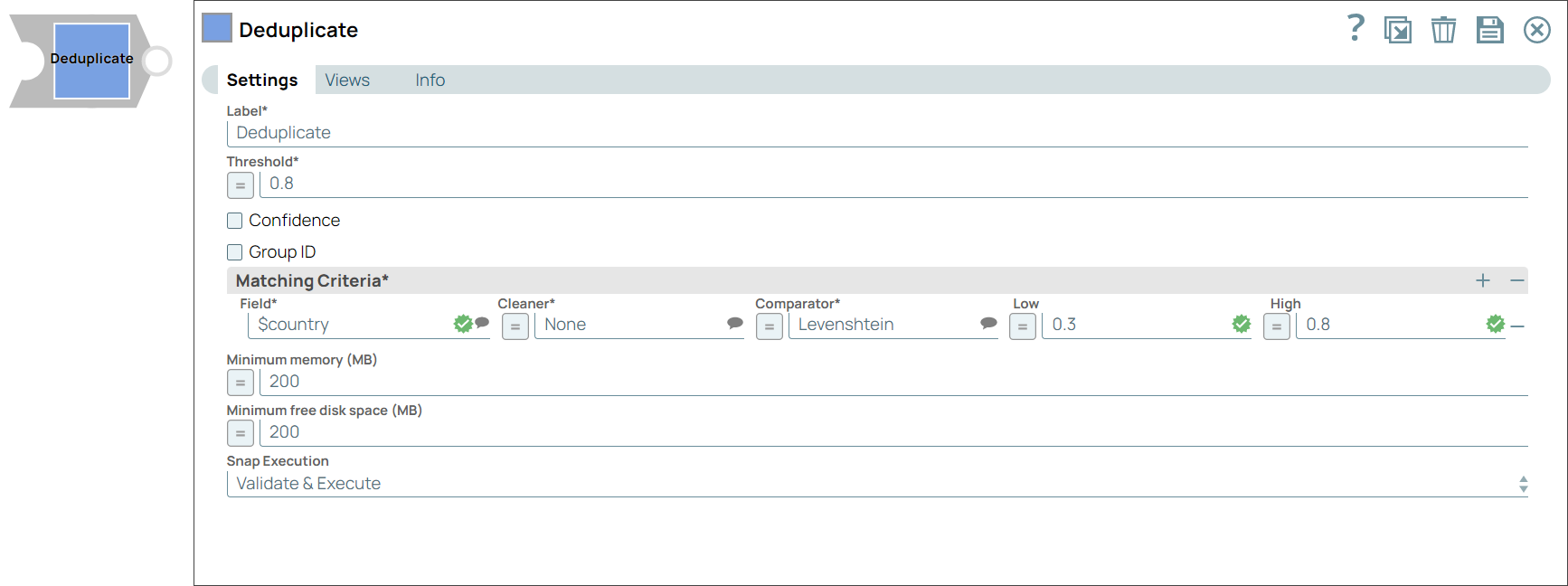
You can use this Snap to remove duplicate records from input documents. When you use multiple matching criteria to deduplicate your data, the Snap evaluates using each criterion separately, and then aggregates to give the final result. This Snap ignores fields with empty strings and whitespaces as no data.
Prerequisites
None.
Limitations
None.
Known Issues
The Deduplicate Snap fails to deduplicate data when the input document contains an empty string, white spaces, or null values in a field.
Support for Ultra Pipelines
Does not support Ultra Pipelines.
Snap Views
Type
Format
Number of Views
Examples of Upstream and Downstream Snaps
Description
Input
Document
Min: 1
Max: 1
Mapper
Copy
Numeric to Categorical
A document with data containing duplicate records.
Output
Document
Min: 1
Max: 2
Filter
Shuffle
Principal Component Analysis
First output view: Required. A document containing deduplicated records.
Second output view: Displays a document containing the duplicate records.
Snap Settings
Parameter Name
Data Type
Description
Default Value
Example
Label
String
Specify a unique name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your Pipeline.
N/A
Deduplicate Office Names
Threshold
Decimal
Required. The minimum confidence required for documents to be considered matched as duplicates using the matching criteria.
Minimum Value: 0
Maximum Value: 1
0.8
0.95
Confidence
Checkbox
Select this check box to include each match's confidence levels in the output.
Deselected
N/A
Group ID
Checkbox
Select this check box to include the group ID for each record in the output.
Deselected
N/A
Matching Criteria
Fieldset
Enables you to specify the settings that you want to use to match input documents with the matching criteria.
The field in the input dataset that you want to use for matching and identifying duplicates.
N/A
$name
Cleaner
String
Select the cleaner that you want to use on the selected fields.
A cleaner makes comparison easier by removing variations from data, which are not likely to indicate genuine differences. For example, a cleaner might strip everything except digits from a ZIP code. Or, it might normalize and lowercase text.
Depending on the nature of the data in the identified input fields, you can select the kind of cleaner you want to use from the options available:
None
Text
Number
Date Time
None
Text
Comparator
String
A comparator compares two values and produces a similarity indicator, which is represented by a number that can range from 0 (completely different) to 1 (exactly equal).
Choose the comparator that you want to use on the selected fields, from the drop-down list:
Levenshtein: Calculates the least number of edit operations (additions, deletions, and substitutions) required to change one string into another.
Weighted Levenshtein: Calculates the least number of edit operations (additions, deletions, and substitutions) required to change one string into another. Each type of symbol has a different weight: number has the highest weight, while punctuation has the lowest weight. This makes "Main Street 12" very different from "Main Street 14", while "Main Street 12" is quite similar to "MainStreet12".
Longest Common Substring: Identifies the longest string that is a substring of both strings.
Q-Grams: Breaks a string into a set of consecutive symbols; for example, 'abc' is broken into a set containing 'ab' and 'bc'. Then, the ratio of the overlapping part is calculated.
Exact: Identifies and classifies a match as either an exact match or not a match at all. An exact match assigns a score that equals the value in High. Else, it assigns a score that equals the value in Low.
Soundex: Compares strings by converting them into Soundex codes. These codes begin with the first letter of the name, followed by a three-digitcode that represents the first three remaining consonants. The letters A, E, I, O, U, Y, H, and W are not coded. Thus, the names 'Mathew' and 'Matthew' would generate the same Soundex code: M-300. This enables you to quickly identify strings that refer to the same person or place, but have variations in their spelling.
Metaphone: Metaphone is similar to Soundex; only it improves on theSoundexalgorithm by using information about variations and inconsistencies in English spelling and pronunciation to produce a more accurate encoding.
Numeric: Calculates the ratio of the smaller number to the greater.
Date Time: Computes the difference between two date-time data and produces a similarity measure ranging from 0.0 (meaning completely different) and 1.0 (meaning exactly equal). This property requires data in epoch format. If the date-time data in your dataset is not in epoch format, you must select Date Time in the Cleaner property to convert the date-time data into the epoch format.
Levenshtein
Numeric
Low
Decimal
A decimal value representing the level of probability of the input documents to be matched if the specified fields are completely unlike.
If this value is left empty, a value of 0.3 is applied automatically.
N/A
0.1
High
Decimal
A decimal value representing the level of probability of the input documents to be matched if the specified fields are a complete match.
If this value is left empty, a value of 0.95 is applied automatically.
NA
0.8
Minimum memory (MB)
Integer/Expression
Specify a minimum cut-off value for the memory the Snap must use when processing the documents. If the available memory is less than the specified value, the Snap stops execution and displays an exception to prevent the system from running out of memory.
This feature is disabled if this value is 0.
A lint message for the available memory and free disk space is displayed in the Pipeline Execution Statistics.
200
1000
Minimum free disk space (MB)
Integer/Expression
Specify the minimum free disk space required for the Snap to execute. If the free disk space is less the than the specified value, the Snap stops execution and displaysan exception to prevent the system from running out of disk space.
This feature is disabled if this value is 0.
A lint message for the available memory and free disk space is displayed in the Pipeline Execution Statistics.
200
1000
Snap Execution
String
Specifies the execution type:
Validate & Execute: Performs limited execution of the Snap (up to 50 records) during Pipeline validation; performs full execution of the Snap (unlimited records) during Pipeline execution.
Execute only: Performs full execution of the Snap during Pipeline execution; does not execute the Snap during Pipeline validation.
Disabled: Disables the Snap and, by extension, its downstream Snaps.
Validate & Execute
N/A
Temporary Files
During execution, data processing on Snaplex nodes occurs principally in-memory as streaming and is unencrypted. When larger datasets are processed that exceeds the available compute memory, the Snap writes Pipeline data to local storage as unencrypted to optimize the performance. These temporary files are deleted when the Snap/Pipeline execution completes. You can configure the temporary data's location in the Global properties table of the Snaplex's node properties, which can also help avoid Pipeline errors due to the unavailability of space. For more information, see Temporary Folder in Configuration Options.
Examples
Deduplicating the List of Childhood Centers in Chicago
In this example, you deduplicate the data in a CSV file containing a list of childhood centers in Chicago.
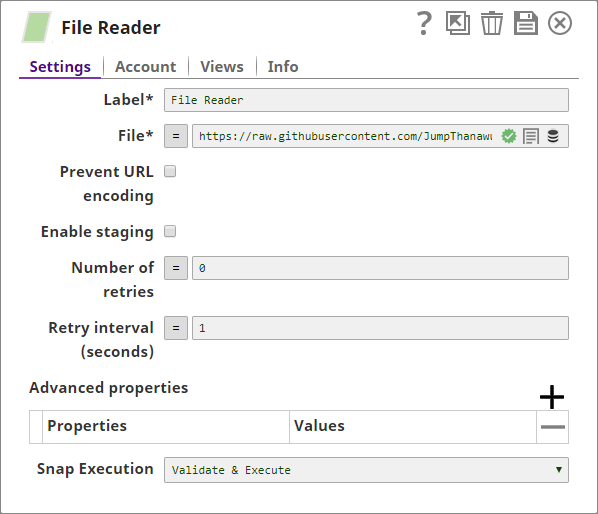
You add a File Reader Snap to the Pipeline and configure it to read the source CSV file stored online:
The File Reader Snap displays the contents of the file, which contains many duplicate entries:
You add a CSV Parser Snap to the Pipeline to interpret the input data as a CSV document.
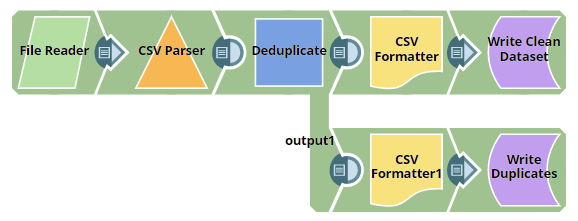
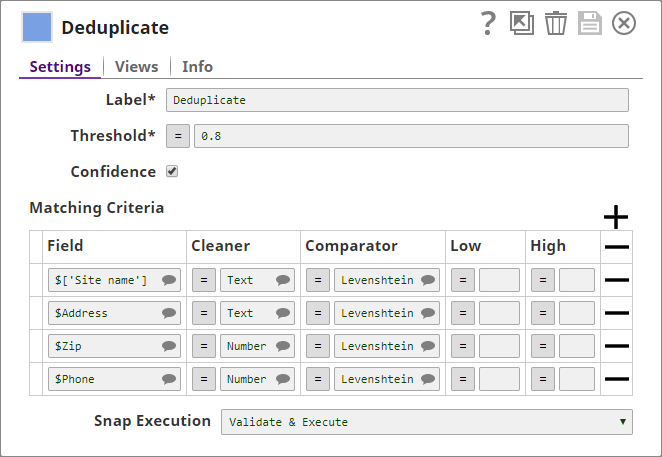
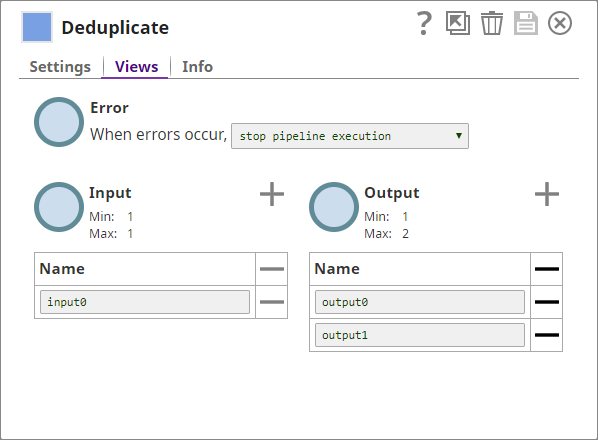
You add a Deduplicate Snap to the Pipeline and configure it to use the name, address, ZIP, and phone details in the input document as fields for deduplication:
You also add an additional output view to the Snap, where the Snap can display the duplicate data. Now, the Snap has two output views, one for the cleaned (deduplicated) data, and another for the duplicated records that the Snap filtered out.
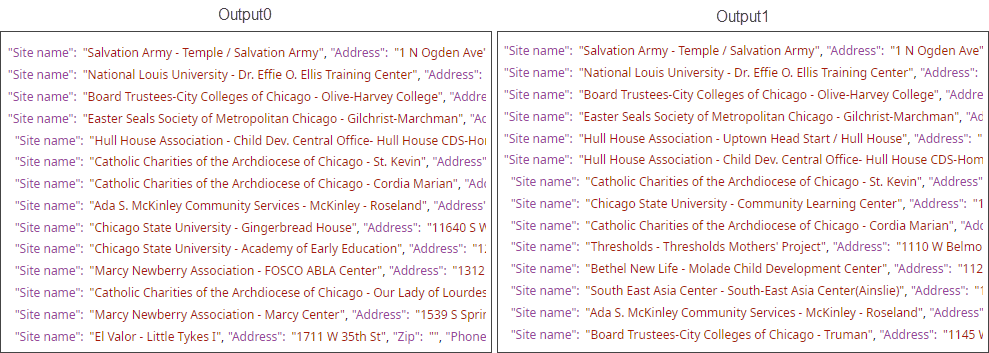
The Snap, when executed, offers the following two output documents (Output0 and Output1). Output0 contains the deduplicated data, while Output1 contains the duplicate data:
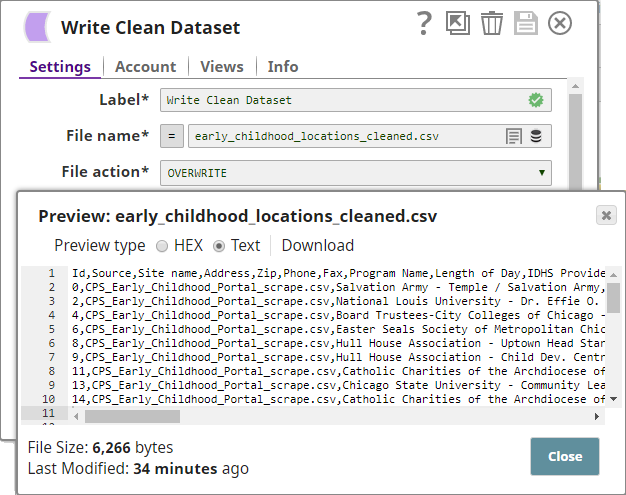
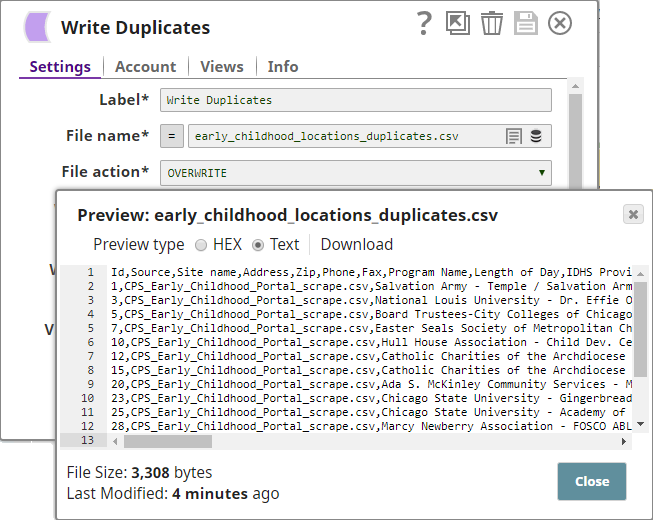
You attach a CSV Formatter Snap to each output view of the Deduplicate Snap to structure the outputs as CSV documents. You then connect a File Writer Snap to each CSV Formatter Snap to write the input data as files.
The Pipeline, when run, generates two output documents: one containing deduplicated data, and the other containing the duplicate data:
Enhanced the Deduplicate Snap to honor an interrupt while waiting in the delay loop to manage the memory efficiently.
February 2024
main25112
Stable
Updated and certified against the current SnapLogic Platform release.
November 2023
main23721
Nov 8, 2023
Stable
Updated and certified against the current SnapLogic Platform release.
August 2023
main22460
Aug 16, 2023
Stable
Updated and certified against the current SnapLogic Platform release.
May 2023
433patches21572
Latest
The Deduplicate Snap now manages memory efficiently and eliminates out-of-memory crashes using the following fields:
Minimum memory (MB)
Minimum free disk space (MB)
May 2023
433patches21247
Latest
Fixed an issue with the Match Snap where a null pointer exception was thrown when the second input view had fewer records than the first.
May 2023
main21015
Stable
Upgraded with the latest SnapLogic Platform release.
February 2023
main19844
Stable
Upgraded with the latest SnapLogic Platform release.
December 2022
431patches19268
Latest
The Deduplicate Snap now ignores fields with empty strings and whitespaces as no data.
November 2022
main18944
Stable
Upgraded with the latest SnapLogic Platform release.
August 2022
main17386
Stable
Upgraded with the latest SnapLogic Platform release.
4.29
main15993
Stable
Upgraded with the latest SnapLogic Platform release.
4.28
main14627
Stable
Enhanced the Type Converter Snap with the Fail safe upon execution checkbox. Select this checkbox to enable the Snap to convert data with valid data types, while ignoring invalid data types.
4.27
427patches13730
Enhanced the Type Converter Snap with the Fail safe upon executioncheckbox. Select this checkbox to enable the Snap to ignore invalid data types and convert data with valid data types.
4.27
427patches13948
Latest
Fixed an issue with the Principal Component Analysis Snap, where a deadlock occurred when data is loaded from both the input views.
4.27
main12833
Stable
Upgraded with the latest SnapLogic Platform release.
4.26
main11181
Stable
Upgraded with the latest SnapLogic Platform release.
4.25
425patches10994
Fixed an issue when the Deduplicate Snap where the Snap breaks when running on a locale that does not format decimals with Period (.) character.
4.25
main9554
Stable
Upgraded with the latest SnapLogic Platform release.
4.24
main8556
Stable
Upgraded with the latest SnapLogic Platform release.
4.23
main7430
Stable
Upgraded with the latest SnapLogic Platform release.
4.22
main6403
Stable
Upgraded with the latest SnapLogic Platform release.
4.21
snapsmrc542
Stable
Introduces the Mask Snap that enables you to hide sensitive information in your dataset before exporting the dataset for analytics or writing the dataset to a target file.
Enhances theMatch Snap to add a new field,Match all, which matches one record from the first input with multiple records in the second input. Also, enhances theComparatorfield in the Snap by adding one more option,Exact, which identifies and classifies a match as either an exact match or not a match at all.
Enhances the DeduplicateSnap to add a new field,Group ID, which includes the Group ID for each record in the output. Also, enhances theComparatorfield in the Snap by adding one more option,Exact, which identifies and classifies a match as either an exact match or not a match at all.
Enhances the SampleSnap by adding a second output view which displays data that is not in the first output. Also, a new algorithm type,Linear Split, which enables you to split the dataset based on the pass-through percentage.
4.20 Patch
mldatapreparation8771
Latest
Removes the unused jcc-optionaldependency from the ML Data Preparation Snap Pack.
4.20
snapsmrc535
Stable
Upgraded with the latest SnapLogic Platform release.
4.19
snapsmrc528
Stable
New Snap: Introducing the Deduplicate Snap. Use this Snap to remove duplicate records from input documents. When you use multiple matching criteria to deduplicate your data, it is evaluated using each criterion separately, and then aggregated to give the final result.
4.18
snapsmrc523
Stable
Upgraded with the latest SnapLogic Platform release.
4.17 Patch
ALL7402
Latest
Pushed automatic rebuild of the latest version of each Snap Pack to SnapLogic UAT and Elastic servers.
4.17
snapsmrc515
Latest
New Snap: Introducing the Feature Synthesis Snap, which automatically createsfeatures out of multiple datasets that share a one-to-one or one-to-many relationship with each other.
New Snap: Introducing the Match Snap, which enables you to automatically identify matched records across datasets that do not have a common key field.
Added the Snap Execution field to all Standard-mode Snaps. In some Snaps, this field replaces the existing Execute during preview check box.
4.16
snapsmrc508
Stable
Added a new Snap, Principal Component Analysis, which enables you to perform principal component analysis (PCA) on numeric fields (columns) to reduce dimensions of the dataset.
4.15
snapsmrc500
Stable
New Snap Pack. Perform preparatory operations on datasets such as data type transformation, data cleanup, sampling, shuffling, and scaling. Snaps in this Snap Pack are: