In this article
| Table of Contents | ||||
|---|---|---|---|---|
|
Overview
Salesforce Wave Analytics Snap is a Write-type Snap that enables you to load external data into Salesforce Wave Analytics. This Snap converts a stream of input documents into CSV data and metadata and uploads them to Salesforce Wave Analytics as external data. It scans the first 50 documents and generates the metadata automatically, which can be overridden. The Snap uploads CSV data in multi parts with each not exceeding 10MB.
Prerequisites
None.
Support for Ultra Pipelines
Works in Ultra Task Pipelines.
Limitations and Known Issues
None.
Snap Views
| View Type | View Format | Number of Views | Examples of Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
| Input | Document |
| CSV Generator | Each input document should have a flat map data since it is converted to one row of CSV data. If this map data contains a value of another map or list object, the document is not used and passed to the error view. |
| Output | Document |
| Any Snap with a document input view | If the Snap is in the Preview Action mode, it writes the metadata to the output view. |
| Error | Document |
| N/A | The error view contains error, reason, resolution and stack trace. For more information, see Handling Errors with an Error Pipeline. |
Snap Settings
| Field | Field Type | Description | |||||||
|---|---|---|---|---|---|---|---|---|---|
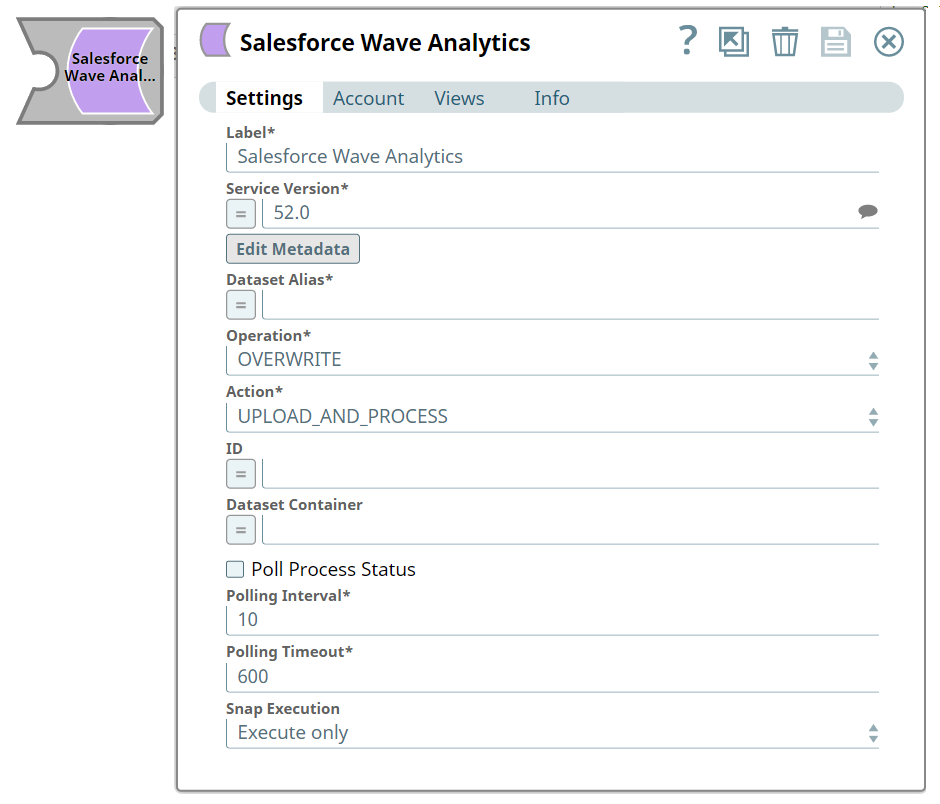
Label* | String | The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your Pipeline. Default Value: Salesforce Wave Analytics | |||||||
Service Version* | String/Expression/Suggestion |
| |||||||
Edit metadata | Button | Allows you to edit metadata for the CSV data to be uploaded to Salesforce Analytics. Refer to the example in the Examples section for more information. Default Value: N/A | |||||||
Dataset Alias* | String/Expression | Alias of an dataset, which must be unique across an organization. Default Value: [None] | |||||||
Operation* | Dropdown list | The database operation to use when loading data into the dataset. The available options are:
Default Value: OVERWRITE | |||||||
Action* | Dropdown list | Action to perform on the external data. 'Upload' indicates uploading external data from SnapLogic to Salesforce.com', and 'Process' indicates loading uploaded data into dataset. The options available include:
Default Value: UPLOAD_AND_PROCESS | |||||||
ID | String/Expression | The unique ID of the loaded external data. This field is required if the action is 'Process'. Default Value: [None] | |||||||
Dataset Container | String/Expression | The folder name. If you do not specify a folder name when creating a new dataset, the Dataset container will be the user’s private folder. If not specified for an existing Dataset, the Dataset container will be the folder that currently contains the Dataset. Default Value: [None] | |||||||
Poll Process Status | Checkbox | If you select this checkbox, the Snap polls until the process status becomes 'Completed' or 'Failed'. If you deselect this checkbox, the Polling interval and the Polling timeout fields are ignored. Default Value: Not selected | |||||||
Polling Interval* | String | Specify the polling interval in seconds for the Bulk API batch job execution. At each polling interval, the Snap checks the status of the Bulk API batch processing. Maximum Value: 60 Default Value: 10 | |||||||
Polling Timeout* | String | Specify the polling timeout in seconds for the Bulk API batch job execution. If the timeout occurs while waiting for the completion of the batch job execution, the Snap throws a SnapExecutionException. Maximum Value: 1800 Default Value: 600 | |||||||
Snap Execution | Dropdown list |
| |||||||
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|
| Note | ||
|---|---|---|
When you upsert records, you may make a record related to another record in the parent object by providing an additional key/value entry in the input document. You may use the suggest buttons in the Related object and the Related external ID properties for an available selection for the object type of the records to be upserted. If values are entered in these properties, you may connect the Mapper Snap in front of the Create Snap to see the input schema suggest, which helps see how input data should be prepared to establish a relationship between records. Additionally, if you want to get the resulting status for each record to be upserted in Bulk API mode, you must connect a Salesforce Poller Snap after the Salesforce Upsert Snap. For an example of "Contact" as Object type, "Account" as Related object and "AccountNumber__c" as Related external ID, the following additional key/value entry should be added to the input document:
|
Example
The following example Pipeline shows how to upload data to Salesforce Wave Analytics.
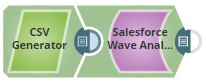
In this Pipeline execution:
Object record details are provided to Salseforce Wave Analytics Snap as a CSV using a CSV Generator Snap: 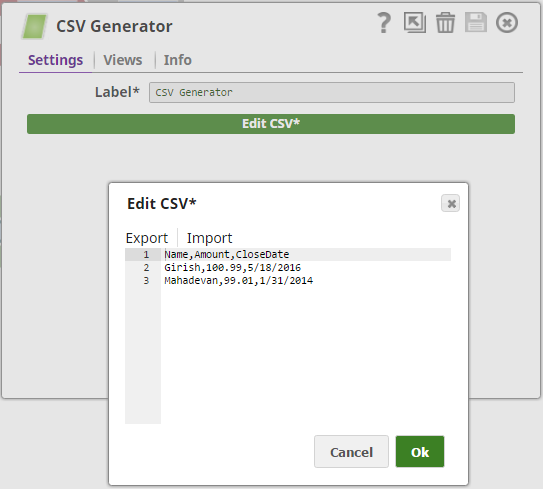
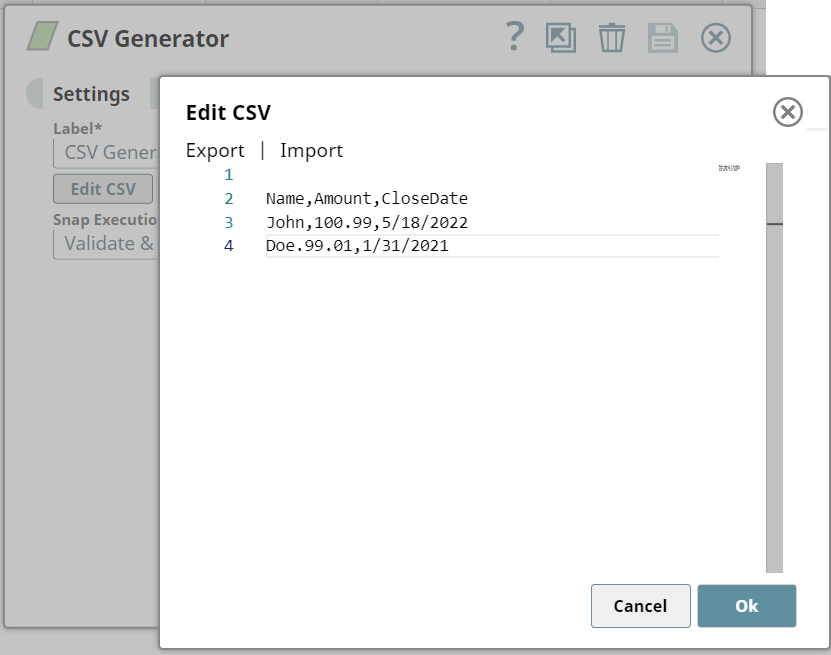
A Salesforce Wave Analytics Snap uploads and processes the incoming records: .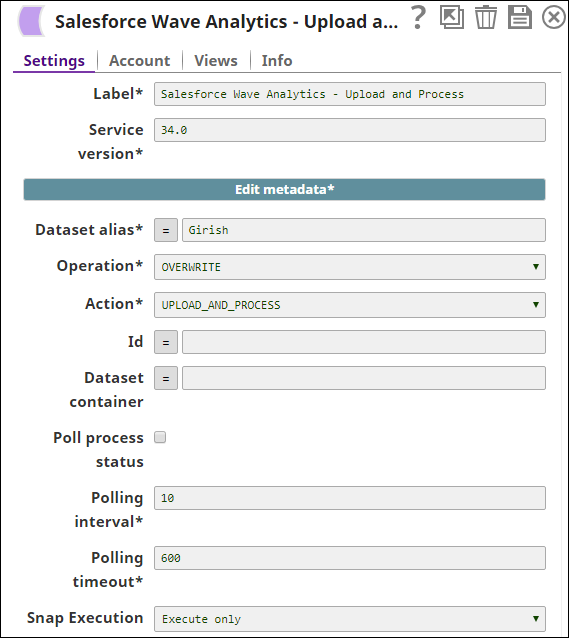
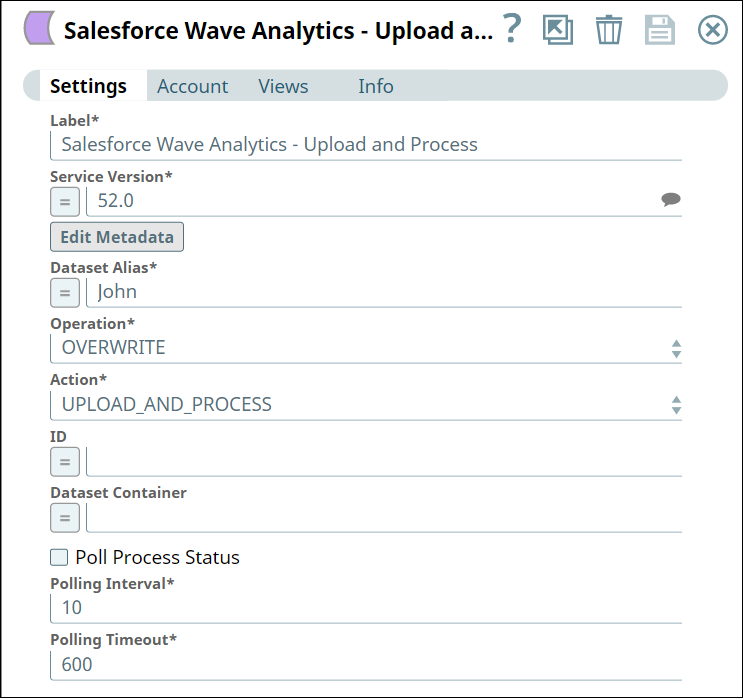
Successful execution of the Snap gives the following preview: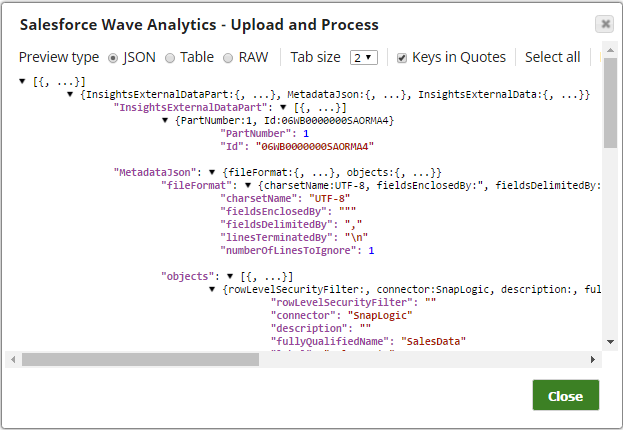
The following is an example for the Edit metadata property field. Note that, by default, the metadata is populated for the incoming data in the Salesforce Wave Analytics Snap. You can customize the metadata further based on your requirements:
| Code Block |
|---|
{
"fileFormat": {
"charsetName": "UTF-8",
"fieldsEnclosedBy": "\"",
"fieldsDelimitedBy": ",",
"linesTerminatedBy": "\n",
"numberOfLinesToIgnore": 1
},
"objects": [
{
"rowLevelSecurityFilter": "",
"connector": "SnapLogic",
"description": "",
"fullyQualifiedName": "SalesData",
"label": "Sales Data",
"name": "SalesData",
"fields": [
{
"description": "",
"fullyQualifiedName": "SalesData.Name",
"label": "Account Name",
"name": "Name",
"isSystemField": false,
"defaultValue": "",
"isUniqueId": false,
"isMultiValue": false,
"type": "Text",
"precision": 0,
"scale": 0,
"format": ""
},
{
"description": "",
"fullyQualifiedName": "SalesData.Amount",
"label": "Opportunity Amount",
"name": "Amount",
"isSystemField": false,
"defaultValue": "",
"isUniqueId": false,
"isMultiValue": false,
"type": "Numeric",
"precision": 10,
"scale": 2,
"format": "$#,#\#0.00"
},
{
"description": "",
"fullyQualifiedName": "SalesData.CloseDate",
"label": "Opportunity Close Date",
"name": "CloseDate",
"isSystemField": false,
"defaultValue": "",
"isUniqueId": false,
"isMultiValue": false,
"type": "Date",
"precision": 0,
"scale": 0,
"format": "MM/DD/YYYY",
"fiscalMonthOffset": 0
}
]
}
]
} |
The list of map data at "fields" is initially empty, which is a place for CSV column metadata. If the Action property is set to "PREVIEW", the Snap will try to generate the CSV metadata automatically and writes it to the output view. You can copy and paste it into the Edit metadata property. If the list of map data at "fields" is not empty, the content of the Edit property will override what is generated automatically. Therefore, you can use the Edit metadata property to fine-tune the CSV column metadata.
For "Date" type, use the Java date format string as defined in http://docs.oracle.com/javase/7/docs/api/java/text/SimpleDateFormat.html
The Snap takes four types of joda data/time java objects (DateTime, LocalDateTime, LocalDate and LocalTime) and automatically converts them to strings with formats: "yyyy-MM-dd'T'HH:mm:ss.SSSZZ", "yyyy-MM-dd'T'HH:mm:ss.SSS", "yyyy-MM-dd", and "HH:mm:ss.SSS" correspondingly.
The currency data type is not automatically detected by the Snap. You should make sure the input data is string and edit the "type", "precision", "scale" and "format" fields as in the example above. Please note "##" should be edited as "#\#" because the editor in the Edit metadata property uses "##" as a comment. If the second '#' is not escaped, the remaining string is not passed from the editor to the Snap, which will cause it fail to upload data.
See Also
- See Salesforce Wave Analytics documentation for additional information (you must be logged into the Salesforce site).
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|