In this article
| Table of Contents | ||||
|---|---|---|---|---|
|
Snap type: | Transform | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Description: | The Snap groups input documents by the field values into batches of output documents. Each batch is an output document with a list of input Map data as a value at the location specified by the Target field property. Input documents with the same group-by field values are grouped into the same output document. The Snap expects the input documents with the same group-by field values are contiguous and whenever the group-by field values changes it produces a new output document. Therefore, if all input documents with the same group-by field values are expected to be grouped into one output document, the Sort Snap can be used in front of the Group By Fields Snap so that the input document stream are sorted by the group-by field values.
| |||||||||||||
| Prerequisites: | All input documents should be of Map data type and contain values specified by the Fields property. | |||||||||||||
| Support and limitations: | Does not work in Ultra Pipelines. | |||||||||||||
| Account: | Accounts are not used with this Snap. | |||||||||||||
| Views: |
| |||||||||||||
Settings | ||||||||||||||
Label | Required. The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | |||||||||||||
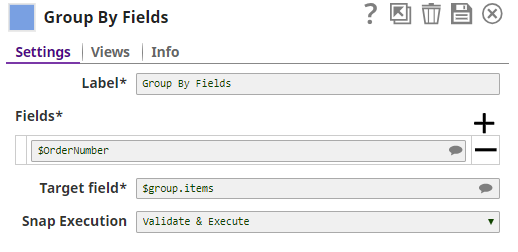
Fields | Required. The fields to group by. Example: $OrderNumber Default value: [None] | |||||||||||||
| Memory Sensitivity | Required. Indicates the Snap's behavior towards memory changes. Choose one of the available options:
Default value: [None] | |||||||||||||
| Min. Part Size | Activated when Memory Sensitivity is set to Dynamic. Enter the minimum part size that you want Snap to split larger groups into multiple parts.
Example: $OrderNumber 100 Default value: [None] 10 | |||||||||||||
Target field | Required. Target field name to be used as a key in the output document or a JSON path where a list of input Map data would be located. Example: 1500batch Default value: 10group | |||||||||||||
|
| |||||||||||||
Examples
| Expand | ||
|---|---|---|
| ||
Input and Output Documents Batched by the Group Name and FieldsIn this pipeline, the Group By Fields Snap groups the input documents into a batch of output documents with the same group by the field property.
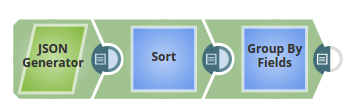
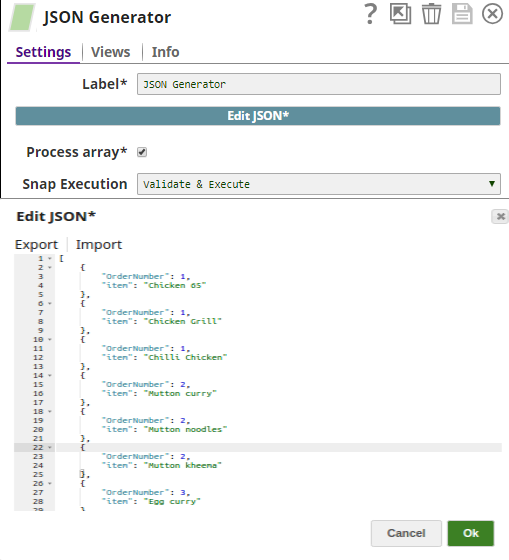
The JSON Generator Snap passes the values to be batched into groups by fields.
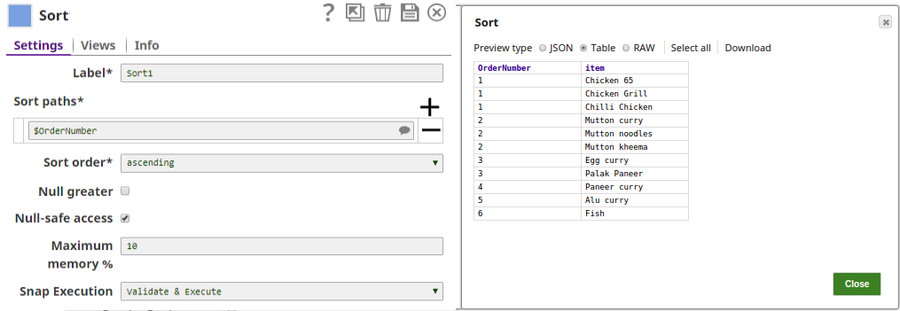
The Sort Snap Sorts the input documents into ascending order, the respective output preview:
The Group By Fields Snap groups the documents by group name and fields.
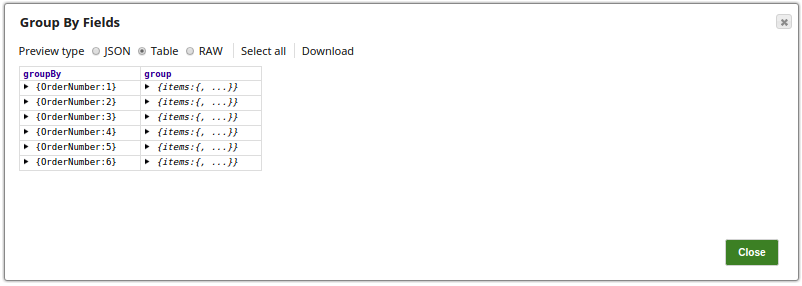
The output preview from the Group By Fields Snap grouped by the order number and the group fields: 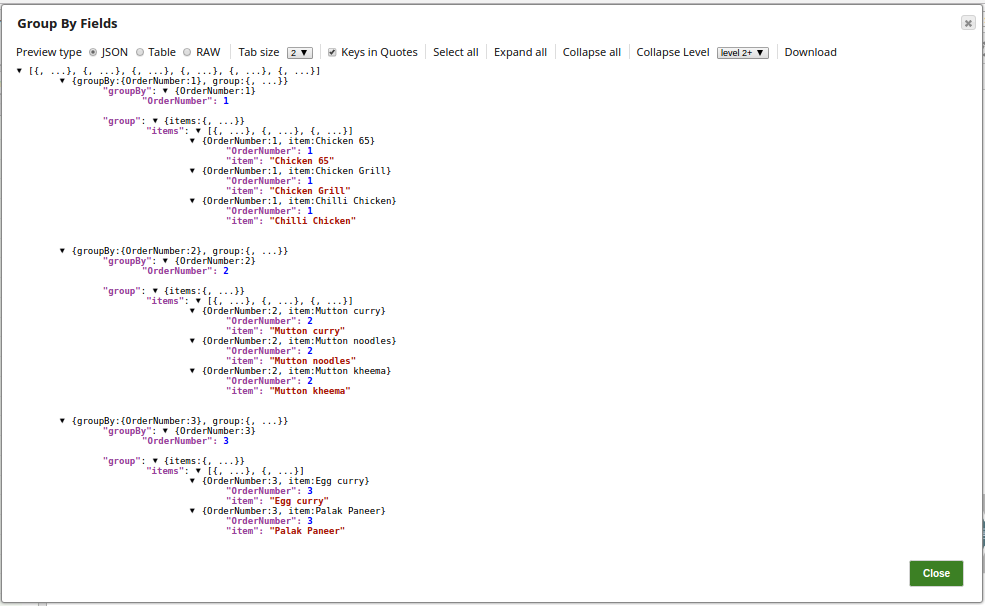 The output preview in the table format:
|
| Expand | ||||
|---|---|---|---|---|
| ||||
Input and Output Documents by CodeAssume an input stream of nine documents as follows:
If we set the Fields property to "$OrderNumber" and the Target field property to "$group.items", there will be four output documents as follows:
|
See Also
https://community.snaplogic.com/t/loop-through-csv-file-before-sending-email/10671
https://community.snaplogic.com/t/group-by-field-behaving-mysteriously/10688- SnapLogic Community Post: Loop through CSV file before sending an email
- SnapLogic Community Post: Group by field behaving mysteriously
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|