On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
Snap type: | Read | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Description: | This Snap reads data from HDFS (Hadoop File System) and produces a binary data stream at the output. For the hdfs protocol, please use a SnapLogic on-premises Groundplex and make sure that its instance is within the Hadoop cluster and SSH authentication has already been established. The Snap also supports the webhdfs protocol, which does not require a Groundplex and works for all versions of Hadoop. The The Snap also supports reading from a Kerberized cluster using the HDFS protocol.
Hadoop allows you to configure proxy users to access HDFS on behalf of other users; this is called impersonation. When user impersonation is enabled on the Hadoop cluster, any jobs submitted using a proxy are executed with the impersonated user's existing privilege levels rather than those of the superuser associated with the cluster. For more information on user impersonation in this Snap, see the section on User Impersonation below. | |||||||||||||||||||||||||||||
| Prerequisites: | [None] | |||||||||||||||||||||||||||||
| Limitations and Known Issues: |
| |||||||||||||||||||||||||||||
| Account: | This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. This Snap supports Azure storage account, Azure Data Lake account, Kerberos account, or no account. Account types supported by each protocol are as follows:
Required settings for account types are as follows:
IAM Roles for Amazon EC2global.properties jcc.jvm_options = -DIAM_CREDENTIAL_FOR_S3=TRUE Please note this feature is supported in only in Groundplex nodes hosted in the EC2 environment. For more information on IAM Roles, see http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/iam-roles-for-amazon-ec2.html Kerberos Account UI Configuration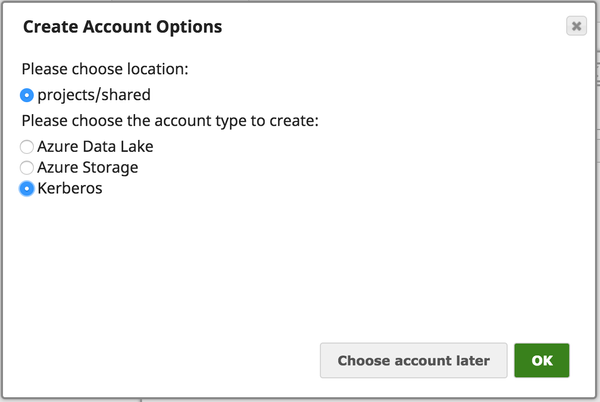 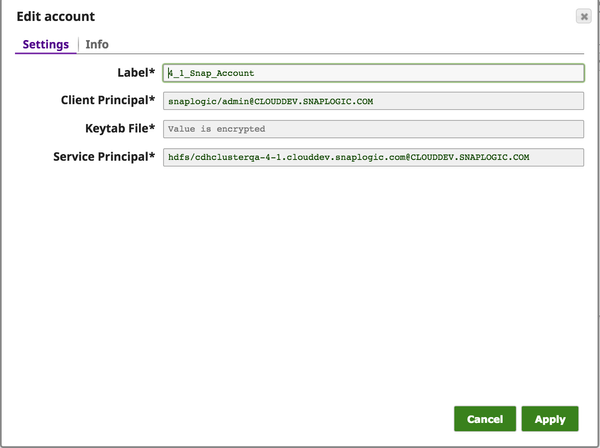
| |||||||||||||||||||||||||||||
| Views: |
| |||||||||||||||||||||||||||||
Settings | ||||||||||||||||||||||||||||||
Label | Required. Specify the name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | |||||||||||||||||||||||||||||
Directory | Specify the URL for the data source (directory). The Snap supports the following protocols.
When you use the ABFS protocol to connect to an endpoint, the account name and endpoint details provided in the URL override the corresponding values in the Account Settings fields. The Directory property is not used in the pipeline execution or preview and used only in the Suggest operation. When you press the Suggest icon, it will display a list of subdirectories under the given directory. It generates the list by applying the value of the Filter property. Examples:
Default value: hdfs://<hostname>:<port>/
| |||||||||||||||||||||||||||||
Filter |
| |||||||||||||||||||||||||||||
File | The name of the file to be read. This can also be a relative path under the directory given in the Directory property. It should not start with a URL separator "/".
Default value: [None] | |||||||||||||||||||||||||||||
| User Impersonation |
| |||||||||||||||||||||||||||||
| Number Of Retries | Specify the maximum number of attempts to be made to receive a response.
Default value: 0 | |||||||||||||||||||||||||||||
| Retry Interval (seconds) | Specify the time interval between two successive retry requests. A retry happens only when the previous attempt resulted in an exception. Default value: 1 | |||||||||||||||||||||||||||||
| Select one of the three following modes in which the Snap executes: Available options are:
| |||||||||||||||||||||||||||||
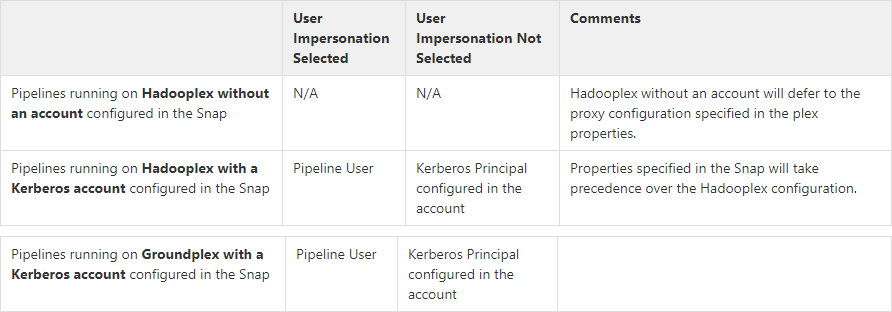
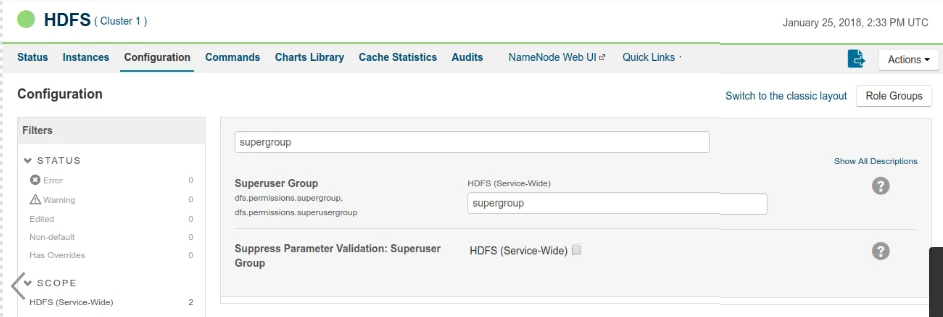
Troubleshooting
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|