In this article
| Table of Contents | ||||
|---|---|---|---|---|
|
Overview
You can use the Kafka Consumer Snap to read or consume documents from a Kafka topic.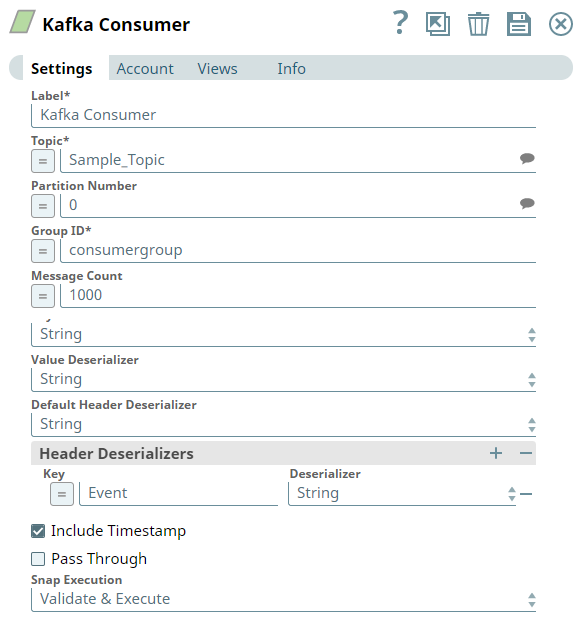
Prerequisites
- A valid account with the required permissions.
- A Kafka topic with parameters that are valid for consumption (reading).
| Info |
|---|
In order for the notifications to work properly, all the Consumer and Acknowledge Snaps that belong to one consumer group should execute in the same node of the Snaplex. You can either use Pipeline Execute Snap to execute different Pipelines in the same node, or place all the Consumer and Acknowledge Snaps into one Pipeline. |
Support for Ultra Pipelines
Works in Ultra Pipelines.
Limitations and Known Issues
None.
Snap Input and Output
| Input/Output | Type of View | Number of Views | Examples of Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
| Input | Document |
|
| A document containing a Kafka topic, a consumer group, a partition, and an offset. |
| Output | Document |
|
| The message data with key/value parameters and metadata. |
Snap Settings
| Parameter Name | Data Type | Description | Default Value | Example | ||||
|---|---|---|---|---|---|---|---|---|
| Label | String | Required. The name for the Snap. You can modify the default name to be more specific and meaningful, especially if you have more than one of the same Snaps in your Pipeline. | Kafka Consumer | Consumer_sales_data | ||||
| Topic | String/Suggestion | Specify the topic from which messages are to be read. | N/A | T1 | ||||
| Partition Number | Integer/Suggestion | Specify the partition number.
| N/A | 2 | ||||
| Group ID | String/Expression | Required. Specify a unique string that identifies the group to which this consumer belongs.
| N/A | people | ||||
| Message Count | Integer/Expression | Specify the number of messages to be read before the consumption process stops.
| -1 | 20 | ||||
| Wait For Full Count | Check box | Activates when you enter a positive integer value or an expression in the Message Count field. Select this check box to enable the Snap to read and process the messages until the specified number in the Message Count field is reached. If you deselect the check box, the Snap terminates when the specified number in the Message Count field is reached, or when all the available messages are read if the number of message is less than the specified count. | Selected | Not Selected | ||||
| Max Poll Records | Integer/Expression | Select or enter the maximum number of records in a batch that is to be returned by a single call to poll.
| 500 | 500 | ||||
| Fetching Timeout | Integer/Expression | Specify the number of milliseconds the Snap must wait to process for a single poll request. If the timeout expires, the Snap polls again for more messages, unless the message count is 0, in which case it stops as expected. | 2000 | 2000 | ||||
| Auto Commit | Check box | Select this check box to enable the Snap to commit offsets automatically as messages are consumed and sent to the output view. If you deselect the Auto Commit check box, the Pipeline must contain one or more Acknowledge Snaps downstream to acknowledge the documents that are output by the Consumer, each of which represents an individual Kafka message, after each document is appropriately processed by the other snaps between the Consumer and Acknowledge Snaps. | Selected | Not Selected | ||||
| Acknowledge Mode | Drop-down list | Activates when you deselect the Auto Commit check box. Select the Acknowledge Mode that determines when the Snap should wait for acknowledgments from the downstream Acknowledge Snaps. The available options are:
| Wait after each record | Wait after each batch of records. | ||||
| Acknowledge Timeout (sec) | Expression/Integer | Activates when you deselect the Auto Commit check box. Enter the maximum number of seconds to wait for a notification from the Acknowledge Snap before committing the offset.
| 10 | 15 | ||||
| Acknowledge Timeout Policy | Drop-down list | Activates when you deselect the Auto Commit check box. Select an Acknowledge Timeout Policy to handle acknowledge timeout errors. The available options are:
| Reprocess | Continue | ||||
| Seek Type | Drop-down list | Specify the starting position where the Consumer Snap should begin reading messages when the Snap is first initialized and executed. The available options are:
| End | Beginning | ||||
| Offset | Expression/String | Activates when you choose the Specify Offset from the Seek Type list. Specify the Offset from which the Consumer should start consuming the message. The Offset is specific to a partition. Hence, when you specify an offset, you must specify the partition number. The offset starts from 0 for any partition. The Consumer can start consuming from any offset in the partition regardless of the messages that have been read earlier. | N/A | 7 | ||||
| Auto Offset Reset | Drop-down list | Select the Auto Offset Reset option from the list. The available options are:
This field is used only if no offsets have been committed for the current partition. | Earliest | Beginning | ||||
| Output Mode | Drop-down list | Activates when you select the Auto Commit field, or when you set Acknowledge Mode to Wait after each batch of records. Select the mode to output the consumed records. The available options are:
| One output document per record | One output document per batch | ||||
| Key Deserializer | Drop-down list | Select the target data type for the deserialized key of each record. The available options are:
| String | Int32 | ||||
| Value Deserializer | Drop-down list | Select the target data type for the deserialized value of each record. The available options are:
| String | Int64 | ||||
| Default Header Deserializer | Drop-down list | Select a Header Deserializer that is to be assigned to the headers that are not configured in the Header Deserializers table. | String | JSON | ||||
Header Deserializers | Use this field set to define the Key and Deserializer for any headers that requires a deserializer other than the Default Header Deserializer. Click
| |||||||
| Key | String/Expression/Drop-down list | Specify a name for header that requires a Deserializer other than the Default Header Deserializer. | N/A | Department | ||||
| Deserializer | String/Drop-down list | Select a Deserializer for the header to convert the header's value to a specific data type such as string or Int32. | String | ByteArray | ||||
| Include Timestamp | Check box | Select this check box to include a timestamp in the metadata of each record that is sent to the output view. A timestamp value is the number of milliseconds that have elapsed since midnight, January 1, 1970 UTC.
| Not selected | Selected | ||||
| Pass Through | Check box | Select this check box to allow the original document to pass through. | Not selected | Selected | ||||
| Snap Execution | Drop-down list | Select one of the three modes in which the Snap executes:
| Validate & Execute | Execute only | ||||
Key Concepts
Consumers and Consumer Groups
To help scale the consumption of messages from a topic, you can split the data that is being read among multiple consumers, which allows a number of consumers to read from a topic. When you use multiple Kafka Consumer instances configured with the same consumer group, each instance is assigned a different subset of partitions in the topic.
For example, if a single Kafka Consumer Snap (c1) subscribes to a topic t1 with four partitions, and c1 is the only consumer in consumer group g1, then c1 gets all the messages from all the four partitions.
If you add a second Kafka Consumer Snap (c2), to the Pipeline within the the same consumer group (g1), the Snap assigns two partitions (for example, 0 and 2) to consumer c1 and two other partitions (for example, 1 and 3) to consumer c2.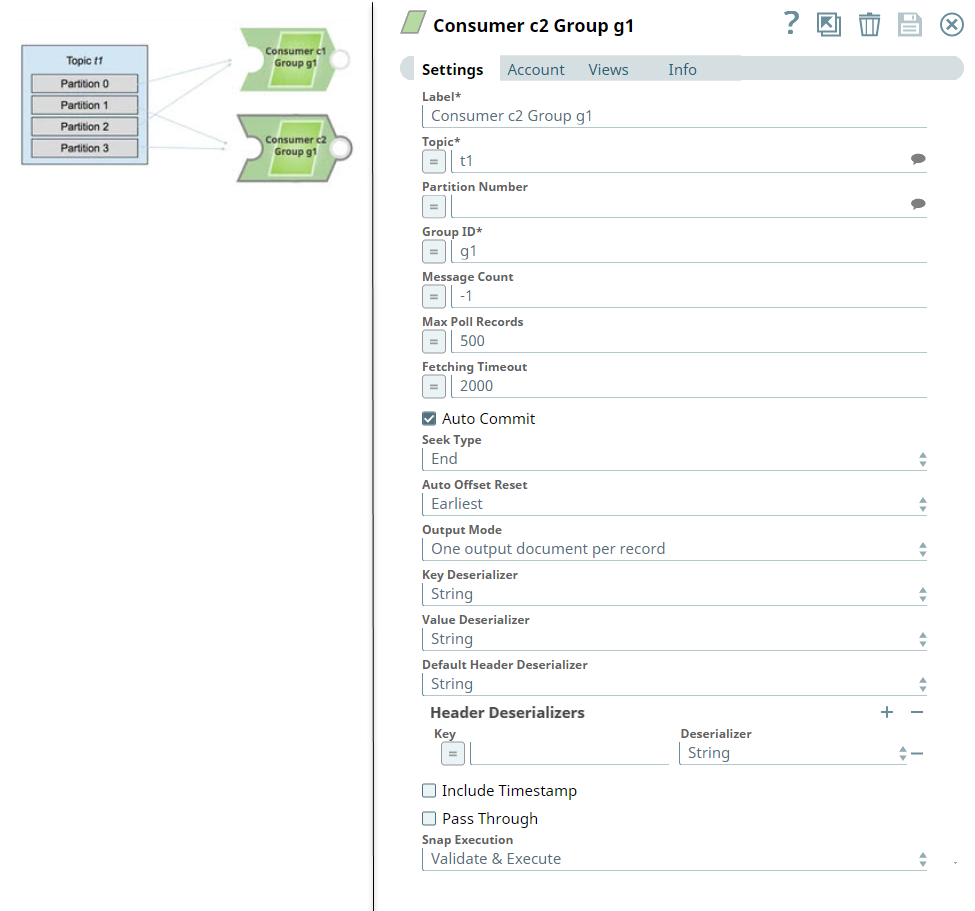
If you add more consumers to a single group, and the number of consumers is more than the number of existing partitions, then some of the consumers remain idle and do not receive messages.
If you add additional consumers to a different consumer group (for example, g2), then those consumers behave independently of those within the consumer group g1.
Consider the following example. For topic t1 with four partitions, four of the five consumers in g1 receive messages, and c5 remains in idle state (because there is no available partition to assign to this consumer). For consumer group g2, consumer c1 receives messages from partitions 0 and 2, and consumer c2 receives messages from partitions 1 and 3.
Therefore, it is important to know how many partitions exist within a topic while adding consumers to consume the messages. 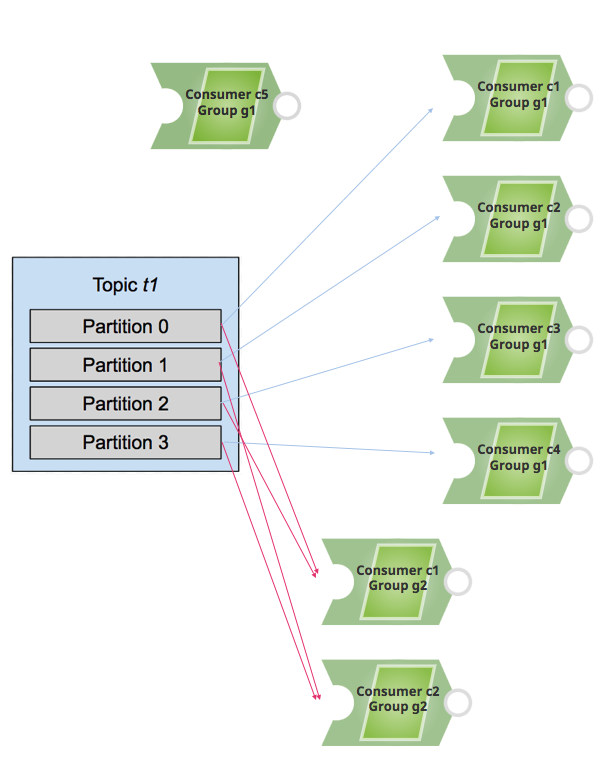
Example
Consuming Messages from a Kafka Topic
This example demonstrates how messages are read from a Kafka topic, and how the selected output documents are sent to the downstream Mapper view.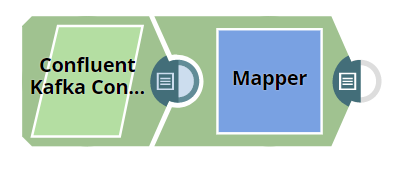
First, we configure the Kafka Consumer Snap to read the messages from the Topic, Sample_Topic, under the Group ID, consumergroup. We select the Output Mode as One output document per batch, because we want to view the output records in batches.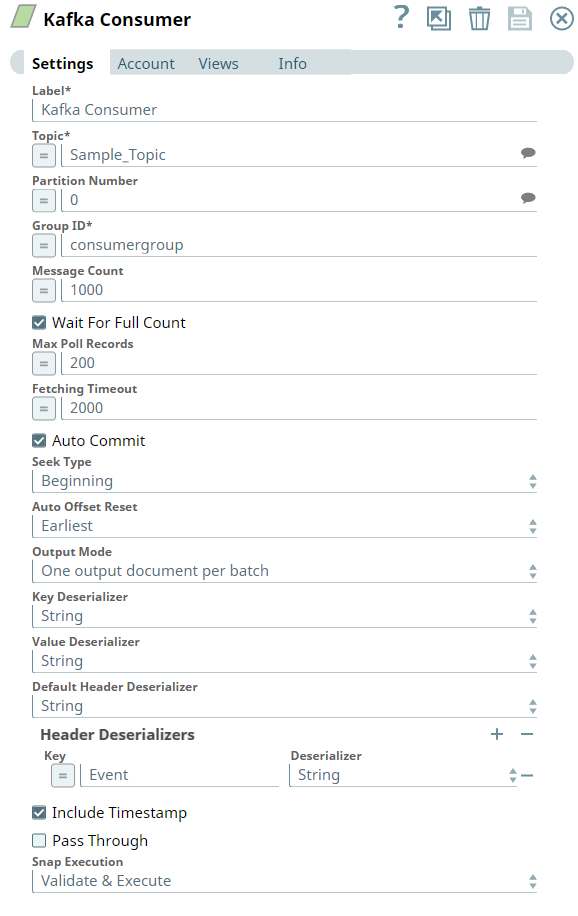
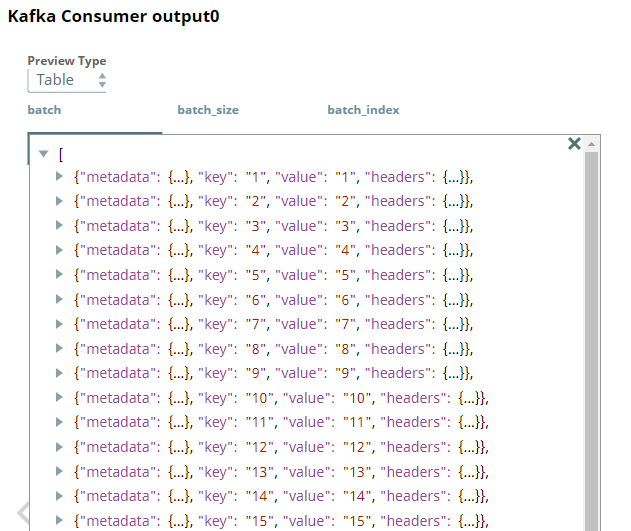
After validation, we can view the output preview of the Kafka Consumer Snap as follows:
| Kafka Consumer Output (Table) | Kafka Consumer Output (JSON) |
|---|---|
|
|

We use the Mapper Snap to display only those fields that we require in the output view. Note that we set the Mapping root to $batch[*] to map the fields of each record in the batch. Hence, we configure the Mapper Snap as shown below: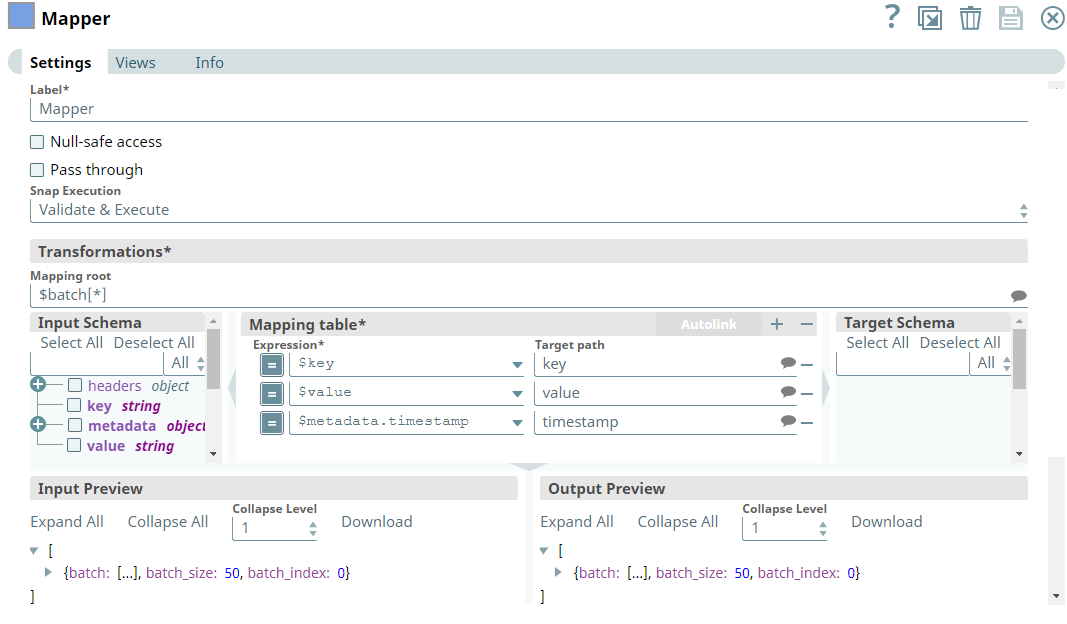
Upon successful execution, we see the output preview of the Mapper Snap as follows: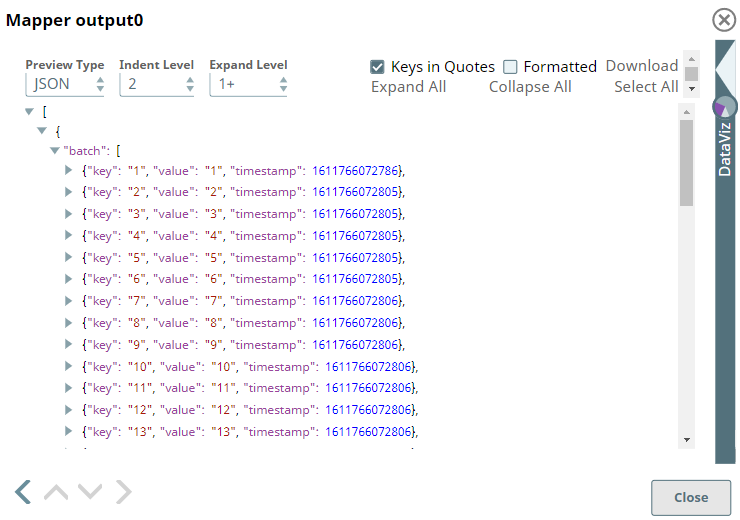
Downloads
| Note |
|---|
Important Steps to Successfully Reuse Pipelines
|
| Attachments | ||
|---|---|---|
|
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|