Apache™ Hadoop® is an open-source software framework for the storage and processing of large datasets.
Use Snaps in this Snap Pack to read data from and write data to the Hadoop File System (HDFS).
Note
A Groundplex needs to be configured as a Hadoop client for this integration to work. What JAR files and property files need to be installed for this depends on the version and vendor of your Hadoop File System. Refer to your vendor's documentation for that information.
Supported Versions
This Snap Pack is tested against:
CDH 5.8
CDH 5.10
CDH 5.16.1
CDH 5.16
CDH 6.1.1
HDP 2.6.1
HDP 2.6.3.1
HDP 2.6.3
Panel
bgColor
#ebf7e1
borderStyle
solid
In this Section
Child pages (Children Display)
all
true
depth
2
Customizing the Location of the Temporary Directory
Snaps in the Hadoop Snap Pack briefly save a temporary file in the system while processing and before passing the contents to a downstream Snap. The temporary file is stored in a default location and automatically deleted after the process is complete.
You can change the location of the temporary file to a custom location by using the global property jcc.jvm_options.
You may choose to use one of the two methods in this section, to change the temporary file location.
Note
Modifying thejava.io.tmp.dir file does not change the location of the temporary file.
Method 1: Specifying the Temporary Location in the SnapLogic Manager
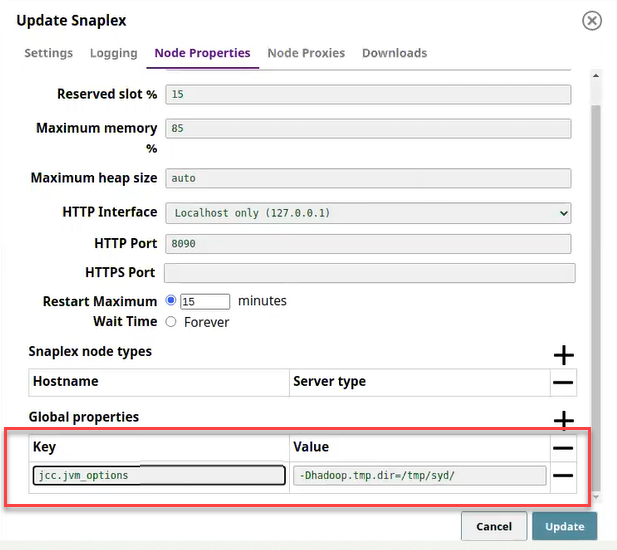
In the SnapLogic Manager, Snaplexes tab, select the applicable Snaplex's name.
In the Update Snaplex dialog, Node Properties tab, under Global properties, add the global property, jcc.jvm_options = -Dhadoop.tmp.dir=/tmp/syd, where /tmp/syd is the new location to save the temporary file.
3. Click Update and OK to Snaplex Update Notice. This updates the new location for the temporary file and restarts the Snaplex with the new property setting.
Method 2: Manually Changing the Location of Temporary File in global.properties
You can change from the default location of the temporary file to another location in global.properties in your local SnapLogic environment.
Access the /etc folder in your SnapLogic installation:
For a Linux installation, enter the command: cd $SL_ROOT/etc on the command prompt.
For a Windows installation, enter the command: cd %SL_ROOT%\etc on the command prompt.
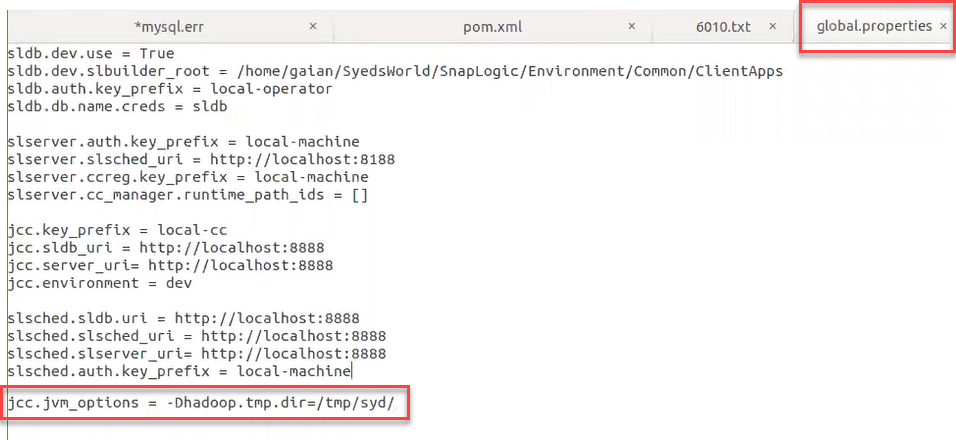
Open the global.properties file. Add the following entry: jcc.jvm_options = -Dhadoop.tmp.dir=tmp/syd/
Image Modified
3. Save the file and restart the Snaplex to update the new location for the temporary file.
Note
A folder, s3a, is created under the temporary location path to store the temporary file.
Known Issues
After upgrading your Snaplex to the 4.20 GA version, Pipelines with HDFS Reader Snapthat use Kerberos authentication might remain in the start state.
ORC Writer/Reader Snaps fail on S3 when using the 4.20 Snaplex with the previous Snap Pack version (hadoop8270 and snapsmrc528) displaying this error:Unable to read input stream, Reason: For input string: "100M" error.
ORC Reader/Writer and Parquet Reader/Writer Snaps fail in 4.20 when executing a Pipeline on S3 with this error:org.apache.hadoop.fs.StorageStatistics.
Upgraded with the latest SnapLogic Platform release.
4.27 Patch
427patches13769
Latest
Fixed an issue with the Hadoop Directory Browser Snap where the Snap was not listing the files in the given directory for Windows VM.
4.27 Patch
427patches12999
Latest
Enhanced the Parquet Reader Snap with int96 As Timestamp checkbox, which when selected enables the Date Time Format field. You can use this field to specify a date-time format of your choice for int96 data-type fields. The int96 As Timestamp checkbox is available only when you deselect Use old data format checkbox.
4.27
main12833
Stable
Enhanced the Parquet Writer and Parquet Reader Snaps with Azure SAS URI properties, and Azure Storage Account for Hadoop with SAS URI Auth Type. This enables the Snaps to consider SAS URI given in the settings if the SAS URI is selected in the Auth Type during account configuration.
4.26
426patches12288
Latest
Fixed a memory leak issue when using HDFS protocol in Hadoop Snaps.
4.26
main11181
Stable
Upgraded with the latest SnapLogic Platform release.
4.25 Patch
425patches9975
Latest
Fixed the dependency issue inHadoop Parquet ReaderSnap while reading fromAWS S3. The issue is caused due to conflicting definitions for some of the AWS classes (dependencies) in the classpath.
4.25
main9554
Stable
Enhanced the HDFS Reader and HDFS Writer Snaps with the Retry mechanism that includes the following settings:
Number of Retries: Specifies the maximum number of retry attempts when the Snap fails to connect to the Hadoop server.
Retry Interval (seconds): Specifies the minimum number of seconds the Snap must wait before each retry attempt.
4.24 Patch
424patches9262
Latest
Enhanced the AWS S3 Account for Hadoop to support role-based access when you select IAM role checkbox.
4.24 Patch
424patches8876
Latest
Fixes the missing library error inHadoop Snap Pack when running Hadoop Pipelines in JDK11 runtime.
4.24
main8556
Stable
Upgraded with the latest SnapLogic Platform release.
4.23 Patch
423patches7440
Latest
Fixes the issue inHDFS ReaderSnap by supporting to read and write files larger than 2GB using ABFS(S) protocol.
4.23
main7430
Stable
Upgraded with the latest SnapLogic Platform release.
4.22
main6403
Stable
Upgraded with the latest SnapLogic Platform release.
4.21 Patch
hadoop8853
Latest
Updates the Parquet Writer and Parquet Reader Snaps to support the yyyy-MM-dd format for the DATE logical type.
4.21
snapsmrc542
Stable
Upgraded with the latest SnapLogic Platform release.
4.20 Patch
hadoop8776
Latest
Updates the Hadoop Snap Pack to use the latest version of org.xerial.snappy:snappy-java for compression type Snappy, in order to resolve the java.lang.UnsatisfiedLinkError: org.xerial.snappy.SnappyNative.maxCompressedLength(I)I error.
4.20
snapsmrc535
Stable
Upgraded with the latest SnapLogic Platform release.
4.19 Patch
hadoop8270
Latest
Fixes an issue with the Hadoop Parquet Writer Snap wherein the Snap throws an exception when the input document includes one or all of the following:
Empty lists.
Lists with all null values.
Maps with all null values.
4.19
snaprsmrc528
Stable
Upgraded with the latest SnapLogic Platform release.
4.18 Patch
hadoop8033
Latest
Fixed an issue with the Parquet Writer Snap wherein the Snap throws an error when working with WASB protocol.
Added ADLS Gen2 support for ABFS (Azure Blob File System) and ABFSS protocols.
4.17
ALL7402
Latest
Pushed automatic rebuild of the latest version of each Snap Pack to SnapLogic UAT and Elastic servers.
4.17
snapsmrc515
Latest
Added the Snap Execution field to all Standard-mode Snaps. In some Snaps, this field replaces the existing Execute during preview check box.
4.16
snapsmrc508
Stable
Added a new property, Output for each file written, to handle multiple binary input data in the HDFS Writer Snap.
4.15
snapsmrc500
Stable
Added two new Snaps: HDFS ZipFile Reader and HDFS ZipFile Writer.
Added support for the Data Catalog Snaps in Parquet Reader and Parquet Writer Snaps.
4.14 Patch
hadoop5888
Latest
Fixed an issue wherein the Hadoop snaps were throwing an exception when a Kerberized account is provided, but the snap is run in a non-kerberized environment.
4.14
snapsmrc490
Stable
Added the Hadoop Directory BrowserSnap, which browses a given directory path in the Hadoop file system using the HDFS protocol and generates a list of all the files in the directory. It also lists subdirectories and their contents.
Added support for S3 file protocol in theORC Reader, andORC WriterSnaps.
Added support for reading nested schema in the Parquet Reader Snap.
4.13 Patch
hadoop5318
Latest
Fixed the HDFS Reader/Writer and Parquet Reader/Writer Snaps, wherein Hadoop configuration information does not parse from the client's configuration files.
Fixed the HDFS Reader/Writer and Parquet Reader/Writer Snaps, wherein User Impersonation does not work on Hadooplex.
4.13
snapsmrc486
Stable
KMS encryption support added to AWS S3 account in the Hadoop Snap Pack.
Enhanced the Parquet Reader, Parquet Writer, HDFS Reader, and HDFS Writer Snaps to support WASB and ADLS file protocols.
Added the AWS S3 account support to the Parquet Reader and Writer Snaps.
Added second input view to the Parquet Reader Snap that when enabled, accepts table schema.
Supported with AWS S3, Azure Data Lake, and Azure Storage Accounts.
4.12 Patch
hadoop5132
Latest
Fixed an issue with the HDFS Reader Snap wherein the pipeline becomes stale while writing to the output view.
4.12
snapsmrc480
Stable
Upgraded with the latest SnapLogic Platform release.
4.11 Patch
hadoop4275
Latest
Addressed an issue with Parquet Reader Snap leaking file descriptors (connections to HDFS data nodes). The Open File descriptor values work stable now,
4.11
snapsmrc465
Stable
Added Kerberos support to the standard mode Parquet Reader and Parquet Writer Snaps.
4.10 Patch
hadoop4001
Latest
Supported HDFS Writer to write to the encryption zone.
4.10 Patch
hadoop3887
Latest
Addressed the suggest issue for the HDFS Reader on Hadooplex.
4.10 Patch
hadoop3851
Latest
ORC supports read/write from local file system.
Addressed an issue to bind the Hive Metadata to Parquet Writer Schema at Runtime.
4.10 Patch
hadoop3838
Latest
Made HDFS Snaps work with Zone encrypted HDFS.
4.10
snapsmrc414
Stable
Updated the Parquet Writer Snap withPartition byproperty to support the data written into HDFS based on the partition definition in the schema in Standard mode.
Support for S3 accounts with IAM Roles added to Parquet Reader and Parquet Writer
HDFS Reader/Writer with Kerberos support on Groundplex (including user impersonation).
4.9 Patch
hadoop3339
Latest
Addressed the following issues:
ORC Reader passing, but ORC Writer failing when run on a Cloudplex.
ORC Reader Snap is not routing error to error view.
Intermittent failures with the ORC Writer
4.9.0 Patch
hadoop3020
Latest
Added missing dependency org.iq80.snappy:snappy to Hadoop Snap Pack.
4.9
snapsmrc405
Stable
Upgraded with the latest SnapLogic Platform release.
4.8
snapsmrc398
Stable
Snap-aware error handling policy enabled for Spark mode in Sequence Formatter and Sequence Parser. This ensures the error handling specified on the Snap is used.
4.7.0 Patch
hadoop2343
Latest
Spark Validation: Resolved an issue with validation failing when setting the output file permissions.
4.7
snapsmrc382
Stable
Updated the HDFS Writer and HDFS Reader Snaps with Azure Data Lake account for standard mode pipelines.
HDFS Writer: Spark mode support added to write to a specified directory in an Azure Storage Layer using the wasb file system protocol.
HDFS Reader: Spark mode support added to read a single file or an HDFS directory from an Azure Storage Layer.
4.6
snapsmrc362
Stable
The following Snaps now support error view in Spark mode: HDFS Reader, Sequence Parser.
Resolved an issue in HDFS Writer Snap that sends the same data in output & error view.
4.5
snapsmrc344
Stable
HDFS Reader and HDFS Writer Snaps updated to support IAM Roles for Amazon EC2.
Support for Spark mode added to Parquet Reader, Parquet Writer
The HBase Snaps are no longer available as of this release.
4.4.1
Stable
Resolved an issue with Sequence Formatter not working in Spark mode.
Resolved an issue with HDFSReader not using the filter set when configuring SparkExec paths.
4.4
Stable
NEW! Parquet Reader and Writer Snaps
NEW!ORC Reader and Writer Snaps
Spark support added to the HDFS Reader, HDFS Writer, Sequence Formatter, and Sequence Parser Snaps.
Behavior change: HDFS Writer in SnapReduce mode now requires the File property to be blank.
4.3.2
Stable
Implemented wasbs:// protocol support in Hadoop Snap Pack.
Resolved an issue with HDFS Reader unable to read all files under a folder (including all files under its subfolders) using the ** filter.