In this article
...
Use this Snap to perform the MERGE INTO operation on the specified table. This operation updates, inserts, and deletes rows in/from the target table based on values in a source table. You can set match conditions in the Snap based on which the merge into operation is carried. The Snap creates a table and inserts the data if the target table does not exist.
After successfully running the Pipeline with this Snap, you can use this Snap's output view to verify whether the data would be inserted correctly in the target table.
...
| Info | ||
|---|---|---|
| ||
You can use the SQL Expressions and Functions supported for ELT to define your Snap or Account settings with the Expression symbol = enabled, where available. This list is common to all target CDWs supported. You can also use other expressions/functions that your target CDW supports. |
...
| Parameter Name | Data Type | Description | Default Value | Example | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Label | String |
| ELT Merge Into | Merge Sales Data | ||||||||||||||
| Database Name | String | The name of the database in which the target table exists. Leave this blank if you want to use the database name specified in the Default Database Name field in the account settings. | N/A | TESTDB | ||||||||||||||
| Schema Name | String | Required. The name of the database schema. In case it is not defined, then the suggestion for the schema name retrieves all schema names in the specified database when you click the suggest button.
| N/A | SALES | ||||||||||||||
| Target Table Name | String | Required. The name of the table in which you want to perform the MERGE INTO operation.
| N/A | SALES_ORDERS | ||||||||||||||
| Target Table Hash Distribution Column (Azure Synapse Only) | String/Expression | Specify the Hash distribution column name for the target table in Azure Synapse, if you configure INSERT action in the Snap.
| N/A | var table | ||||||||||||||
| Target Table Alias | String/Expression | Specify the alias name for the target table.
| N/A | SLS_ORDRS | ||||||||||||||
| Input Source Alias | String | Enter the alias name that you want to use for the source table.
| N/A | src | ||||||||||||||
| ON Condition | String | Required. The condition based on which you want to check the values in the target table. You can also use Pipeline parameters in this field to bind values. However, you must be careful to avoid SQL injection. See Preventing SQL Injection for details. | N/A | src.PROD_ID=SALES.PROD_ID | ||||||||||||||
| Merge-into Statements | Use this field set to specify the conditions that activate the MERGE INTO operation and the additional conditions that must be met. Specify each condition in a separate row. Click This field set contains the following fields:
| |||||||||||||||||
| When Clause | String/Expression/Suggestion | Specify the matching condition based on the outcome of the ON Condition. Alternatively, click Available options are:
Redshift and Snowflake supports the following actions in Merge-into statements:
Azure Synapse supports the following actions in Merge-into statements:
| WHEN MATCHED | WHEN NOT MATCHED | ||||||||||||||
| Condition | String | Specify the additional criteria that must be specified. Having this additional condition allows the Snap to identify whether the UPDATE or DELETE action must be performed (since both the actions correspond to the WHEN MATCHED clause). You can also use Pipeline parameters in this field to bind values. However, you must be careful to avoid SQL injection. See Preventing SQL Injection for details. | N/A | TOTAL_ORDERS = 0 | ||||||||||||||
| Action | Drop-down list | Choose the action to apply on the condition. Available options are:
| INSERT | DELETE | ||||||||||||||
| Insert Expression | Use this field set to specify the column in which you want to insert the data and also the values that you want to insert into them. Each column must be specified in a separate row. Click + to add a new row. This field set contains the following fields:
| |||||||||||||||||
| Insert Column | String/Expression/Suggestion | Specify the column in which the value must be inserted. Alternatively, click | N/A | PRODUCT_ID | ||||||||||||||
| Insert Value | String/Expression | Specify the value to be inserted for the column. This field can be an SQL expression that references the source table's columns only or none. It cannot reference the target table's columns. You can also use Pipeline parameters in this field to bind values. However, you must be careful to avoid SQL injection. See Preventing SQL Injection for details. | N/A | src.PRODUCT_ID | ||||||||||||||
| Update Expression - When Matched | Use this field set to add expressions whose values must be updated when the the Merge Into condition matches the source data. Specify each column to be updated in a separate row. Click This field set contains the following fields:
| |||||||||||||||||
| Update Column | String/Expression/Suggestion | Specify the column in which the value must be updated. Alternatively, click | N/A | TOTAL_ORDERS | ||||||||||||||
| Update Value | String/Expression | Specify the new value to be inserted when the Merge Into condition matches the source. | N/A | src.TOTAL_ORDERS + 1 | ||||||||||||||
| Update Expression – When Not Matched By Source | Applicable only for Azure Synapse and is used only when you choose the WHEN NOT MATCHED BY SOURCE as the When clause. This field set contains the following fields:
| |||||||||||||||||
| Update Column | String/Expression/Suggestion | Specify the column name in which the value must be updated or deleted as specified in the conditions. Alternatively, click
| N/A | TOTAL_ORDERS | ||||||||||||||
| Update Value | String/Expression | Specify the new value to be inserted when the Merge Into condition matches the source. | N/A | src.TOTAL_ORDERS + 1 | ||||||||||||||
| Get preview data | Check box |
| Not selected | Selected | ||||||||||||||
...
Method-2: Dynamic Substitutions
You must enable expressions when using Pipeline parameters for dynamic substitutions. Format the SQL expression, except the Pipeline parameter's reference, as a string.
For example, if you want to use the Pipeline parameter, name, which contains the value of a column in the ON Condition, Condition, Insert Value, or Update Value fields:
...
| Error | Reason | Resolution |
|---|---|---|
The Snap has not been configured properly. (This error scenario occurs when the Target table does not exist (Snap needs to create one), and the Target Table Hash Distribution Column is not specified.) | Without the Target Table Hash Distribution Column defined for creating the new table in Azure Synapse, the Snap creates a new target table with Round-Robin distribution (default for Azure) instead of a Hash-distributed table. But, as the Snap cannot insert values into a non-Hash-distributed table, it errors out with this message. | If you have not created the Hash-distributed table before hand, ensure that you specify the Target Table Hash Distribution Column for creating the new table. To do so, validate the Pipeline to get the target table column names through the Input SQL coming from the upstream Snap. This allows the ELT Merge Into Snap to create a Hash-distributed table in the Azure Synapse Database and insert the rows, as needed. If the target table exists already and was created with Hash distribution, you can leave this field blank. |
Database cannot be blank. (when seeking the suggested list for Schema Name field) | Suggestions in the Schema Name and Target Table Name fields do not work when you have not specified a valid value for the Database Name field in this Snap. | Specify the target Database Name in this Snap to view and choose from a suggested list in the Schema Name and Target Table Name fields respectively. |
| Column names in Snowflake tables are case-sensitive. It stores all columns in uppercase unless they are surrounded by quotes during the time of creation in which case, the exact casing is preserved. See, Identifier Requirements — Snowflake Documentation. | Ensure that you follow the same casing for the column table names across the Pipeline. | |
[Simba][SparkJDBCDriver](500051) ERROR processing query/statement. Error Code: 0 Cannot create table (' (Target CDW: Databricks Lakehouse Platform) | The specified location contains one of the following:
However, this corrupted table can only be dropped manually—by accessing the DBFS through a terminal. The Pipeline cannot perform this operation. Drop the corrupted table and then try creating the new table in Delta format (using the Pipeline). To drop the corrupted table, from the terminal, access the DBFS and run the following command: dbfs rm -r dbfs:/<table_path>
So, the Snap/Pipeline cannot overwrite this table with the target table as needed. | Ensure that you take appropriate action (mentioned below) on the existing table before running your Pipeline again (to create another Delta table at this location). Move or drop the existing table from the schema manually using one of the following commands: Access the DBFS through a terminal and run:
OR Use a Python notebook and run:
|
Example
Retrieving and Transforming Records and Merging Them Into A Table
In this example, we want to retrieve records from two tables. First, we transform the retrieved records using conditions and use a JOIN clause to join the queries from the two tables. We then perform transformations on the records and apply aggregate function. Finally, we merge the records by applying conditions and actions. This example demonstrates how we can accomplish this task.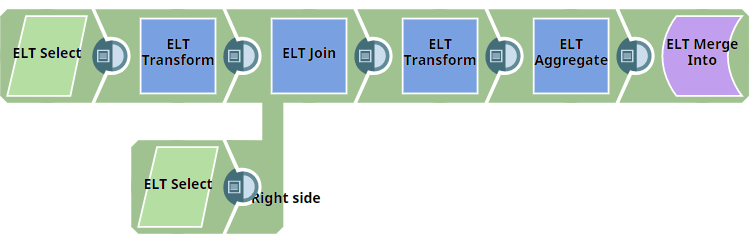
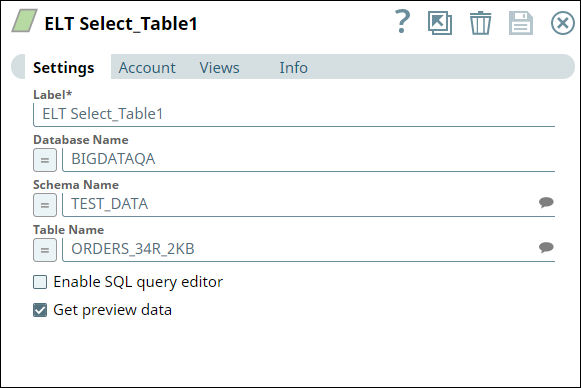
First, we use two ELT Select Snaps to build SELECT queries to retrieve all records from the tables (ORDERS_34R_2KB and CUSTOMER_50R_3KB). The configuration and query output is as shown below:
| ELT Select Snaps | Output |
|---|---|
|
|
|
|
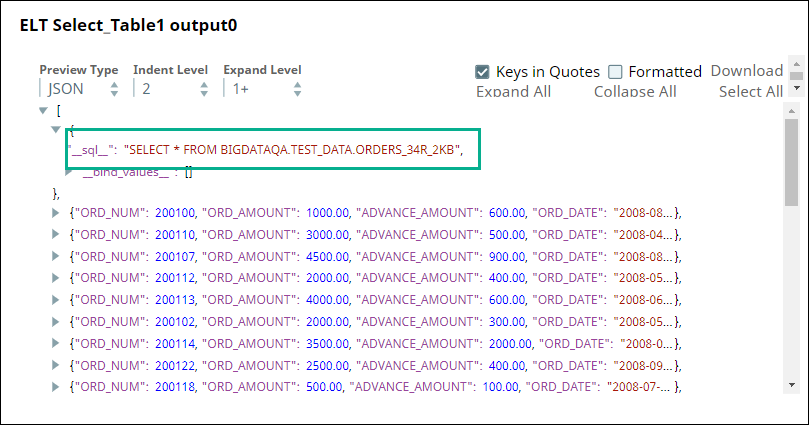
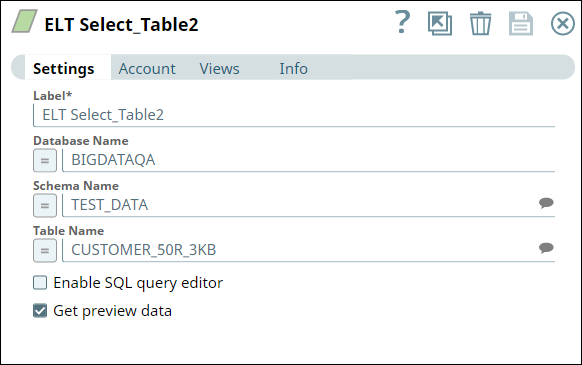
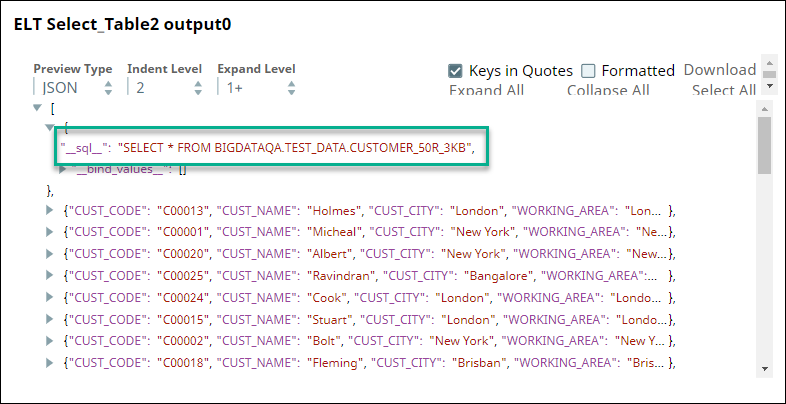
The tables have several columns. But, we want to retrieve only the CUST_CODE and ORD_AMOUNT columns. Therefore, we configure the ELT Transform Snap with the following settings, which builds the query as shown below:
| ELT Transform | Output |
|---|---|
The SELECT queries in the ELT Select and ELT Transform Snaps form the inputs for the ELT Join Snap. Now, we apply an inner join based on matching values of the CUST_CODE column in the tables. Hence, we configure the ELT Join Snap and validate. Upon validation, the ELT Join Snap combines both the incoming SELECT queries and adds the JOIN clause. The output preview is as shown below:
| ELT Join | Output |
|---|---|
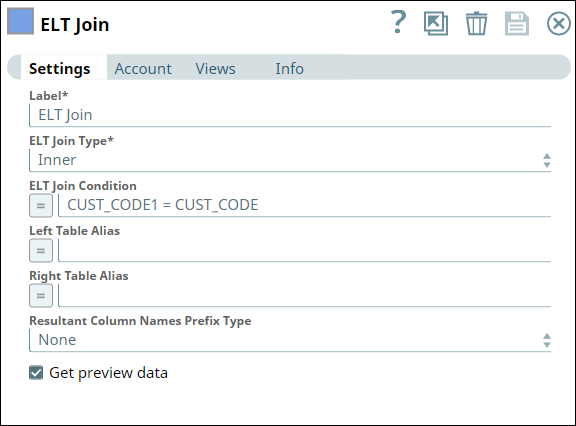 | 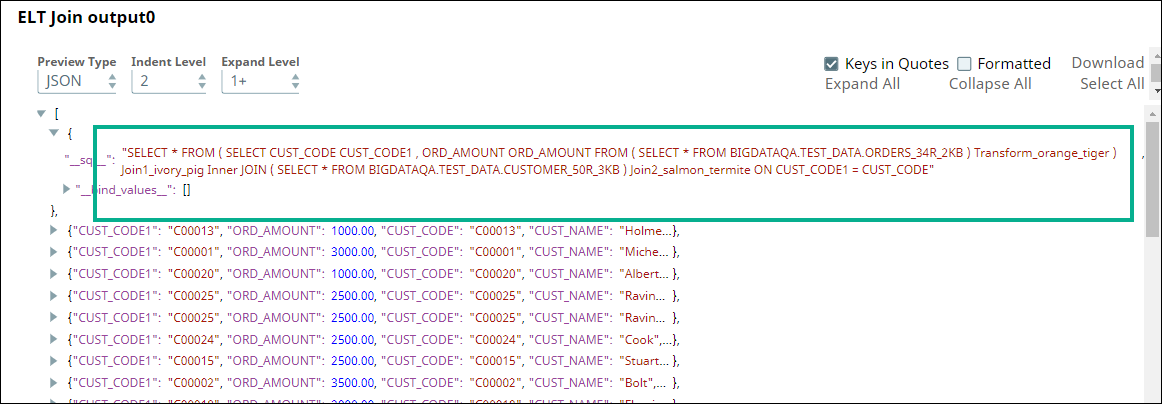 |
We use the ELT Transform Snap to retrieve only the CUST_NAME and ORD_AMOUNT columns after joining the queries. We configure the Snap with the following setting which builds the query as shown below:
| ELT Transform Snap | Output |
|---|---|
|
|
Subsequently, we use an ELT Aggregate Snap to apply an aggregate function on the values in the ORD_AMOUNT column. Here, we want to calculate the SUM for the ORD_AMOUNT column.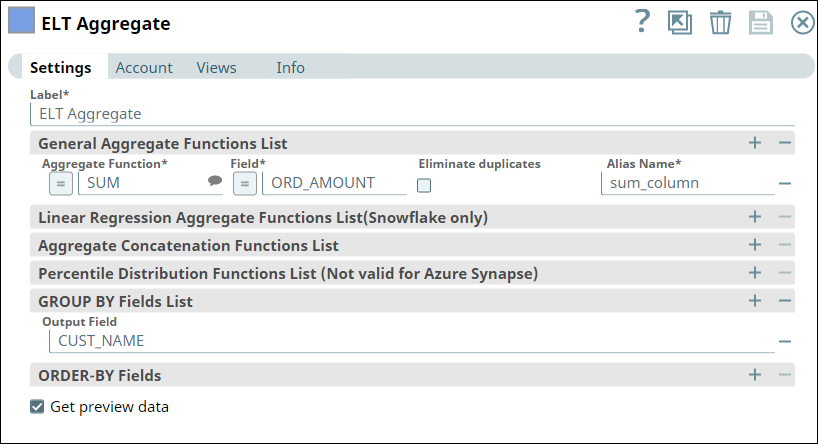
The Snap builds the query as shown below: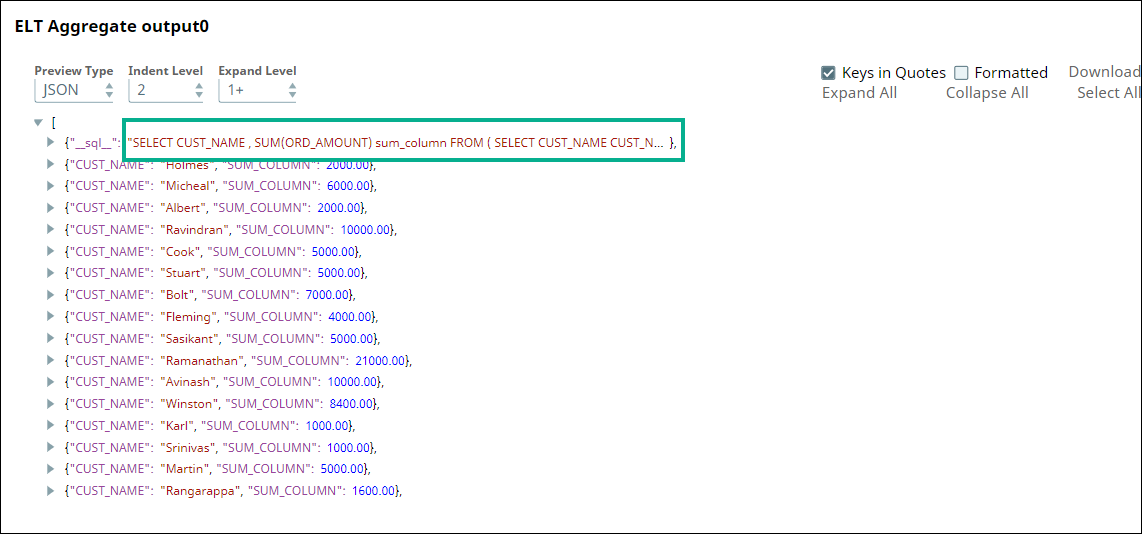
Finally, we use the ELT Merge Into Snap to merge the records into the Target table MERGE_INTO_OUT_01 based on the ON Condition, apply Merge-into statements, update actions, and update expressions.
The ON condition checks for the customer's name - if the customer's name matches, it applies the Merge-into statements and applies conditions as configured below. In this case, if the customer's name matches and if the condition (SUM_COLUMN<5000) is met, then the Snap updates the record with customer's name. If the customer's name does not match and if the condition (SrcAlias.SUM_COLUMN<5000) is met, then it inserts the customer's name into the record.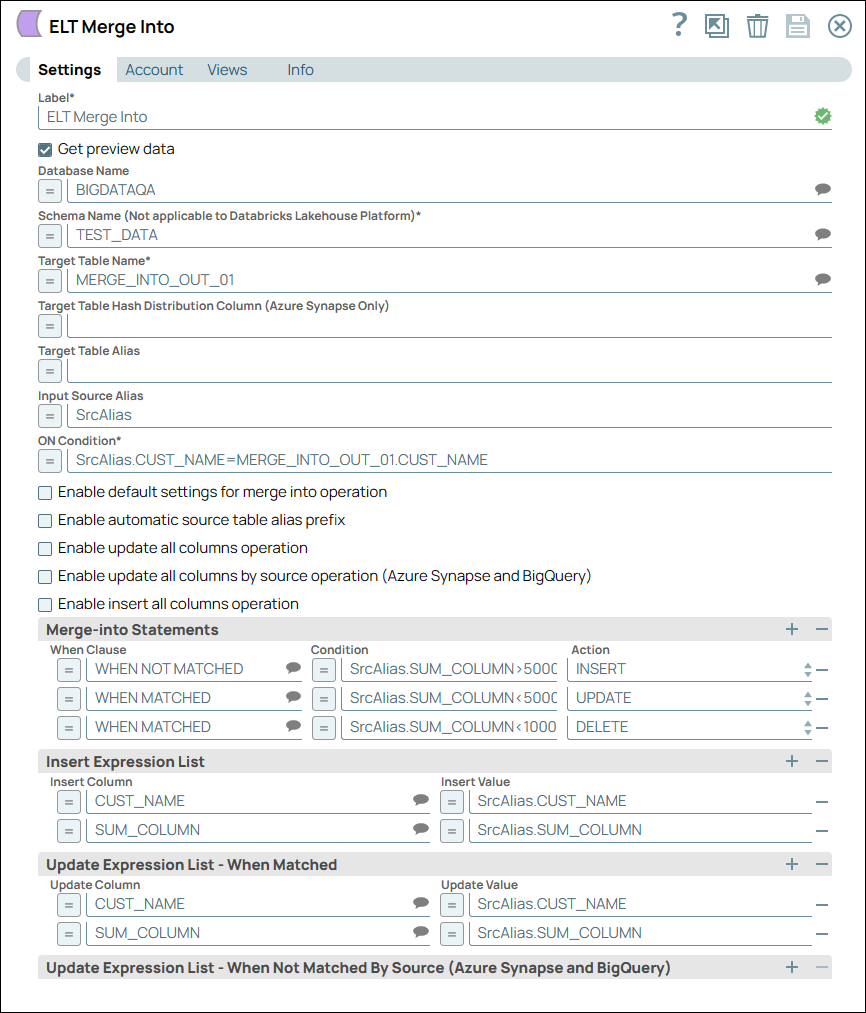
Upon successful execution, the Pipeline adds and updates customer records in the Target database table in the configured database.
Downloads
| Note | ||
|---|---|---|
| ||
|
...