On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
Overview
Snap type: | Read | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Description: | This Snap unloads the result of a query to a file or files stored on the Snowflake stage, or on an external S3 workspace, or on Azure Storage Blob, if required. The target Snowflake table is not modified. Once the data is unloaded to the storage, users can get the file either using Snowflake GET or S3 file reader. Expected upstream Snaps: Any Snap with a document output view Expected downstream Snaps: Any Snap with a document input view, such as JSON Formatter, Mapper, and so on. The CSV Formatter Snap cannot be connected directly to this Snap since the output document map data is not flat. Expected input: Key-value map data to evaluate expression properties of the Snap Expected output: Document with Snowflake response, query command and the location Url for the unloaded file.
| |||||||||||||
| Prerequisites: |
Security Prerequisites: You should have the following permission in your Snowflake account to execute this Snap:
The following commands enable minimum privileges in the Snowflake Console:
For more information on Snowflake privileges, refer to Access Control Privileges. The below are mandatory when using an external staging location: When using an Amazon S3 bucket for storage:
When using a Microsoft Azure storage blob:
| |||||||||||||
| Internal SQL Commands | This Snap uses the COPY INTO command internally. It enables unloading data from a table (or query) into one or more files in one of the following locations:
| |||||||||||||
| Support and limitations: |
| |||||||||||||
| Account: | This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. This Snap requires a Snowflake Account with S3 or Microsoft Azure properties. See Snowflake Account for information on setting up this type of account. | |||||||||||||
| Views: |
| |||||||||||||
Settings | ||||||||||||||
Label | Required. The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | |||||||||||||
Query | Required. Defines a SELECT query. The results of the query are unloaded. In most cases, it is worthwhile to unload data in sorted order by specifying an ORDER BY clause in the query; this approach will save the time Required. to sort the data when it is reloaded. Example: SELECT * FROM public.company ORDER BY id Default value: None | |||||||||||||
Staging Location | The staging location for the unload. The expected input for this should be a path to a file or filename-prefix. The options available include:
Default value: Internal | |||||||||||||
Target | Required. The staging area where the unloaded file(s) are placed. If the staging location is external, it will be put under the S3 Bucket or Microsoft Azure Storage Blob specified for the Account. If the staging location is internal, the files will be placed in the user’s home folder. Example: TestFolder/file_name_prefix Default value: None | |||||||||||||
| Storage Integration | The pre-defined storage integration is used to authenticate the external stages. Default value: None | |||||||||||||
File Format Type | The format type for the unloaded file. The options available are None, CSV, and CUSTOMIZED.
Default value: None | |||||||||||||
Customized format identifier | The file format object to use for unloading data from the table. The field is valid only when the File format type is specified as Customized. Otherwise, this will be ignored. | |||||||||||||
File format option | Specify the file format option. Separate multiple options by using blank spaces and commas.
Default value: None | |||||||||||||
Copy options | ||||||||||||||
Overwrite | If selected, the UNLOAD overwrites the existing files, if any, in the location where files are stored. If unselected, the option does not remove the existing files or overwrite. Default value: Not selected | |||||||||||||
Generate single file | If selected, the UNLOAD will generate a single file. If it is not selected, the filename prefix needs to be included in the path. Default value: Not selected | |||||||||||||
Max file size | Maximum size (in bytes) of each file to be generated in parallel per thread. The number should be greater than 0, If it is less than or equals 0, the Snap will use the default size for snowflake: 16000000 (16MB). Default value: 0 | |||||||||||||
Encryption type | Specifies the type of encryption to be used on the data. The available encryption options are:
Default value: No default value.
| |||||||||||||
KMS key | The KMS key that you want to use for S3 encryption. For more information about the KMS key, see AWS KMS Overview and Using Server Side Encryption. Default value: No default value.
| |||||||||||||
Include column headings | If selected, the table column heading will be included in the generated files. If multiple files are generated, the heading will be included in every file. Default value: Not selected | |||||||||||||
Validation Mode | This mode is useful for visually verifying the data before unloading it. If this is NONE, validation mode is disabled or, the unloaded data will not be written to the file. Instead, it will be sent as a response to the output. The options available include:
Default value: NONE | |||||||||||||
| Manage Queued Queries | Select this property to decide whether the Snap should continue or cancel the execution of the queued Snowflake Execute SQL queries when you stop the pipeline.
Default value: Continue to execute queued queries when the pipeline is stopped or if it fails | |||||||||||||
|
| |||||||||||||
Troubleshooting
The preview on this Snap will not execute the Snowflake UNLOAD operation. Connect a JSON Formatter and a File Writer Snaps to the error view and then execute the pipeline. If there is any error, you will be able to preview the output file in the File Writer Snap for the error information.
Examples
Unloading Data (Including Binary Data Types) From Snowflake Database
The following example Pipeline demonstrates how you can unload binary data as a file and load it into an S3 bucket.
First, we configure the Snowflake - Unload Snap by providing the following query:
select * from EMP2 – this query unloads data from EMP2 table.
Note that we set the File format option as BINARY_FORMAT='UTF-8' to enable the Snap to pass binary data.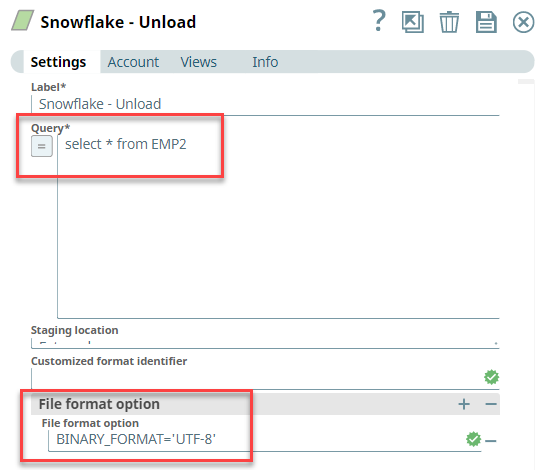
Upon validation, the Snap shows the unloadRequest and unloadDestination in its preview.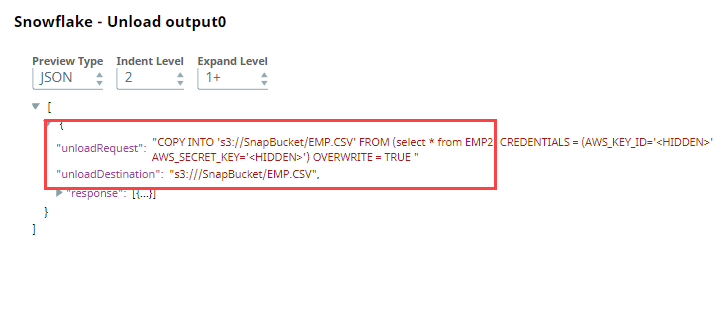
We connect the JSON Formatter Snap to Snowflake - Unload Snap to transform the binary data to JSON format, and finally write this output to a file in S3 bucket using the File Writer Snap. Upon validation, the File Writer Output Snap writes the output (unload request)- the output preview is as shown below.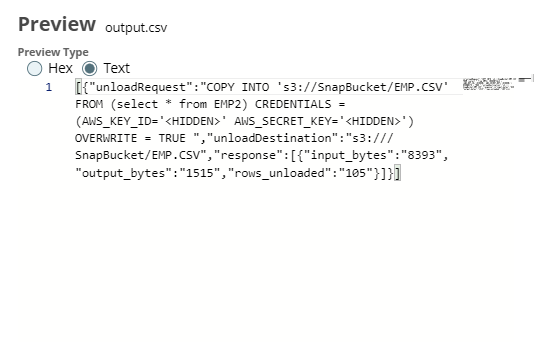
The following example illustrates the usage of the Snowflake Unload Snap.

In this example, we run the Snowflake SQL query using the Snowflake Unload Snap. The Snap selects the data from the table, @ADOBEDATA2 and writes the records to the table, adobedatanullif using the File Writer.
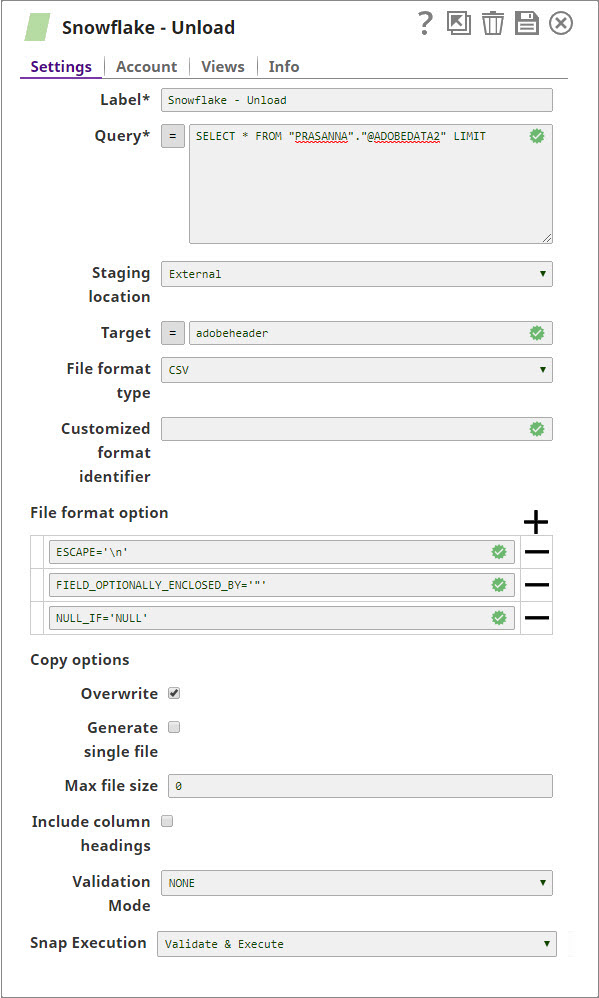
Connect the JSON formatter Snap to convert the predefined CSV file format to JSON and write the data using the File Writer Snap.
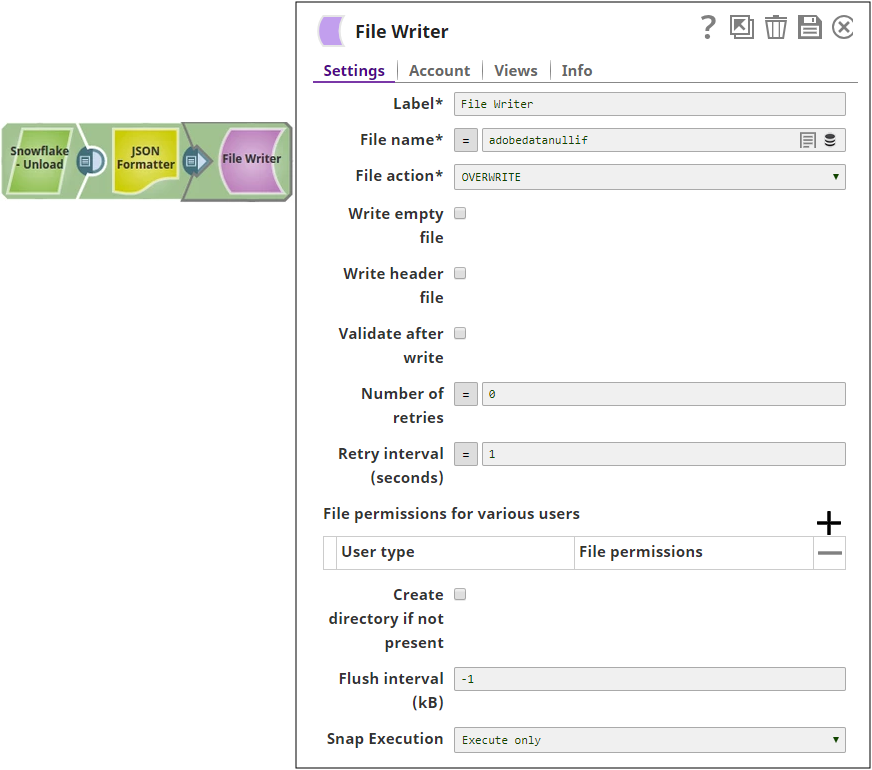
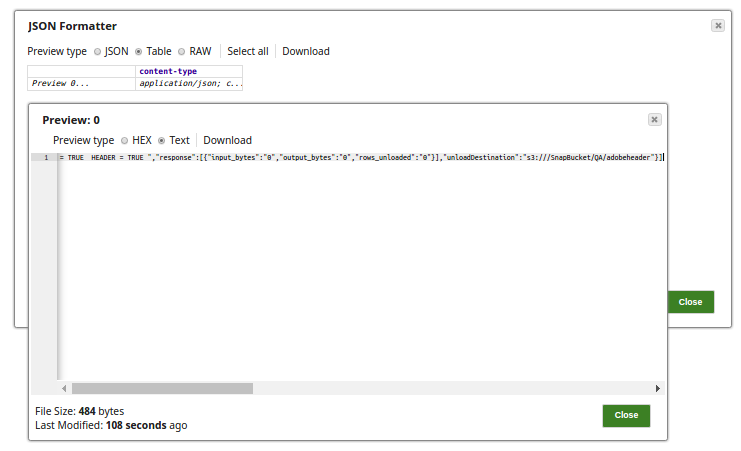
Successful execution of the pipeline gives the below output preview:
| Attachments | ||
|---|---|---|
|
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|