On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
Overview
The Shuffle Snap is a a Flow type Snap that enables you to randomize the order of the rows in an incoming dataset. The Snap can be optimized to work with large datasets by configuring the maximum percentage of memory that can be used to buffer the dataset, if that limit is exceeded then the dataset is downloaded to a temporary file in local storage. A random integer can be assigned as the seed value, a seed value is any number that acts as the identifier for a particular randomized order. The Snap produces the same randomized order for the same seed value. This Snap, along with the Sample Snap, is helpful in randomizing a sample dataset for further analysis.
Input and Output
- Expected input: Document containing row data.
- Expected output: Document with randomized row order.
- Expected upstream Snaps: Any Snap that produces a document output containing row-data. For example, CSV Generator, and Mapper.
- Expected downstream Snaps: Any Snap that accepts a document input. For example, Mapper.
Prerequisites
None.
Configuring Accounts
Accounts are not required in this Snap.
Configuring Views
Input | Exactly one document input view. |
|---|---|
| Output | Exactly one document output view. |
| Error | At most one document error view. |
Troubleshooting
None.
Limitations and Known Issues
None.
Modes
- Ultra Pipelines: Does not work in Ultra Pipelines.
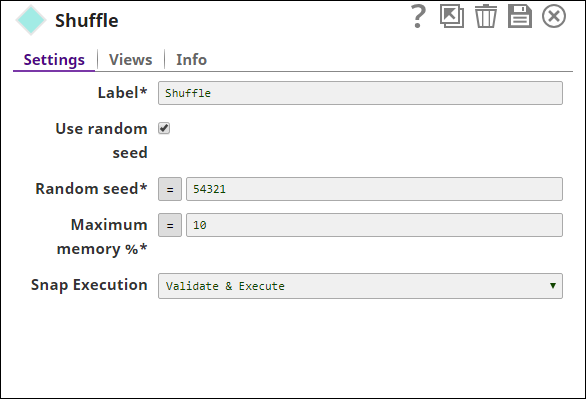
Snap Settings
| Label | Required. The name for the Snap. Modify this to be more specific, especially if there are more than one of the same Snap in the pipeline. | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
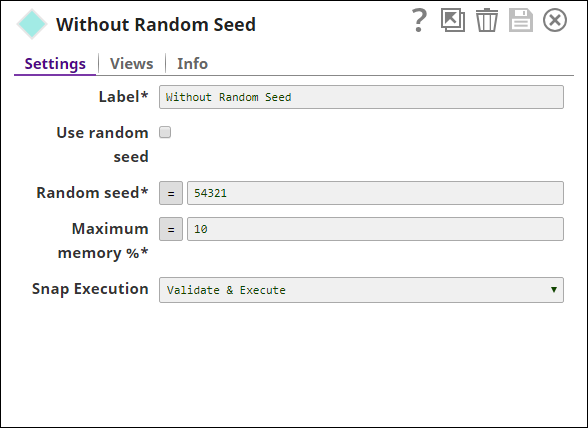
| Use random seed | Select this field to enable using a seed value. The next field is ignored if this field is deselected. Default value: Selected | ||||||||||||
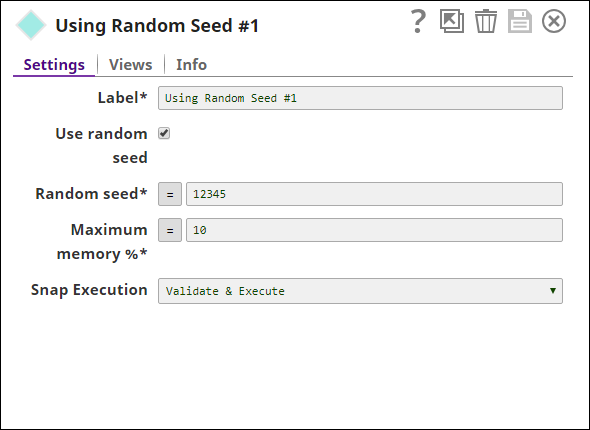
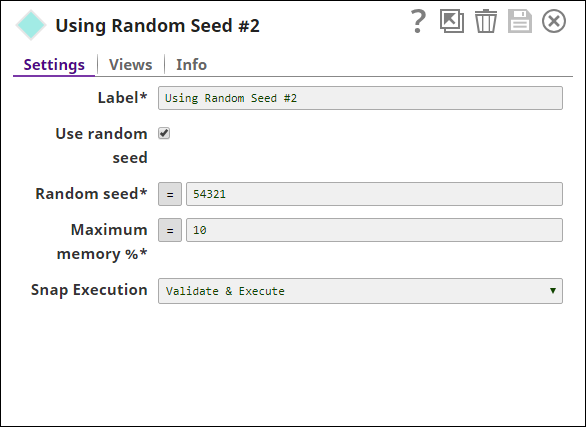
| Random seed | Conditional. This is required if the Use random seed field is selected and specifies the seed value to be used in randomizing the dataset. Using the same seed value for a dataset generates the same order of shuffled dataset. Default value: 12345
| ||||||||||||
| Maximum memory % | Required. The maximum portion of the node's memory, as a percentage, that can be utilized to buffer the incoming dataset. If this percentage is exceeded then the dataset is written to a temporary local file and then the sample generated from this temporary file. This configuration is useful in handling large datasets without over-utilization of the node memory. The minimum default memory to be utilized by the Snap is set at 100 MB. Default value: 10 | ||||||||||||
|
|
Multiexcerpt include macro name Temporary Files page Join
Examples
Shuffling a Numerical Dataset
The Pipeline in this example, Shuffle_Snap_Numerical_Data.slp, demonstrates the core functionality of the Shuffle Snap. An input dataset containing 50 rows is passed to the Shuffle Snap. Three cases are demonstrated:
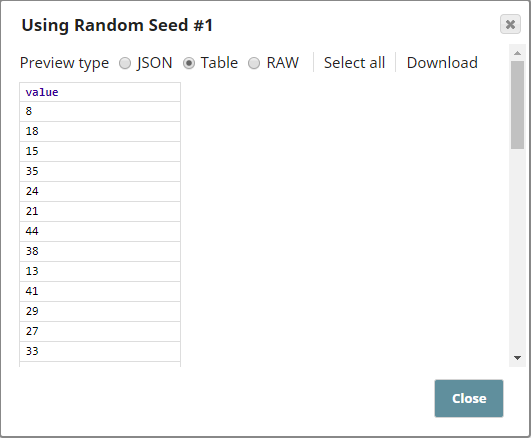
- Using a seed value
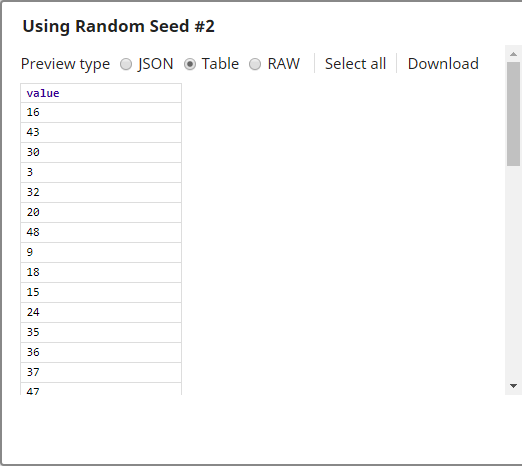
- Using another seed value
- Without seed value
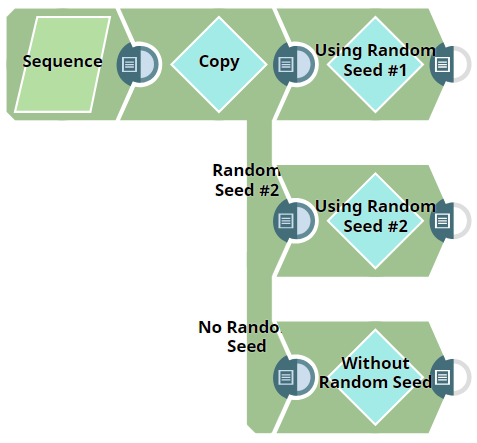
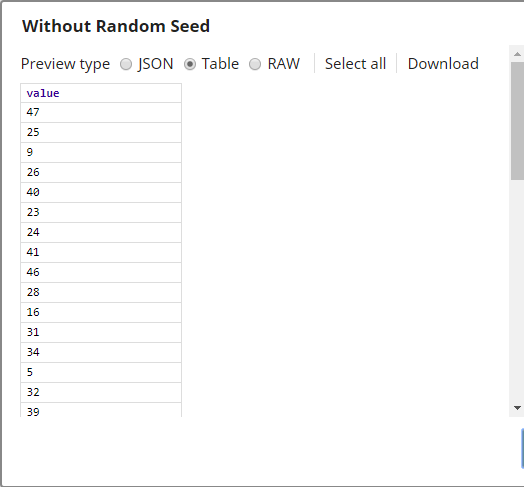
Upon execution, the output document is the input document with the rows in a random order.
Download this pipeline.
| Expand | ||
|---|---|---|
| ||
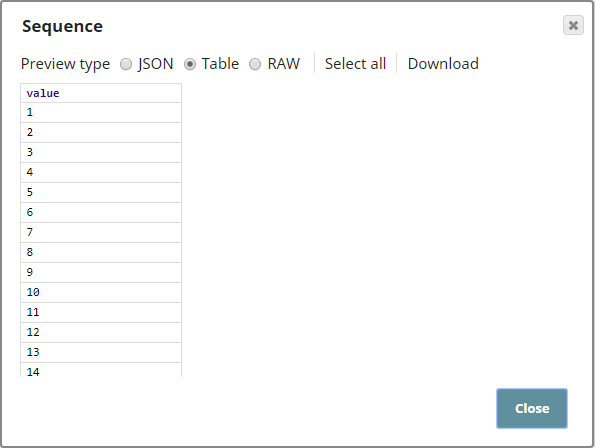
The Sequence Snap simulates a numerical dataset by generating a sequence of 50 numbers as shown below:
Three Shuffle Snaps demonstrate how the Snap works with and without a seed value:
Download this pipeline. |
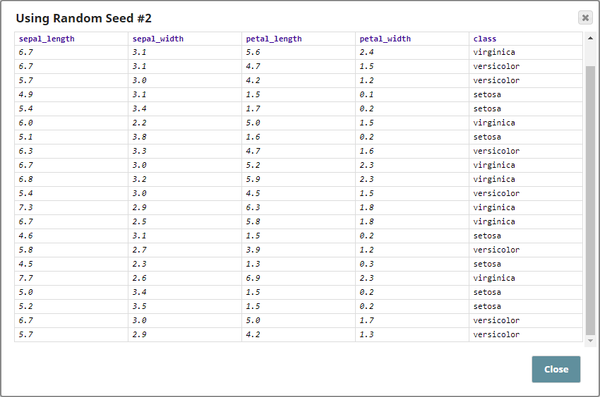
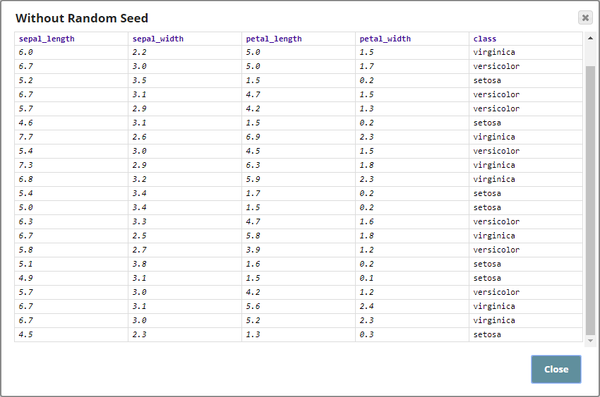
Shuffling a Categorical Dataset
The Pipeline in this example, Shuffle_Snap_Categorical_Data.slp, demonstrates how categorical data or data containing multiple fields is handled by the Shuffle Snap. An input dataset containing 21 rows is passed to the Shuffle Snap. Three cases are demonstrated:
- Using a seed value
- Using another seed value
- Without seed value
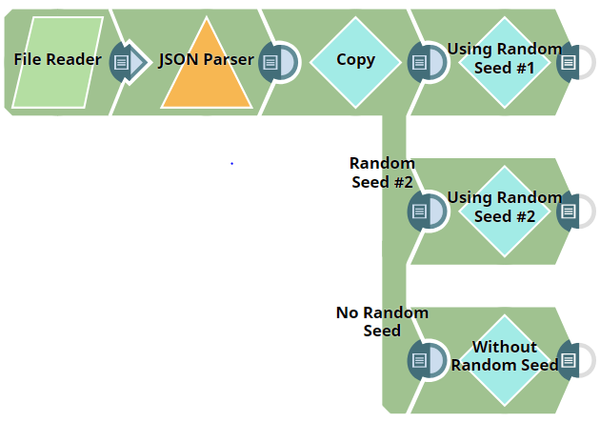
When the Pipeline is executed, the output generated is the incoming dataset but with its order randomized.
Download this pipeline.
| Expand | ||
|---|---|---|
| ||
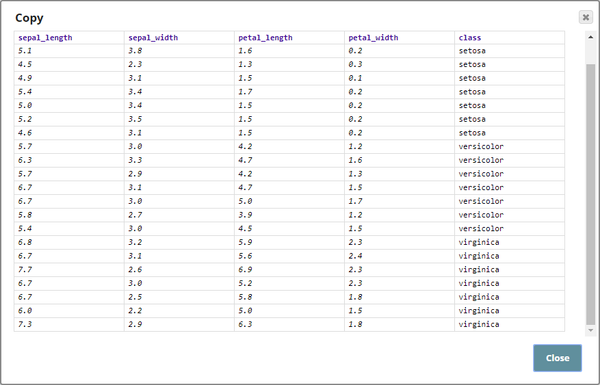
The input is a JSON file containing information about different aspects of 3 species of a flower, aspects such as sepal length, sepal width, petal length, petal width, and classification. 21 records are present in this dataset, sorted based on the $class field as shown below:
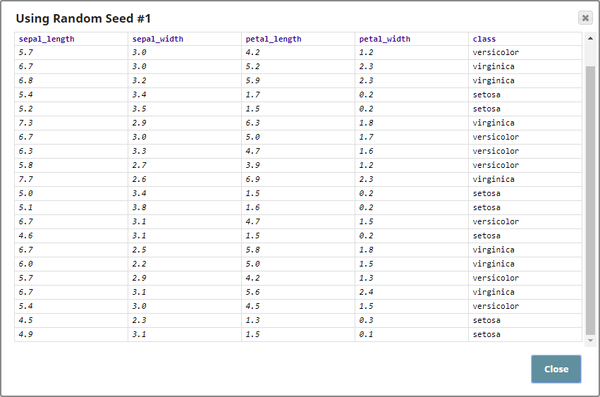
The three Shuffle Snaps are used to demonstrate how the Snap works with and without a seed value. Two different seed values are given to verify the output dataset's row order:
Download this pipeline. |
Downloads
| Multiexcerpt include macro | ||||
|---|---|---|---|---|
|
| Attachments | ||
|---|---|---|
|
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|