On this page
| Table of Contents | ||||
|---|---|---|---|---|
|
Snap type: | Write | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Description: | This Snap exports data from Teradata and directly loads it into Hadoop (HDFS).
Valid JSON paths that are defined in the where clause for queries/statements will be substituted with values from an incoming document. Documents will be written to the error view if the document is missing a value to be substituted into the query/statement. If a select query is executed, the query's results are merged into the incoming document and any existing keys will have their values overwritten. On the other hand, the original document is written if there are no results from the query.
| |||||||||||||
| Prerequisites: | Teradata Connector for Hadoop (v1.5.1). See Account for information on the necessary jar file. | |||||||||||||
| Support and limitations: | Works in Ultra Pipelines. | |||||||||||||
| Account: | This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. One additional jar must be added to the JDBC Driver jars on the Teradata account page - the teradata-connector jar from the Teradata Connector to Hadoop (TDCH) package. You can find it by installing the package on one system and looking in the usr/lib/tdch/1.5/lib directory. It would be safest to also use the terajdbc4.jar and tdgssconfig.jars in the same directory unless you have a specific need to use a different version of the jars. See Configuring Teradata Database Accounts for information on setting up this type of account. | |||||||||||||
| Views: |
| |||||||||||||
Settings | ||||||||||||||
Label | Required. The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | |||||||||||||
SQL Statement | Required. SQL statement to execute on the Teradata server. Document value substitution will be performed on literals starting with $ (such as $people.name will be substituted with its value in the incoming document). The Snap does not allow to inject SQL, such as select * from people where $columName = 'abc'. Example: select * from people LIMIT 10 or select * from people where name = $people.name Default value: [None] | |||||||||||||
|
| |||||||||||||
|
| |||||||||||||
| HDFS destination |
| |||||||||||||
Directory | Required. The HDFS directory where the output files will be written. This directory must not already exist. Example: people Default value: hdfs://<hostname>:<port>/ | |||||||||||||
TDCH conversion properties | ||||||||||||||
Separator | Required. Field separator in text file output. The available options are Comma, Tab, Pipe (I). Default value: Comma | |||||||||||||
Number of mappers | The number of mappers to use to export table data from Teradata. The degree of parallelism for these TDCH jobs is defined by the number of mappers (a Snap configuration) used by the MapReduce job. The number of mappers also defines the number of files created in HDFS location. More mappers leads to faster execution, however, the number of mappers is limited by the number of nodes in the cluster and the available bandwidth. Default value: 2 | |||||||||||||
|
| |||||||||||||
Example
In this example pipeline, the Teradata Export to HDFS Snap executes a SQL query and publishes the results to an HDFS directory.

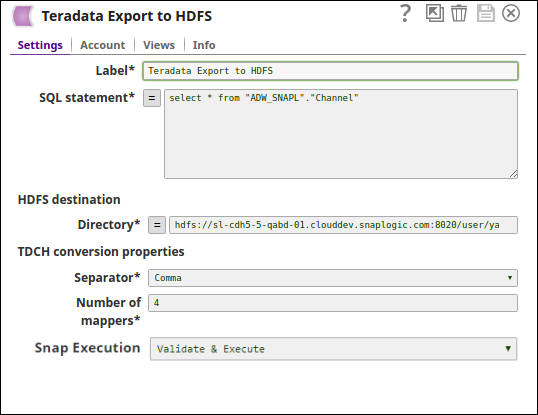
The Teradata Export to HDFS Snap, selects the documents from the table ADW_SNAPL"."Channel" and publishes it to the HDFS destination directory path.
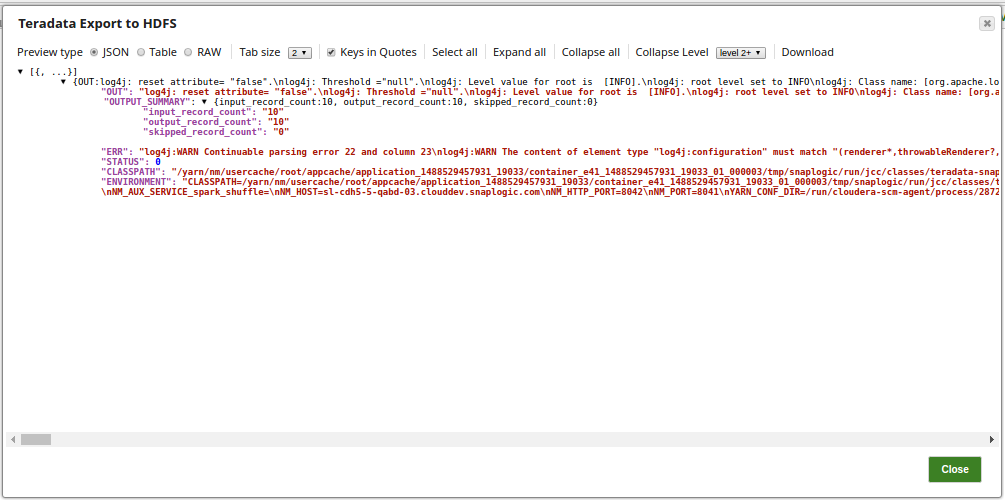
Successful execution of the pipeline displays the below output:
See Also
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|