...
Before the
4.33patches21119release, empty strings and null values were treated as null when loaded into the SQL server. However, starting from the433patches21119release, data in the format of an empty string inserted into a string-based column is stored as an empty string in the SQL server. Similarly, inserting null data into a string-based column is stored as null in the SQL server.
To ensure consistent handling of both empty strings and null values, we recommend you to update the data to match how you would like it to be represented in the database before performing a bulk load operation.
...
Known Issues
The SQL Server - Bulk Load Snap returns 0 rows copied for tables containing spatial-type columns.
Limitations
None.
Snap Views
Type | Format | Number of Views | Examples of Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
Input | Document |
|
| By default, this Snap has one document input view by default. A second view can be added for metadata for the table as a document so that the target absent table can be created in the database with a similar schema as the source table. This schema is usually from the second output of a database Select Snap. If the schema is from a different database, there is no guarantee that all the data types would be properly handled. The target table's columns need to be mapped upstream using a Mapper Snap. The Mapper Snap will provide the target schema, which reflects the target table's schema. Learn more: SQL Server - Bulk Load | Table Creation |
Output | Document |
|
| A document that represents the result of the bulk load operation. |
Error | Error handling is a generic way to handle errors without losing data or failing the Snap execution. You can handle the errors that the Snap might encounter when running the Pipeline by choosing one of the following options from the When errors occur list under the Views tab:
Learn more about Error handling in Pipelines. | |||
Snap Settings
| Info |
|---|
|
Field Name | Field Type | Description | ||
|---|---|---|---|---|
Label* Default Value: Snowflake - Bulk Load | String | Specify a unique name for the Snap. | ||
Schema Name Default Value: N/A | String/Expression/Suggestion | Specify the database schema name. In case it is not defined, then the suggestion for the Table Name will retrieve all tables names of all schemas. The property is suggestible and will retrieve available database schemas during suggest values. You can pass the values using the pipeline parameters but not the upstream parameter. | ||
Table Name* Default Value: N/A | String/Expression/Suggestion | Specify the table on which to execute the bulk load operation.
Examples: Supported by BCP: "dbo"."sqldemo#^&$%" Not supported by BCP: "dbo"."sqldemo#^&%$" | ||
Create table if not present Default Value: Deselected | Checkbox | Select this checkbox to enable the Snap to automatically create a table if a table does not exist. The data types for the columns in the new table depend on the data types from the upstream Snap. If a second input view exists, the Snap reads and uses the data types for the columns from this input view. Learn more: SQL Server - Bulk Load | Table Creation | ||
BCP absolute path Default Value: N/A | String | Specify the absolute path of the bcp utility program in JCC's file system. If empty, the Snap looks for it in JCC's environment variable PATH. bcp.bat should include the ".exe" extension to ensure the executable is actually referenced. Handling Unrecognized Character sets in the Data set. As the Snaplex uses the OS's default character set, it cannot recognize characters in other languages. Due to this, unrecognized characters in the data set are replaced with junk values when performing bulk load operations. To mitigate this, create a bcp.bat file and include the following line:
Use the path to this bcp.bat file in the BCP absolute path. This is only applicable to Windows-based Snaplexes. | ||
Maximum error count* Default Value: 10 | Integer | Specify the maximum number of rows which can fail before the bulk load operation is stopped. | ||
Batch size Default Value: N/A | Integer/Expression | Specify the number of records batched per request. If the input has 10,000 records and the batch size is set to 100, the total number of requests batched would be 100. Minimum Value: 1 | ||
Snap Execution Default Value: Execute only | Dropdown list | Select one of the three modes in which the Snap executes. Available options are:
|
If the Auto commit option is enabled for an account and a downstream Snap relies on data processed by an upstream Database Bulk Load Snap, it may be necessary to introduce a delay to ensure the data is available. In such scenarios, you can use the Script Snap to add a delay between the processing steps. For instance, when performing sequential create, insert, and delete operations in a pipeline, using a Script Snap allows you to introduce a delay between the insert and delete functions. Without this delay, it is possible that the delete function could be triggered before the records are inserted into the table.
...
Table Creation
When attempting to load data, if the specified table does not exist and the Create table if not present checkbox is selected, the Snap creates the table along with the necessary columns and data types to accommodate the values in the first input document. If you want the table to have the same structure as a source table, you can connect the second output view of a Select Snap to the second input view of this Snap. The additional view in the Select and Bulk Load Snaps transmits metadata about the table, enabling the replication of a table from one database to another.
...
| Info |
|---|
The Snap will not automatically fix some errors encountered during table creation since they may require user intervention to resolve correctly. For example, if the source table contains a column with a type without direct mapping in the target database, the Snap fails to execute. You will then need to add a Mapper (Data) Snap to change the metadata document to explicitly set the values needed to produce a valid CREATE TABLE statement. SQL Server BCP program only accepts date time values in format YYYY-MM-dd HH:mm: ss, thus SQL Server Bulk Load Snap only accepts two types of data as the input of a DATETIME column:
SQL Server Bulk Load Snap does not accept the results by the DateTime string from the expression Date.toLocaleDateTimeString(). |
Troubleshooting
Error | Reason | Resolution | ||||
|---|---|---|---|---|---|---|
Some characters appear as junk values after bulk load. | The Snaplex uses character sets defined in the OS on which they are installed. Due to this, any unrecognized character set is not supported by the Snaplex as well. As a result, such characters in the data set are represented as junk values in the database after a bulk load operation. | This problem can be resolved by editing the bcp.bat file to accept custom characters. And using the absolute path to this bcp file in the BCP absolute path property. The bcp.bat file must contain the following:
|
Example
This example pipeline demonstrates how to load data from table bulk_test_source to table bulk_test_target with SQL Server Bulk Load Snap.
...
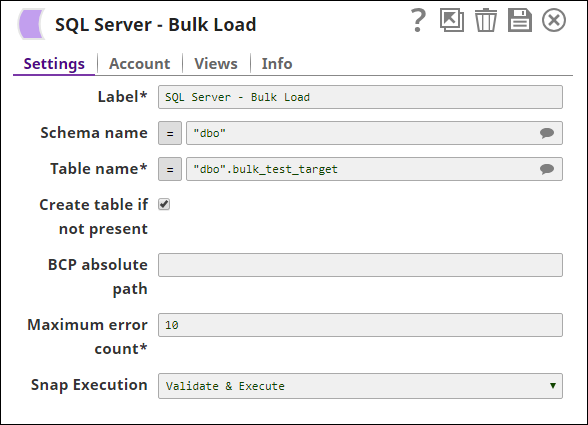
Step 2: Configure the SQL Server Bulk Load Snap as follows to load inputs to the table bulk_test_target. On successful validation, the SQL Server Bulk Load Snap output displays the result of the tables copied.
 | .png?version=1&modificationDate=1489654859797&cacheVersion=1&api=v2) |
Snap Pack History
| Expand | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
...
Related Content
...