SnapLogic’s ELT Snap Pack is a full pushdown optimization (FPDO) solution that extracts, loads, and transform (ELT) data in the target database by building ELT Pipelines that parse SQL queries. As such, the ELT Pipeline generates and executes SQL on the target database. ELT Snaps help you to make data available to the enterprise in quick time; eliminating delays in transforming data for your specific purpose.
Extract data from the source system (SaaS application)
Load it into your Data Warehouse in its raw format
Transform the data using the power of the cloud
Automating Data Integration with ELT
Articles in this section
Panel
bgColor
#ebf7e1
Child pages (Children Display)
Features
Ease of Use
SQL passed between Snaps; execution on CDW (cloud data warehouse)
Visually build SQL Pipelines
Selectively Preview Data
Suggest capability
Extensive transformation capabilities
Load data using merge into
Enhanced Connectivity
Independent Snap Pack
Accounts specific to each target database.
Security
Prevent SQL Injection
Write transformed data to target databases hosted in the following cloud locations:
AWS (For Snowflake, Redshift, and Databricks Lakehouse Platform (DLP))
Microsoft Azure (For Snowflake, Azure Synapse, and Databricks Lakehouse Platform (DLP))
You can configure your ELT Database Account to automatically use an appropriate JDBC JAR file for connecting to your target CDW and performing the load and transform operations.
We recommend you to let the ELT Snaps use the listed JAR file versions. However, you may use a different JAR file version of your choice.
Known Issues
When your Databricks Lakehouse Platform instance uses Databricks Runtime Version 8.4 or lower, ELT operations involving large amounts of data might fail due to the smaller memory capacity of 536870912 bytes (512MB) allocated by default. This issue does not occur if you are using Databricks Runtime Version 9.0.
In case of Databricks Lakehouse Platform (DLP), when you specify a CSV file to load data from and select the Load Action as Alter Table in the ELT Load Snap, the Snap fails with the error Database encountered an error during Bulk Load process.
When you configure an ELT Merge Into Snap to perform an Update or Delete operation or an ELT Execute Snap with a MERGE INTO statement that performs Update or Delete operation on a Databricks Lakehouse Platform cluster, it may return an error if multiple source rows attempt to update or delete the same target row. To prevent such errors, you need to preprocess the source table to have only unique rows.
DO NOT use regular JavaScript expressions (supported in the Standard-mode Snaps and not in the above list).
DO NOT prefix variable names with $ symbol.
The Help icon that leads to the SnapLogic documentation site is disabled by default for unsaved Snaps. Save the Snap to enable the Help icon.
The Snaps - ELT Load, ELT Merge-Into, ELT Insert-Select and ELT Select, display the Schema Name field suggestions from all databases that the Snap account user can access, instead of the database selected in the Snap account or the Snap Settings.
ELT Transform Snap displays incorrect data types (string instead of the actual data type) for column names populated in its Input schema section.
Multiexcerpt macro
name
ME_ELT_KI_Underscore_Refs
ELT Pipelines targeting a Databricks Lakehouse Platform (DLP) instance might fail due to a very long or complex SQL query that they build. As a workaround, you can set an advanced (URL) property useNativeQuery to 1 in your ELT Database Account configuration as shown below:
In any of the supported target databases, this Snap does not appropriately identify nor render column references beginning with an _ (underscore) inside SQL queries/statements that use the following constructs and contexts (the Snap works as expected in all other scenarios):
WHERE clause (ELT Filter Snap)
WHEN clause
ON condition (ELT Join, ELT Merge Into Snaps)
HAVING clause
QUALIFY clause
Insert expressions (column names and values in ELT Insert Select, ELT Load, and ELT Merge Into Snaps)
Update expressions list (column names and values in ELT Merge Into Snap)
Secondary AND condition
Inside SQL query editor (ELT Select and ELT Execute Snaps)
Workaround
As a workaround while using these SQL query constructs, you can:
Precede this Snap with an ELT Transform Snap to re-map the '_' column references to suitable column names (that do not begin with an _ ) and reference the new column names in the next Snap, as needed.
In case of Databricks Lakehouse Platform where CSV files do not have a header (column names), a simple query like SELECT * FROM CSV.`/mnt/csv1.csv` returns default names such as _c0, _c1, _c2 for the columns which this Snap cannot interpret. To avoid this scenario, you can:
Write the data in the CSV file to a DLP table beforehand, as in: CREATE TABLE csvdatatable (a1 int, b1 int,…) USING CSV `/mnt/csv1.csv` where a1, b1, and so on are the new column names.
Then, read the data from this new table (with column names a1, b1, and so on) using a simple SELECT statement.
In case of Databricks Lakehouse Platform, all ELT Snaps' preview data (during validation) contains a value with precision higher than that of the actual floating point value (float data type) stored in the Delta. For example, 24.123404659344 instead of 24.1234. However, the Snap reflects the exact values during Pipeline executions.
failed to get the right data type due to column name case mismatches between what is used in the Snap and what is actually used in the Azure Synapse tables (returned by the JDBC driver).
Now, you need not worry about typing
You no longer need to type the column names in the exact case that Azure Synapse expects.
That fails
The Snap failed with the
error
error—start_date does not
exist
exist—while writing SCD2 data to
Redshift tables based on the start and end dates for the current rows and the invalid historical row flag
a Redshift table column start_date that is specified as the StartDate of Current Rowin the Target Table Temporal Field(s) field set.
While loading data into DLP tables using more than one WHEN MATCHED condition (MERGE INTO WHEN MATCHED… AND… construct) by aliasing each of the target table column names in the SQL statement generated.
Where it fails
The Snap failed with the error—Reference 'END_DATE' is ambiguous—while merging SCD2 updates into DLP tables.
Where the Snap failed due to lack of required access privileges on the target database (for example, create table rights to create temporary tables as needed). The Snap now runs the input SQL statement and the elaborate sub-queries instead of attempting to create a temporary table in such scenarios.
alter Redshift target tables—add and drop more than one column using a single SQL statement
perform an add/drop operation involving multiple columns on a Redshift target table.
4.27
main12833
Stable
Enhanced the ELT Aggregate Snap to support COUNT_IF aggregate function for Redshift and Azure Synapse target databases. Eliminating duplicates with COUNT_IF aggregate function Note: Selecting the Eliminate Duplicates checkbox while using COUNT_IF aggregate function does not eliminate duplicate records in case of Snowflake and BigQuery databases, as there is no native support for this feature. However, for Redshift, Azure Synapse and Databricks Lakehouse Platform (DLP), the duplicates are eliminated from the list of records when you select this checkbox for COUNT_IF function.
Updated the Expressions and Functions Supported for ELT in the Snap and Account configuration sections. This list is common to all target CDWs supported. You can use these expressions to define your Snap or Account settings with the Expression symbol = enabled, where available.
Enhanced the ELT Load Snap to ensure that the Snap uses the default S3 Folder name specified in the Snap's account to accurately resolve the defined File Name Pattern.
Enhanced the ELT Select and ELT Execute Snaps to allow SQL comments inside the SQL Query Editor and SQL Statement Editor fields respectively.
Enhanced the ELT Transform Snap to display the exact data types of fields listed in the Input Schema and Target Schema in case of Azure Synapse.
Enhanced the ELT Merge Into Snap to to support MERGE INTO ALL option and automatic source table aliasing.
Enhanced the ELT Load Snap by adding the Source File to Target Table Columns Map field set to enable mapping of columns between the source file and the target table. In case of Databricks Lakehouse Platform (DLP) the Snap is enhanced further to support delimiters other than the comma in the source CSV files.
Enhanced the ELT Join Snap to support Left Anti and Left Semi join types in BigQuery though it does not natively support these join types.
Enhanced the underlying load mechanism for ELT SCD2 Snap from Insert-and-Update mode to Merge-into mode to substantially improve the Snap's performance while working with large and very large volumes of data (upwards of 500M rows or 50GB size).
4.26-Patch
426patches12534
Latest
Fixed an issue withELT TransformSnap where it may display incorrect schema only in the previews (during Pipeline validation). This occurs especially when the incoming SQL statement (defined in theSQL Statement Editorof the upstream Snap) contains one or more of the WHERE, GROUP BY, HAVING , ORDER BY, LIMIT, LIMIT followed by OFFSET, and SAMPLE clauses. Here are a few Pipeline scenarios where this issue might surface:
… >ELT Select(with one or more of these clauses used in the SQL Statement Editor) >ELT Transform> …
Fixed an issue where the ELT Load Snap connecting to a Databricks Lakehouse Platform (DLP) instance failed to perform the load operation. Ensure that you provide a valid DBFS Folder path in the Snap's account settings as the Snap requires this folder path.
4.26-Patch
426patches11646
Latest
Enhanced the ELT Database Account to support token-based authentication (Source Location Session Credentials) to S3 locations for Snowflake and Redshift target databases.
Enhanced the ELT Aggregate Snap with the following changes:
Revised the field labels from:
GROUP BY Fields Listfield set > Output Field to GROUP BY Field.
ORDER-By Fields to ORDER-BY Fields (Aggregate Concatenation Functions Only).
Removed the Suggestion option for Field Name field under General Aggregate Functions List field.
Made the Alias Name fields in the Aggregate Concatenation Functions List and the Percentile Distribution Functions List field sets mandatory.
If your target database is a Databricks Lakehouse Platform (DLP) instance, then the ELT Load Snap supports loading data from source CSV files that contain only comma as the separator between values.
4.26-Patch
426patches11323
Latest
Enhanced the ELT Database Account to allow parameterization of field values using Pipeline Parameters. You can define and use these parameters in expression-enabled fields to pass values during runtime.
4.26-Patch
426patches11262
Latest
Fixed the following Known Issues recorded in the 4.26 GA version:
For a Snowflake target instance, the ELT Insert Select Snap does not suggest column names to select for the Insert Column field in the Insert Expression List.
The Snaps—ELT Merge Into, ELT Select, ELT Join, and ELT Filter—do not prevent the risk of SQL injection when your target database is Databricks Lakehouse Platform (DLP).
Intermittent null-pointer exceptions in the ELT Load Snap on Databricks Lakehouse Platform (DLP).
The ELT Insert Select Snap attempts to create the target table even when it exists in the Snowflake database.
When loading data from a JSON file into a target Databricks Lakehouse Platform (DLP) instance using an ELT Load Snap, if you choose the Drop and Create Table option as the Load Action and specify an additional column (that is not available in the JSON file) for the new table, it results in one more column null added to the new target table.
When you use the SQL editor in the ELT Select Snap configuration to define your SQL query, the Pipeline validation fails due to a syntax error in the following scenarios. However, the Pipeline execution works as expected. The only workaround is to drop the LIMIT clause and the optional OFFSET clause from the SQL query during Pipeline validation.
The query contains a LIMIT clause on a Snowflake, Redshift or Databricks Lakehouse Platform target instance: The SQL query created during Pipeline validation includes an additional LIMIT clause, for example: SELECT * FROM "STORE_DATA"."ORDERS" LIMIT 10 LIMIT 990.
The query contains an OFFSET clause (supported in case of Snowflake and Redshift): The SQL query created during Pipeline validation looks like SELECT * FROM "STORE_DATA"."ORDERS" LIMIT 10 OFFSET 4 LIMIT 990.
4.26
main11181
Stable
Enhanced the ELT Snap preview to support the following Snowflake data types:array,object,variant, andtimestamp.
The Snaps convert the values to hexadecimal (HEX) equivalents—the default setting for the session parameter BINARY_OUTPUT_FORMAT in Snowflake. SeeSession Parameters for Binary Valuesfor more information.
If this setting is different from hexadecimal (such as base64) in the Snowflake table, the Snaps still convert the values to hexadecimal equivalents for rendering them in the Snap preview.
Enhanced all ELT Snaps to display the Get preview datacheckbox below the Snap'sLabelfield.
Starting with the 4.26 release, all Snaps in the ELT Snap Pack(except the ELT Copy Snap) require an account to connect to the respective target database. Your existing Pipelines that do not use an account may fail. We recommend you to associate an ELT Database Account to each of the ELT Snaps (except ELT Copy Snap) for your Pipelines.
Enhanced theELT AggregateSnap to support Linear Regression functions on Redshift and Azure Synapse. The Snap also supports these functions on Databricks Lakehouse Platform.
Enhanced theELT ExecuteSnapto enable running multiple DML, DDL, and DCL SQLstatements from the same Snap instance.
Support LEFT ANTI JOIN and LEFT SEMI JOIN types on all supported databases.
Display or hide the Resultant Column Names Prefix Typefield based on the target database selected in the Snap's account.
Enhanced the ELT Load and ELT SCD2 Snaps to provide a list of suggested data types, while adding columns to or creating a table.
4.25-Patch
425patches10017
Latest
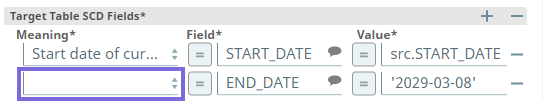
Updated the ELT SCD2 Snap to replace End date of historical row option in the Meaning field of Target Table SCD2 Fields field set with End Date of Current Row.
Warning
title
Breaking change
This may cause the existing Pipelines to fail as the End date of historical row option no longer exists.
You need to make the following update in the ELT SCD2 Snap's settings across your Pipelines after upgrading your Snap Pack to this patch:
Select End Date of Current Row from the Meaning drop-down list in the second entry (highlighted in the image).
Fixed the issue with the ELT Insert SelectSnap containing an open output preview that fails to retrieve output preview data in case of Redshift and Azure Synapse databases, though the Pipeline runs work as expected.
Fixed an issue where the ELT Execute Snap does not error out (Snap turns Green) even when running an SQL query to drop a non-existent table from a Snowflake or Azure Synapse database.
[Update on ]: Enhanced the ELT Snap previews to support the following data types: array, object, variant, and timestamp.
The Snaps convert the values to hexadecimal (HEX) equivalents—the default setting for the session parameter BINARY_OUTPUT_FORMAT in Snowflake. See Session Parameters for Binary Values for more information.
If this setting is different from hexadecimal (such as base64) in the Snowflake table, the Snaps still convert the values to hexadecimal equivalents for rendering them in the Snap previews.
4.25-Patch
425patches9725
Latest
Enhanced the ELT Snap preview to display the exact binary and varbinary values from Snowflake database during Pipeline validation, by converting the values to hexadecimalequivalents—the default setting in Snowflake. If the setting is different from hexadecimal in the Snowflake table, then the Snaps still convert the values to hexadecimal for rendering the Snap preview.
Enhanced theELT TransformSnap to display the appropriate data type (binaryorvarbinary) for the column names populated in the output schema.
Enhanced theELT Window FunctionsSnap to address potential issues due to an incorrect definition for MINUS function in case of Redshift and Azure Synapse databases.
4.25
main9554
Stable
Startingwith the 4.25 release, SnapLogic has now certified the ELT Snap Packto work withSnowflake hosted on Google Cloud Platform (GCP)as the target database, in addition to the other flavors ofSnowflake hosted on AWS and Microsoft Azure.
Introduced theELT ExecuteSnapto enable you to run DML, DDL, and DCL SQL queries in Snowflake in Snowflake, Redshift, andAzure Synapse.
Introduced theELT SCD2Snap to support Type 2 Slowly Changing Dimensions (SCD2) updates to the target databases—Snowflake, Redshift, andAzure Synapse.
Support for Google Cloud Storage as a storage location (source)in addition to AWS S3 and Azure Data Lake Storage (ADLS) when your target database is Snowflake.
Automatic downloadof the JDBC driver required for the selectedDatabase Type using the new Download JDBC Driver Automaticallycheck box.
Enhanced theELT LoadSnap to prevent changes to existing tablesduring Pipeline validation.If you set the Load Action as Drop and Create table, and the target table does not exist,the Snap creates a new (empty) target table based on the schema specified in its settings.
Enhanced theELT Window FunctionsSnap to support Covariance, Correlation, and LinearRegression Functions on Snowflake, Redshift, and Azure Synapse databases. The Snap uses function-specific query re-writes to support these functions on Redshift and Azure Synapse databases.
Enhanced theELT Merge IntoandELT Insert SelectSnaps to support up to one output view, and addedtheGet Preview Datacheck box to these Snaps. You can now connectdownstreamELT Snaps to these Snaps.
4.24-Patch
424patches8793
Latest
Fixes the issue of production job failures due to ELT Insert Select Snap after upgrading to 4.24 GA by updating the ELT Transform Snap to continue allowing duplication of fields in the Expression list for the Pipeline to complete successfully.
Note
No changes are needed to your existing Pipelines.
Fixes the column name collision issue in the Snap's output when the two tables being joined have columns with the same/identical names. You can specify the extent of prefix (that is, to prefix all columns, only duplicate columns, or no prefix) using the Resultant Column Names Prefix Type drop-down list. Based on the prefix you choose, a table alias name is prefixed to the identical columns in the output.
Note
title
Behavior Change
The behavior of ELT Load Snap for Load Action during Pipeline validation across the supported databases is as follows:
Append rows to existing table: Does not append the data from the source files into the target table.
Overwrite existing table: Does not overwrite the data.
Drop and Create table: Does not drop the target table even if it exists, but the Snap creates a new target table if a table does not exist.
Alter table: Does not modify the schema of the target table.
4.24
main8556
Stable
Adds support for Azure Synapsedatabase. You can now use theELT Snap Packto transform tables in the Snowflake, Redshift as well as Azure Synapse databases.
Updates the Snap Pack with the following features:
ELT Database Account: Enhances the ELT Database Account to support the Azure Synapse database.
Suggest appropriate column names to select from, in the Snap fields.
Create Hash-distributed tables using the Target Table Hash Distribution Column (Azure Synapse Only) field when theLoad Actionis selected asDrop and Create tableand a condition like WHEN NOT MATCHED BY TARGET.
Enhances the Snap to support Natural JOINS (NATURAL INNER JOIN, NATURAL LEFT OUTER JOIN, NATURAL RIGHT OUTER JOIN, and NATURAL FULL OUTER JOIN) in addition to the INNER, LEFT OUTER, RIGHT OUTER, FULL OUTER, and CROSS Joins in Azure Synapse Database. This enhancement also makes account configuration mandatory when using this Snap.
Fixes the column name collision issue in the Snap's result set when the two tables being joined have columns with the same/identical names. You can specify the Resultant Column Names Prefix Type drop-down list. Based on theprefix typeyou choose, a table alias name is prefixed to identical columns in the output.
Support theFile Name Patternoption using Key Based Mechanism for Redshift database.
Suggest appropriate column names to select from, in the Snap fields. This applies to Snowflake, Redshift, and Azure Synapse databases.
Create Hash-distributed tables using the Target Table Hash Distribution Column (Azure Synapse Only) field when theLoad Actionis selected asDrop and Create table.
Suggest appropriate column names to select from, in the Snap fields. This applies to Snowflake, Redshift, and Azure Synapse databases.
Include theTarget Table Hash Distribution Column (Azure Synapse Only) field for the Snap to create hash-distributed tables always.
Include theUpdate Expression List - When Not Matched By Source field set to allow defining one or more Update Expressions for the WHEN clause - WHEN NOT MATCHED BY SOURCE. This applies toAzure Synapse database.
Include theTarget Table Aliasfield to specify the alias name required for the target table. The Snap is also equipped with the ability to auto-replace the actual table names (with the alias name), if any, used in the ON clause condition, secondary AND conditions, Update Expression list, or Insert Expression list. This applies to Snowflake, Redshift, and Azure Synapse databases.
Display input schema and output schema based on the upstream and downstream Snaps connected to this Snap.
Delete fields mentioned in theExpressionfield from the Snap's output when the mappings have an emptyTarget Path.
ELT Window Functions: Enhances the Snap to support the following Window Functions in addition to the existing ones:
Value Based Analytic Functions
LEAD and LAG Analytic Functions
Fixes the issue of displaying generic error messages for Triggered Task failures with ELT Pipelines by displaying detailed error messages for ease in debugging.
4.23
main7430
Stable
Introducesthe following Snaps:
ELT Load: Loads data from AWS S3 buckets and Azure clusters into the Snowflake and Redshift tables.
ELT Sample: Generates a data subset from the source table.
ELT Window Functions: Provides support for SQL Window Functions in ELT Pipelines.
4.22
main6403
Stable
Introduces the ELT Snap Pack that provides you with the Extract, Load, and Transform (ELT) capabilities. Use the following Snaps to build SQL queries that are executed in the Snowflake database:
ELT Aggregate : Builds SQL query to perform aggregate functions such as SUM, COUNT, MIN, and MAX. Also offers the GROUP BY functionality.
that leads to the SnapLogic documentation site is disabled by default for unsaved Snaps. Save the Snap to enable the Help icon.