not support Base64URL decoding.
Expressions used in this Snap (downstream of any Snowflake Snaps) that evaluate to very large values such as
EXP(900)displays asInfinityin the input/output previews. However, the exact evaluated values are in the validation previews. Learn more: JavaScript Limitations in Displaying Numbers.
Snap Views
Type | Format | Number of Views | Examples of Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
Input |
|
| Binary-to-Document | This Snap can have at most one document or binary input view. If you do not specify an input view, the Snap generates a downstream flow of one row. By default, the Input type is Document. You can select Binary type if your input is in Binary format. |
Output |
|
| Any Document Snap | This Snap has exactly one document or binary output view. By default, the Output type is Document. You can select the Binary type to view the output in the Binary format. |
Error | Error handling is a generic way to handle errors without data loss or Snap execution failure. You can handle the errors that the Snap might encounter when running the pipeline with one of the following options from the When errors occur list under the Views tab. The available options are:
Learn more about Error handling in Pipelines. | |||
Snap Settings
| Info |
|---|
|
Field Name | Field Type | Description | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
Label* Default Value: Mapper | String | The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | ||||||||
Null-safe access Default Value: Deselected | Checkbox | Select this checkbox to set the target value to null if the source path does not exist. For example, | ||||||||
Pass through Default Value:Deselected | Checkbox | Select this checkbox so the Snap passes all the original input data into the output document with the data transformation results. If you deselect this checkbox, only the data transformation results in the mapping section appear in the output document and the input data is discarded.
| ||||||||
Transformations* | Use this field set to configure the settings for data transformations. | |||||||||
Mapping Root Default Value: $ | String/Suggestion | Specify the subsection of the input data to map. Learn more: Understand the Mapping Root. | ||||||||
Input Schema | Dropdown list | Select the input data (from the upstream Snap) that you want to transform. Drag the item you want to map and place it under the Mapping table. | ||||||||
Sorted Default Value: Selected | Checkbox | Select this checkbox to sort the input schema and the target schema. The sort options are:
| ||||||||
Mapping table* | Use this field set to specify the source path, expression, and target path columns used to map schema structure. The mapping table makes it easier to:
Learn | |||||||||
...
more: |
...
...
Input and Output Preview
The Input Schema of the Mapper Snap displays the input strings from the upstream Snap. On validation, the Input Preview displays the preview of the input from the upstream Snap, and the Output Preview displays the preview of the output to be passed to the downstream Snap. The following elements are available in the Input and Output Previews.
...
Callout Number
...
Elements
...
Description
...
1
...
Expand All
...
Expands the objects in the Input/Output.
...
2
...
Collapse All
...
Collapses the objects in the Input/Output.
...
3
...
Collapse Level
...
Collapses the level of objects from 0-2 or All.
...
4
...
Render whitespace
...
When you select this checkbox, the blank spaces (leading, trailing, or in the middle of a string) in an expression field are rendered as symbols in the output.
Each blank space is rendered as a dot (“.”) in the output.
Each tab is rendered as an under score ( _ ) in the output.
When you deselect this checkbox, the Snap renders blank spaces and tabs as-is. By default, the Render whitespace checkbox is selected.
...
5
...
Download
...
Downloads the JSON file.
Examples
Removing Columns from Excel Files Using Mapper
In this example, you read an Excel file from the SLDB and remove columns that you do not need from the file. You then write the updated data back into the SLDB as a JSON file.
...
Add a File Reader Snap to the Canvas and configure it to read the Excel file from which you want to remove specific columns.
...
Parse the file using the Excel Parser Snap. You can preview the parsed data by clicking the ![]() icon.
icon.
...
From the preview file, you can see the columns that you want to remove. In this instance, you decide to remove the Discounts and Month Number columns. To do so, you add a Mapper Snap to the Pipeline.
...
In the Expression field, you enter the criteria (as shown below) that you want to use to remove the Discounts and Month Name columns.
...
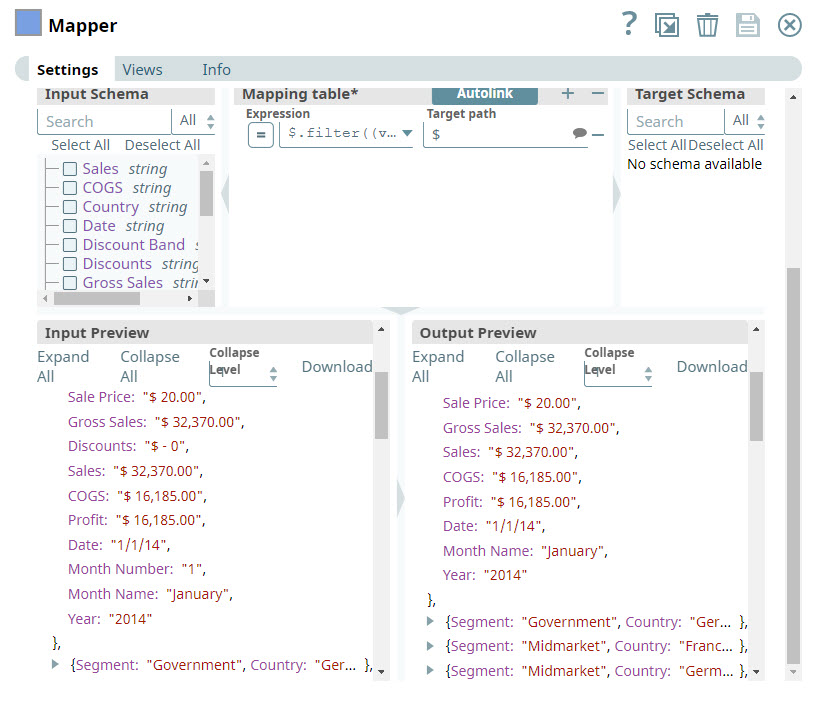
...
$.filter((value, key) => !key.match("Discounts|Month Number"))
Enter $ in the Target field to indicate that you want to leave the other column names unchanged. Validate the Snap, you can see that the Discounts and Month Name columns are skipped.
...
You now need to write the updated data back into the SLDB as a JSON file. Add a JSON Formatter Snap to the Pipeline to convert the documents coming in from the Mapper Snap into binary data. Then add a File Writer Snap and configure it to write the input streaming data to the SLDB. You can now view the saved file in the destination project in SnapLogic Manager.
...
Data Output Example
...
Successful Mapping
...
If your source data looks like
...
And your mapping looks like
...
Your outgoing data will look like
...
| Code Block |
|---|
{
"first_name": "John",
"last_name": "Smith",
"phone_num": "123-456-7890"
} |
...
Expression:
$first_name.concat(" ", $last_name)Target path:
$full_name
| Code Block |
|---|
{
"full_name": "John Smith",
"phone_num": "123-456-7890"
} |
...
Unsuccessful Mapping
...
| Code Block |
|---|
{
"first_name": "John",
"last_name": "Smith",
"phone_num": "123-456-7890"
} |
...
Expression:
$middle_name.concat(" ", $last_name)Target path:
$full_name
...
An error is displayed.
Escaping Special Characters in Source Data
This example demonstrates how you can use the Mapper Snap to customize source data containing special characters so that it is correctly read and interpreted by downstream Snaps.
...
...
Add custom JSON data in the JSON Generator Snap, wherein the values of field1 and field10 include the special character (').
...
The output preview of the JSON Generator Snap displays the special character correctly:
...
Before sending this data to downstream Snaps, you may need to prefix the special characters with an escape character so that downstream Snaps correctly interpret these. You can do this using the Expression field in the Mapper Snap. Based on the accepted escape characters in the endpoint, you can select from the following expressions:
...
If the Escape Character is
...
Use Expression
...
Sample Output
...
Single quote (')
...
JSON:
$original.mapValues((value,key)=> value.toString().replaceAll("'","''"))
OR
$original.mapValues((value,key)=> value.toString().replaceAll("'","\''"))
CSV:
$[' Business-Name'].replace ("'","''")
...
Ampersand (&)
...
JSON:
$original.mapValues((value,key)=> value.toString().replaceAll("'","\&'"))
OR
$original.mapValues((value,key)=> value.toString().replaceAll("'","&'"))
CSV:
$[' Business-Name'].replace ("'","&'")
...
Backslash (\)
...
JSON:
$original.mapValues((value,key)=> value.toString().replaceAll("'","\\'"))
| Info |
|---|
Backslash is configured as an escape character in SnapLogic. Therefore, it must itself be escaped to be displayed as text. |
CSV:
$[' Business-Name'].replace ("'","\\'")
...
In this way, you can customize the data to be passed on to downstream Snaps using the Expression field in the Mapper Snap.
Refer to the Community discussion for more information.
See it in Action
...
Expression* Default Value: N/A | String/Expression | Specify the function to use to transform the data. For example, combine, concatenate, or flatten. Expressions that are evaluated replace the source targets at the end of the pipeline runtime.
Learn More: Understand Expressions in SnapLogic and Use Expressions for usage guidelines.
| |||||||
Target path Default Value: N/A | String/Suggestion | Specify the target JSON path where the value from the evaluated expression is written. For example, after evaluation of the Target Path Recommendation
For example, you have the Expression $Emp.Emp_Personal.FirstName in one of your pipelines. You set the Target path for this expression as $FirstName. Now, if you use the expression $Emp.Emp_Personal.FirstName in a new pipeline, then Iris recommends $FirstName as one of the Target paths to help you standardize the naming standards in your org. The following shows how Iris recommends the Target path in a Mapper Snap: 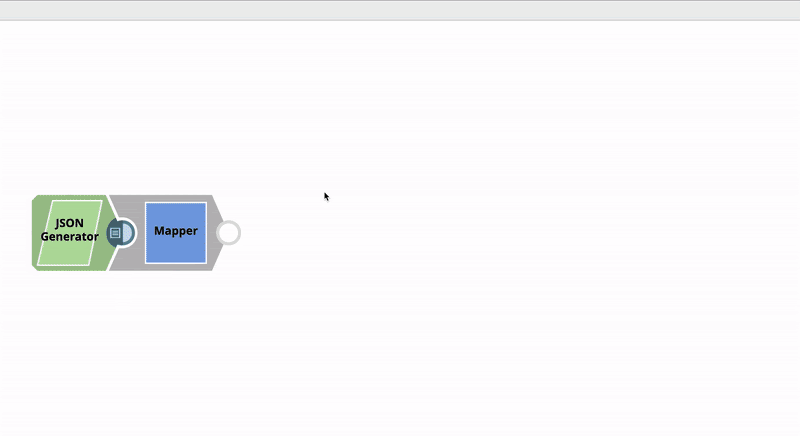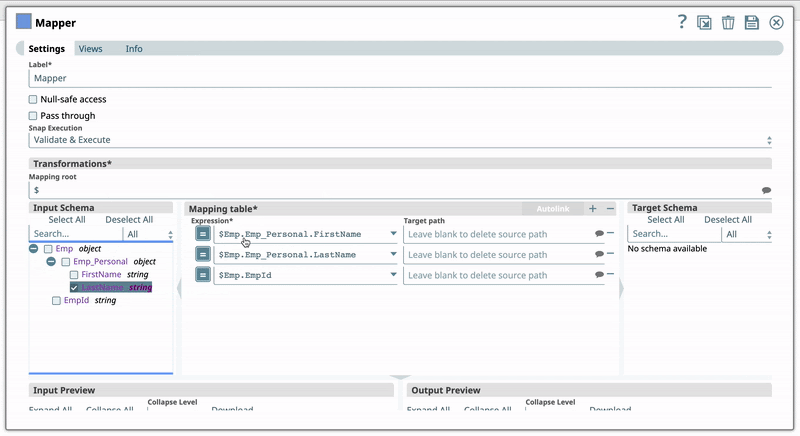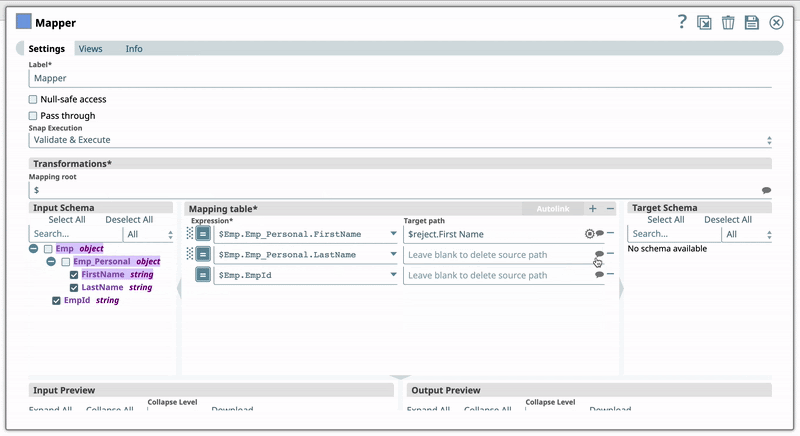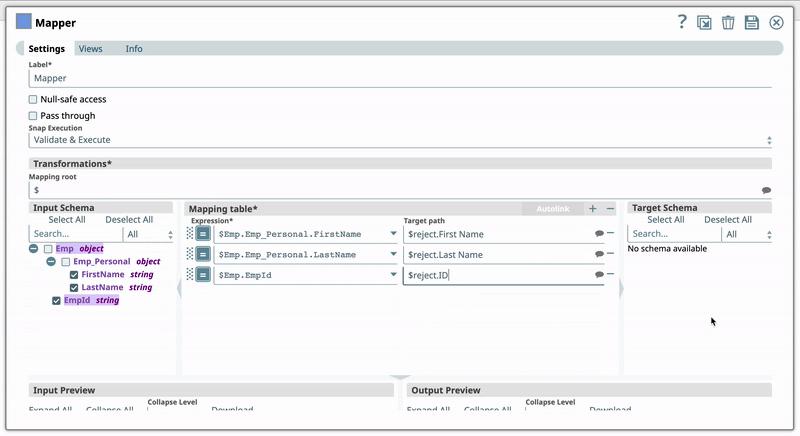 | |||||||
Snap Execution | Dropdown list | Select one of the three modes in which the Snap executes. Available options are:
| |||||||
|---|---|---|---|---|---|---|---|---|---|
Input and Output Preview
The Input Schema of the Mapper Snap displays the input strings from the upstream Snap. On validation, the Input Preview displays the preview of the input from the upstream Snap, and the Output Preview displays the output preview that passes to the downstream Snap. The following elements are available in the input and output previews:
...
Number | Element | Description |
|---|---|---|
1 | Expand All | Expands the objects in the Input/Output. |
2 | Collapse All | Collapses the objects in the Input/Output. |
3 | Render whitespace | When you select this checkbox, the blank spaces (leading, trailing, or in the middle of a string) in an expression field renders as symbols in the output:
When you deselect this checkbox, the Snap renders blank spaces and tabs as-is. By default, the Render whitespace checkbox is selected. |
4 | Download | Downloads the JSON file. |
Data Output Example
Successful Mapping | ||||||
|---|---|---|---|---|---|---|
If your source data looks like | And your mapping looks like | Your output data will look like | ||||
|
|
| ||||
Unsuccessful Mapping | ||||||
|
| An error displays. | ||||
Mapper Examples
...
Watch the Data Mapper in Action
The Data Mapper
| Widget Connector | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
...
Best Practices: Data Transformations and Mappings
| Widget Connector | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
...
| Attachments | ||
|---|---|---|
|
...
Related
...
Content
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|
...