On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
| Snap type: | Read | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Description: | This Snap reads the data from the SQL server table on the Azure. ETL Transformations & Data FlowThis Snap enables the following ETL operations/flows: Extracts the complete table data from the SQL Server DB and writes it to a locally created temporary data file. The data is then processed from the data file and written to the output view. Input & Output
Modes
| ||||||||||||
| Prerequisites: | Bulk Extract requires a minimum of SQL Server 2016 to work properly. Must install the BCP utility. | ||||||||||||
Limitations and Known Issues: | None | ||||||||||||
| Configurations: | Account & AccessThis Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See Configuring Azure SQL Accounts for information on setting up this type of account.
Views
| ||||||||||||
Settings | |||||||||||||
Label | Required. The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | ||||||||||||
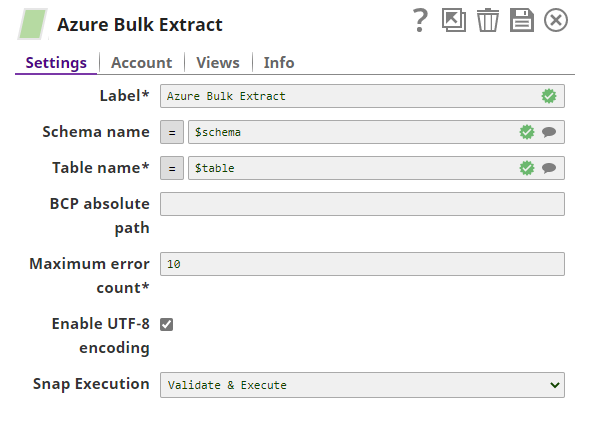
Schema Name | The database schema name. In case it is not defined, then the suggestion for the Table Name will retrieve all tables names from all the schemas. The property is suggestible and will retrieve available database schemas during suggest values.
Example: SYS | ||||||||||||
Table Name | Required. Table on which to execute the bulk load operation.
Example: people Default value: [None]
Examples: Not supported by BCP: "dbo"."sqldemo#^&%$" | ||||||||||||
BCP absolute path | Absolute path of the BCP utility program in JCC's file system. If empty, the Snap will look for it in JCC's environment variable PATH. Default value: [None]
Examples: | ||||||||||||
Maximum error count | Required. The maximum number of rows which can fail before the bulk load operation is stopped. Default value: 10 | ||||||||||||
| Enable UTF-8 encoding | Specify whether UTF-8 coding must be enabled or not. If enabled, the Snap updates the BCP command to support UTF-8 encoded characters. Default value: Selected | ||||||||||||
|
| ||||||||||||
Examples
Basic Use Case
In this pipeline, the Bulk Extract Snap retrieves the data from a table on the Azure Database. The output view in parsed in a JSON format.
Extract: BulkExtract reads the data from the Azure Sql Database.
Transform: JSON Formatter parses the data and converts it into JSON.
.png?version=1&modificationDate=1501874648747&cacheVersion=1&api=v2&height=250)
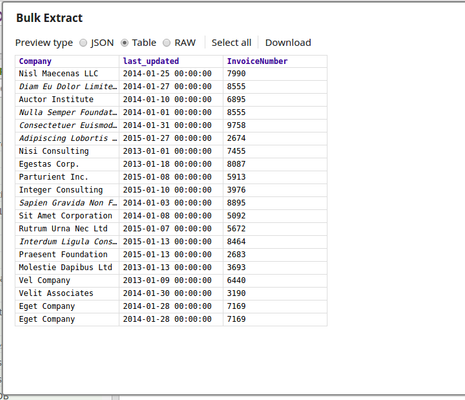
The execution displays the following output:
|
Typical Snap Configurations
The key configurations for the Snap are:
- Without Expression: Directly passing the table name from which the data is extracted.
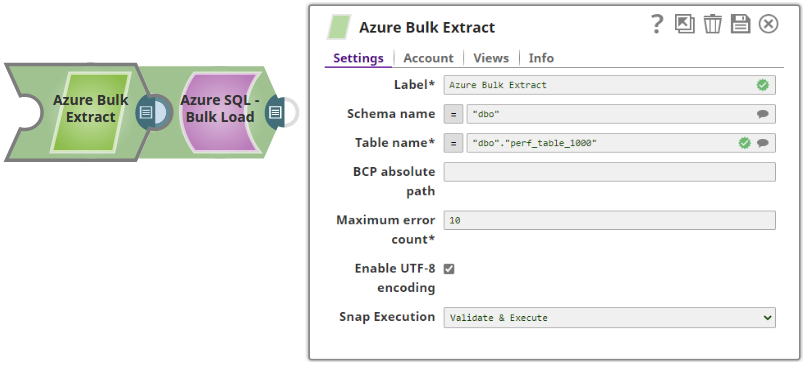
With Expressions
- Query from an upstream Snap: The Mapper Snap passing the required Schema and Table name to the Snap.
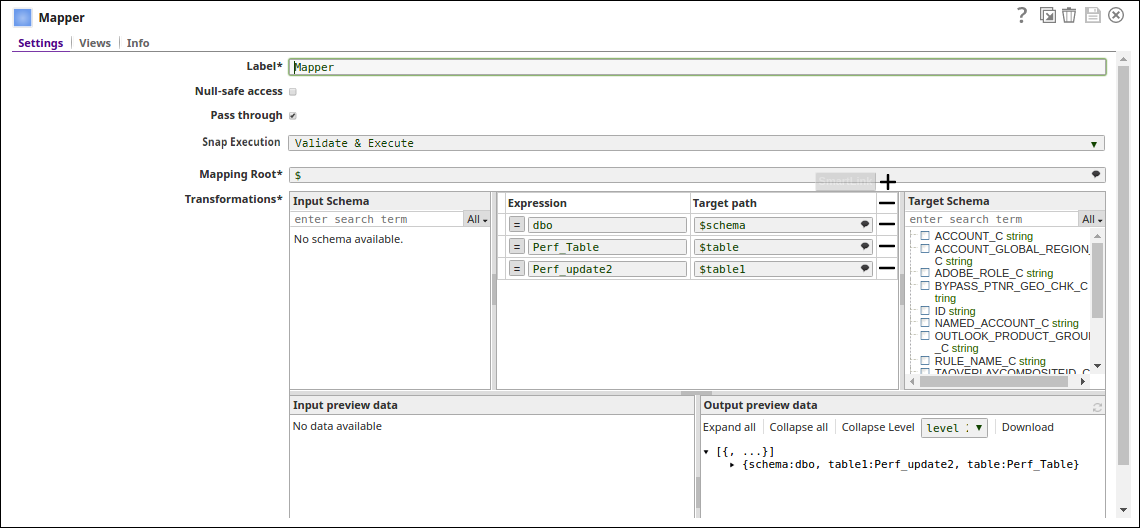
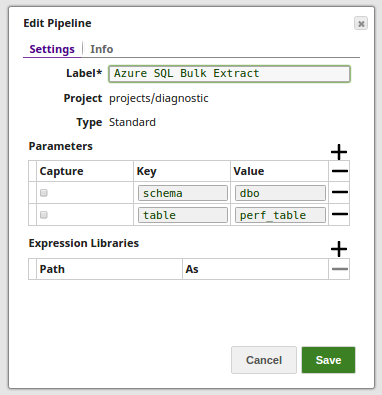
- Pipeline Parameter: Pipeline parameter set to pass the required Schema and Table name to the Snap.
Advanced Use Case
The following describes a pipeline, with a broader business logic involving multiple ETL transformations, that shows how typically in an enterprise environment, Bulk import/read functionality is used.
Pipeline download link is available below.
This pipeline reads and moves data from the Azure SQL database to the Redshift using the Redshift BulkLoad Snap. The data is migrated to Redshift, and the Snap helps in achieving this with high performance and ease of use.
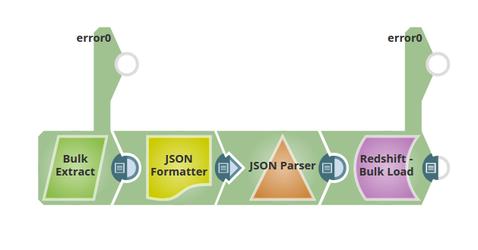
Extract: BulkExtract reads the data from the Azure SQL Database.
Transform: JSON Formatter parses the data and converts it into JSON.
Load: Redshift BulkLoad will loads the data being formatted using the JSON Parser.
Downloads
| Multiexcerpt include macro | ||||
|---|---|---|---|---|
|
| Attachments | ||
|---|---|---|
|
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|