On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
| Warning | ||
|---|---|---|
| ||
Since Adobe Cloud Platform (ACP) is deprecated by Adobe, we are replacing the ACP Snap Pack with the Adobe Experience Platform (AEP) Snap Pack starting from 4.22 GA release. Hence, ACP Read Snap is deprecated in 4.22 release. For more information, see the Adobe Experience Platform Read Snap article. |
Overview
The Adobe Experience Platform Read Snap is a Read type Snap and can be used to read data sets in the Adobe Experience Platform console using information like Dataset ID for a selected data set schema. The Snap supports reading data sets in the following data set schema:
- Profile XSD
- CSV
- Parquet
The Snap accepts document input and generates a document output. Snaps with document input/output view such as Mapper can be used upstream/downstream of the Snap.
Prerequisites
Access to Adobe Experience Platform is required in order to be able to use this Snap.
Configuring Accounts
This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See Configuring Adobe Experience Platform Accounts for information on setting up this type of account.
Configuring Views
Input | This Snap has at most one document input view. |
|---|---|
| Output | This Snap has exactly one document output view. |
| Error | This Snap has at most one document error view and produces zero or more documents in the view. |
Limitations and Known Issues
As of its initial release, the Snap supports only Profile XSD, CSV, and Parquet formats.
Modes
- Ultra Pipelines: Works in Ultra Pipelines.
Snap Settings
| Label | Required. The name for the Snap. Modify this to be more specific, especially if there are more than one of the same Snap in the pipeline. | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dataset schema | This is a drop-down list that lets the user select the schema of the data set that is to be read. The suggestions in Dataset name and Dataset ID are based on this selection. The following options are available in this drop-down menu:
Default value: Parquet | ||||||||||||
| Dataset name | The name of the data set to be read. This is a suggestible field and will provide names of all the data sets within the Account based on the selection in the Dataset schema property. Example: doctest Default value: [None]
| ||||||||||||
| Dataset ID | Required. The data set ID of the data set to be read. This is a suggestible field and will provide IDs of all the data sets within the Account based on the Dataset schema and Dataset nameproperty's configuration. Example: 5acdb87f9iqdrac201da2e0e9 Default value: [None]
| ||||||||||||
| Refresh datasets cache | If selected, the Snap will refresh the cache and show refreshed results. This is handy in cases where changes are made to the data set outside of SnapLogic, such as a new data set created, existing data set deleted, and so on. In such cases, enabling this property will refresh the cache and display updated content. Default value: Not selected.
| ||||||||||||
|
|
Troubleshooting
Snap throws an error when Pipeline execution is done in Cloudplex
To execute Pipelines in a Cloudplex, you must set ALLOW_CLOUDPLEX_PROCESS_CREATION to true in the SnapLogicSecurityManager.java file. Contact SnapLogic Customer Support for help with the setting.
Examples
Reading from Adobe Experience Platform and Writing into SLDB and S3
| Expand | ||
|---|---|---|
| ||
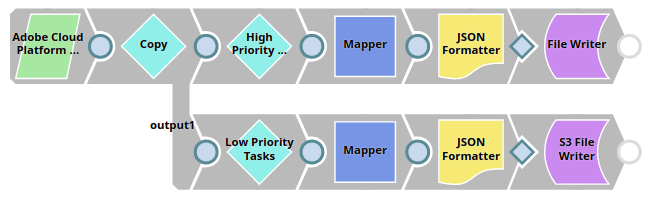
The pipeline below demonstrates the following operations:
The data set is a CSV file in the Adobe Experience Platform, it is a task list containing information such as Assignee, Reporter, Priority, and Resolution. This data is read using the Adobe Experience Platform Read Snap. The Snap is configured as shown below:
The output preview below shows the data set:
This data is filtered using Filter Snaps, the filtering criteria is the Priority - Highest, and Lowest. All tasks with priority Highest are written into the SLDB using the File Writer Snap and all tasks with priority Lowest are written into the S3 storage using the S3 File Writer Snap. The data is written into these Snaps in JSON format using the JSON Formatter Snaps. The File Writer and S3 File Writer Snaps are configured as shown below:
|




Downloads
| Attachments | ||
|---|---|---|
|
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|