Adobe Experience Platform Write
In this article
Overview
Use this Snap to restructure and write input JSON data as JSON or Parquet files into Adobe Enterprise Platform (AEP).
Prerequisites
The dataset into which you want to write the output of the Adobe Experience Platform Write Snap. If you do not have the dataset ready, you must create it first using the Adobe Experience Platform UI or the Adobe Experience Platform S3 Connector Snap.
Snap Input and Output
| Input/Output | Type of View | Number of Views | Compatible Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
| Input | Document |
|
| Each input document contains data that you want to write to AEP. |
| Output | Document |
|
| Each output document lists out the status and other details associated with the write process. |
Snap Settings
| Parameter Name | Data Type | Description | Default Value | Example |
|---|---|---|---|---|
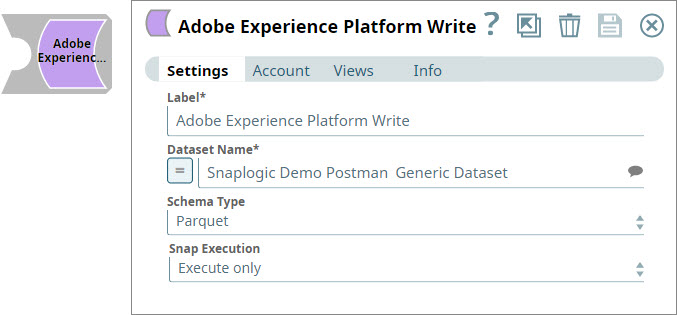
| Label | String | Required. The name for the Snap. Modify this to be more specific, especially if there is more than one of the same Snap in the Pipeline. | Adobe Experience Platform Write | Write Documents into AEP |
Dataset Name | String | Required. The name of the dataset into which you want to write the input data. This is a suggestible field. Click This property is expression-enabled. For more information on the expression language, see Understanding Expressions in SnapLogic and Using Expressions. For information on Pipeline Parameters, see Pipeline Properties. This Snap reads Pipeline parameters, but not values from upstream Snaps. You can, however, add this Snap in Pipelines with other Snaps to execute them in a sequence. | N/A | Adobe Generic Dataset |
| Schema Type | String | Required. The schema type that you want to use to create the file that must be written. Click to select from the following options:
| Parquet | Parquet |
| Snap execution | String | Select one of the three modes in which the Snap executes. Available options are:
| Execute only | Validate and Execute |
Limitations
While the Dataset Name field is expression enabled, its purpose is to read Pipeline parameter values. This Snap does not read values from upstream Snaps. You can, however, add this Snap in Pipelines with other Snaps to execute them in a sequence.
Troubleshooting
| Error | Reason | Resolution |
|---|---|---|
| Missing property value | The snap settings are not correct. You may see this error because you did not provide a mandatory value. | Check to ensure that all mandatory values are provided and valid. |
| Invalid Snap configuration | Target Dataset Name is null or missing. This typically means that you did not specify the dataset into which the parquet file must be written or that the dataset name specified doesn't exist in AEP. | Ensure that the property Dataset Name has a valid dataset name. Use the drop-down button adjacent to the Dataset Name field to select a valid dataset. |
| Unable to load the private key for the given alias | File not found on <your SnapLogic instance> at <account location> | This error appears when the account doesn't have valid values. Ensure that the keystore path, keystore passphrase, private key alias, and private key passphrase are correct. Also, you must upload the keystore in the Keystore Path that you specify. |
| Unable to obtain access token | This message appears when the endpoint account details are incorrect. | Check your Organization ID, Technical Account ID, Client ID, Client Secret Key details and try again. |
Examples
Writing JSON Documents from S3 as Parquet Files in AEP
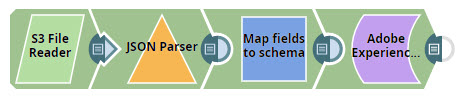
In this example, you retrieve a JSON document from your AWS S3 account and write it as a parquet file in a target AEP dataset. To do so, you decide to perform the following tasks:
- Read the source file from AWS S3
- Map fields in your source document to elements in your target AEP schema
- Write the restructured data into the target dataset in AEP as parquet files
You design the Pipeline as shown below:
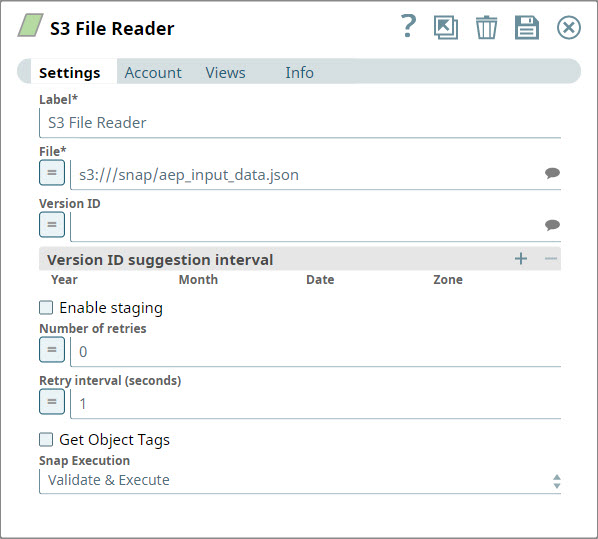
Read source data from AWS S3
You open the S3 File Reader Snap and configure it to retrieve the file that you want to write into AEP.
You attach a JSON Parser Snap to the S3 File Reader Snap to parse and view the incoming JSON data.
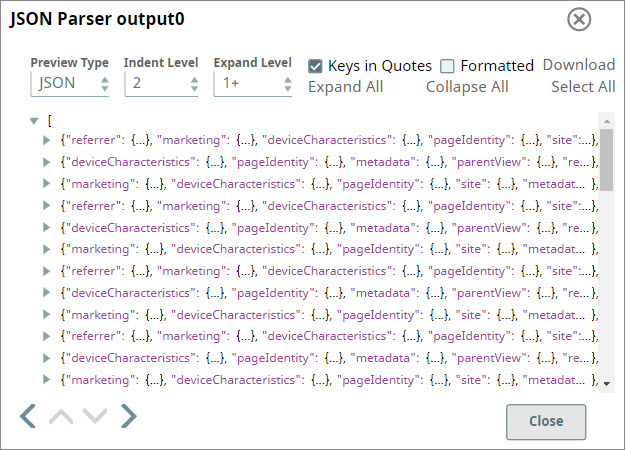
Map fields in your source document to elements in your target AEP schema
You now must prepare the JSON document for inclusion into AEP as a parquet file. To do so, you use the Mapper Snap.
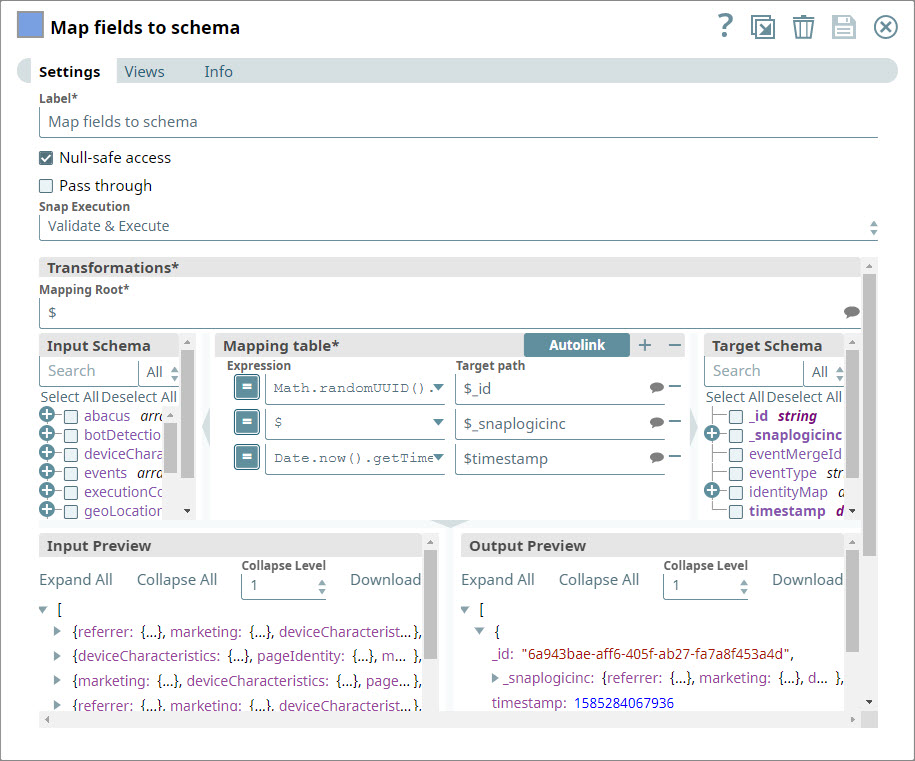
You configure the Mapper Snap to take all the data coming in from the upstream Snaps as one entity and attach a randomly generated ID and a timestamp as two additional entities. The Mapper output is now ready to be ingested into AEP.
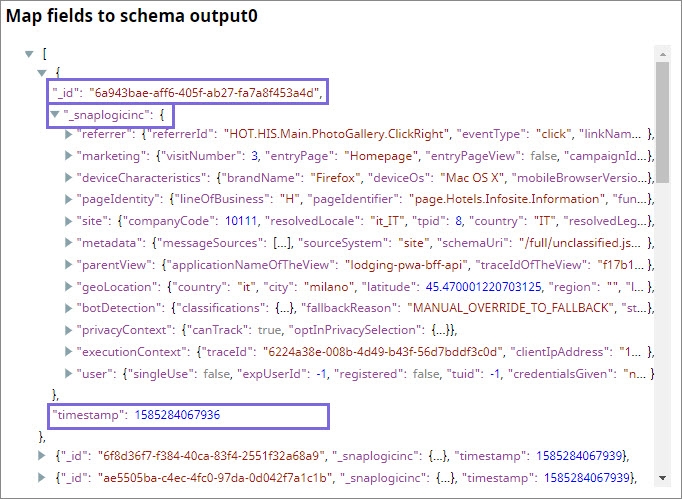
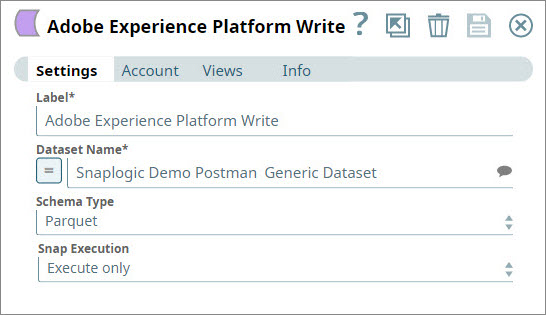
Write the restructured data into the target dataset in AEP as parquet files
You use the AEP Writer Snap to write the restructured document coming from the upstream Mapper Snap into AEP. You choose the dataset into which the document must be written and you execute the Pipeline.
If your account settings are correct, the Snap logs into AEP on your behalf and writes the Parquet file into the target dataset.

Downloads
Snap Pack History
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2024 SnapLogic, Inc.