On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
| Snap Type: | Write | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Description: | This Snap executes a bulk load of the incoming documents into the Google BigQuery database directly without any intermediary such as Google Cloud Storage. The data is loaded in batches of configurable size. Once a batch is successfully loaded into the target table, the next batch is loaded. The batch load is also subject to a timeout. If the timeout is reached before all the documents in the batch are loaded, the batch is flushed and the next batch's bulk load is started. If the bulk load fails, then the Snap will try to load the batch again after a time delay. Retry occurs for a set number of times. The batch timeout limit, size of a batch, the time delay between retries, and the number of retries are all configurable. ETL Transformations & Data FlowData from the incoming documents is streamed in batches to the destination table. The user can configure Project ID, Dataset ID, and Table ID of the destination. In addition, if the table into which the data is to be loaded does not exist, the Snap can create the table using the configured Table ID. Input & Output
Modes
| ||||||||||||
| Prerequisites: | Write access to the Google BigQuery Account is required. | ||||||||||||
| Limitations and Known Issues | The batch size can be a maximum of 10,000. Known Issue If you copyCopying data by creating a table with the same name in Google BigQuery immediately after deleting it, may not insert the rows as expected. This behavior is due to the way the tables are cached and the internal table ID is propagated throughout the system. Workaround Truncate the
Workaround We recommend you avoid rewriting in Google BigQuery and suggest the following workarounds. You can choose to use them individually or in unison, to suit your requirement.
| ||||||||||||
| Configurations: | Account & AccessThis Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See Google BigQuery Account for information on setting up this type of account. Views
| ||||||||||||
| Troubleshooting: | [None] | ||||||||||||
Settings | |||||||||||||
Label |
| ||||||||||||
| Project ID | Required. Project ID of the project billed for the query. This is a suggestible field and can be populated based on the Account settings. Example: case1234 Default value: [None] | ||||||||||||
| Dataset ID | Required. Dataset ID of the destination table. This is a suggestible field and all the datasets in the specified project will be populated. Example: babynames Default value: [None] | ||||||||||||
| Table ID | Required. Table ID of the destination table. This is a suggestible field and all the tables in the datasets will be listed. Example: customerdata1 Default value: [None] | ||||||||||||
| Create table if not present | Specifies that the table should be created if not already present in the database. Default value: Not selected | ||||||||||||
| Batch size | The number of records batched per request. If the input has 10,000 records , and the batch size is set to 100, the total number of requests would be 100. Default value: 1000 | ||||||||||||
| Batch timeout (milliseconds) | Time in milliseconds to elapse following which the batch if not empty will be processed even though it might be lesser than the given batch size. Default value: 2000
| ||||||||||||
| Batch retry count | The number of times the server should try to load a failed batch. Default value: 0 | ||||||||||||
| Batch retry delay (milliseconds) | Time The time delay between each retry. Default value: 500 | ||||||||||||
|
| ||||||||||||
| Note | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| |||||||||
Google BigQuery tables support columns with NUMERIC with a NUMERIC data type to allow storing big decimal numbers (up to 38 digits with nine decimal places). But Snaps in Google BigQuery Snap Pack that load data into tables cannot create numeric columns. When the Create table if not present check check box is selected, the Snaps create the required table schema, but map big decimals to a FLOAT64 column. So, to store the data into numeric columns using these Snaps, we recommend the following actions:
The Google API converts this string into a number with full precision and saves it in the numeric column. Example:
|
Examples
Basic Use Case
The following pipeline describes how the Snap functions as a standalone Snap in a pipeline:
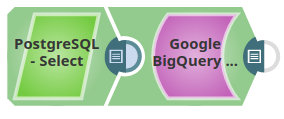
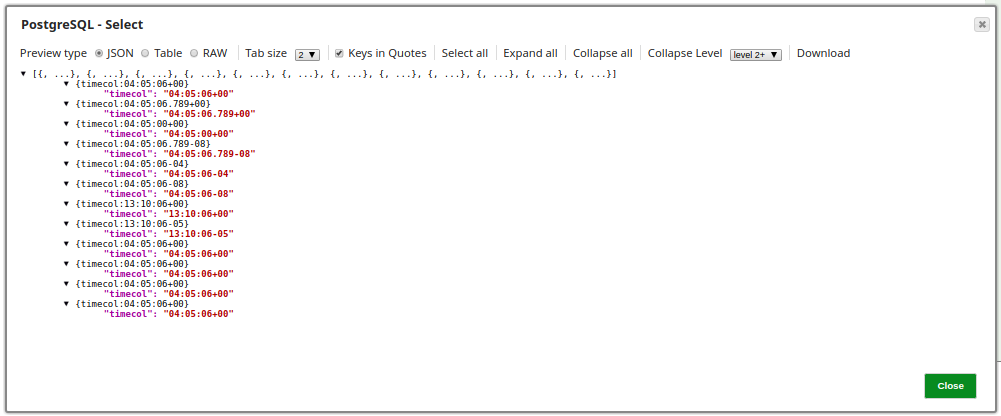
In this example, the Google BigQuery Bulk Load (Streaming) Snap is used to load records from the table snapteam1.postgretimetypes into the target table Atable1 in the babynames dataset within the case16370 project. The input records are provided through the PostgreSQL Select Snap. The input records from the upstream PostgreSQL Select Snap are shown below:
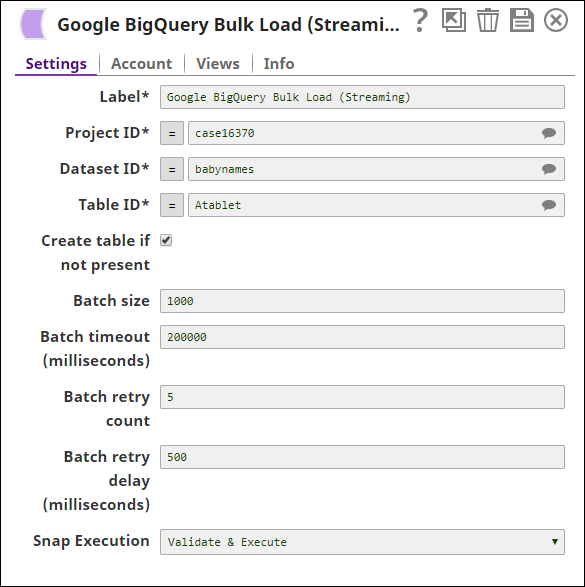
The Google BigQuery Bulk Load (Streaming) Snap's configuration is as shown below:
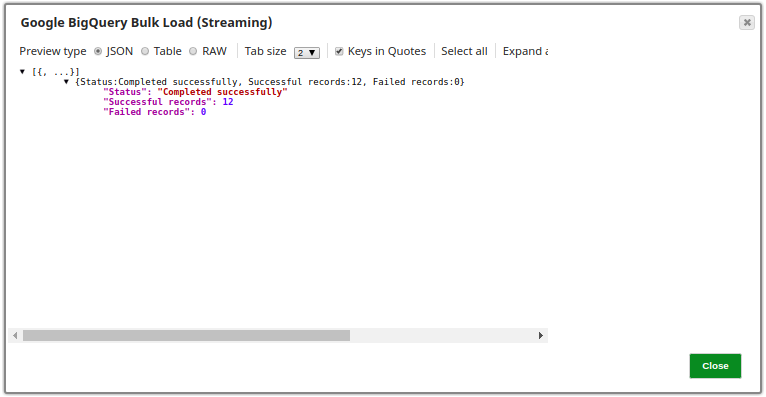
The following is a preview of the output from the Snap:
The exported pipeline is available in the Downloads section below.
Typical Snap Configurations
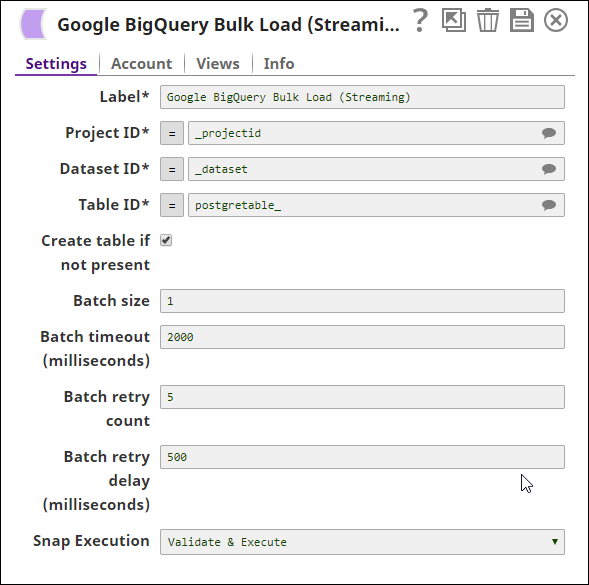
The key configuration of the Snap lies in how the values are passed. There are two ways of passing values:
- Without expressions: The values are passed in the Snap directly.
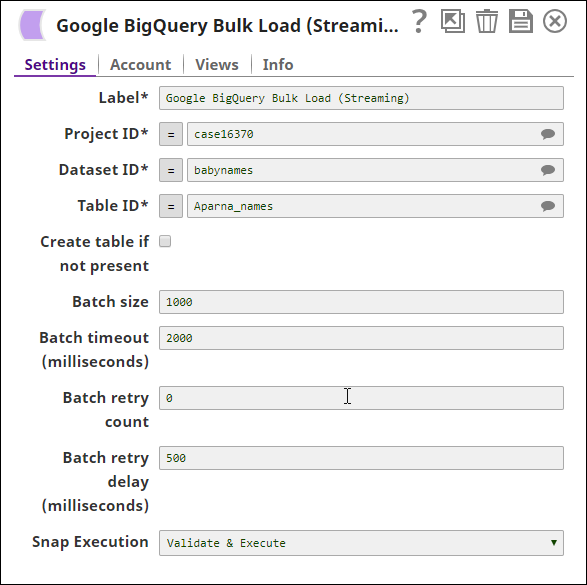
- With expressions
- Using Pipeline parameters: Values are passed in the Snap as pipeline parameters. Select the parameters to be applied by enabling the corresponding checkbox under the Capture column.
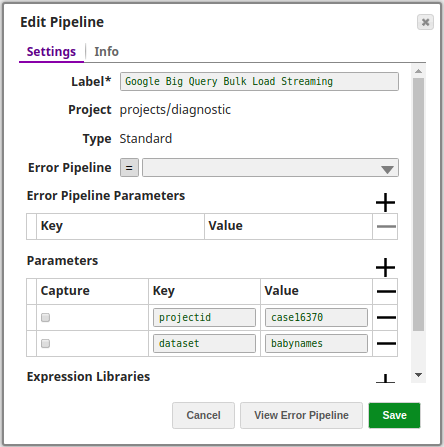
Advanced Use Case
The following describes a pipeline with a broader business logic involving multiple ETL transformations. It shows how, in an enterprise environment, Bulk Load functionality can typically be used.
This pipeline moves records from a SQL Server instance to the Google BigQuery instance, that which is on-premise data migration to the cloud environment.
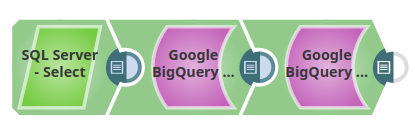
- Extract: Records are extracted from the SQL Server instance by the SQL Server - Select Snap.
- Load: The extracted records from the SQL Server Snap are loaded by the Google BigQuery Bulk Load (Streaming) Snap into the destination table.
- Extract: The Google BigQuery Execute Snap extracts the records inserted into the destination table by the Google BigQuery Bulk Load (Streaming) Snap.
The exported pipeline is available in the Downloads section below.
Downloads
| Attachments | ||||
|---|---|---|---|---|
|
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|