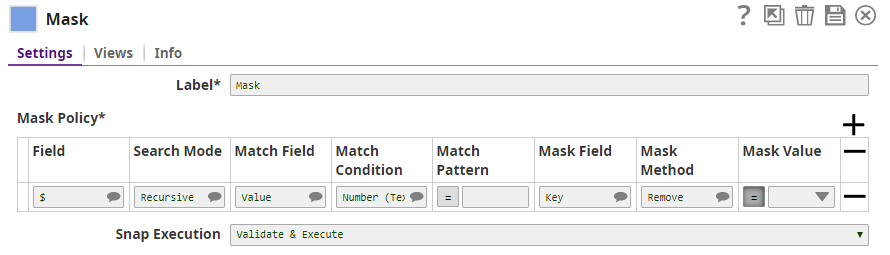
Mask
On this page
Overview
Use the Mask Snap to hide sensitive information in your dataset before you export the dataset for analytics. You can protect sensitive data by using masking algorithms that the Snap provides out of the box.
Snap Input and Output
| Input/Output | Type of View | Number of Views | Compatible Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
| Input | Document |
|
| A dataset where some of the data must be masked. |
| Output | Document |
|
| A dataset where the specified data is masked. |
Support for Ultra Pipelines
Works in Ultra Pipelines.
Snap Settings
| Parameter Name | Data Type | Description | Default Value | Example |
|---|---|---|---|---|
| Label | String | Required. The name for the Snap. Modify this to be more specific, especially if there is more than one of the same Snap in the Pipeline. | N/A | Mask |
| Mask Policy | N/A | Required. Enables you to specify the policies that you want to use to mask data in the input dataset. | N/A | N/A |
Field | String | The field/parent field in the input dataset that contains the data to be masked. | N/A | name |
| Search Mode | N/A | The mode the Snap must use to search sensitive data. Select from the following options:
For example, if you want to mask | N/A | Exact Path |
| Match Field | String | The type of field in the input data to be matched. Select from the following options:
The Snap fails to validate if the Match Field is Key and the Mask Field is also Key. In such a case, select Value as the Mask Field. | N/A | Value |
| Match Condition | N/A | The match condition that determines whether the Match Field should be matched. For example, if your input dataset contains $credit_card Field and you enter the Match Field as Value and Match Condition as Number, then the Snap masks all $credit_card fields that contain a number as the value. If the field contains text as the value, then the Snap skips masking that value. Select from the following options:
| N/A | Date |
| Match Pattern | String | The expression of the information pattern to be matched in the input dataset. This is applicable only when the Match Condition is Regex Match or Date (Text). | N/A | Hello |
| Mask Field | N/A | The field that contains sensitive data and will be masked if the matching conditions are met. Select from the following options:
The Snap fails to validate if the Match Field is Key and the Mask Field is also Key. In such a case, select Value as the Mask Field. | N/A | Value |
| Mask Method | N/A | The method to use to mask sensitive information. Select from the following options:
| N/A | Remove |
| Mask Value |
| The value that must replace the sensitive information in the input dataset. You can enter either a fixed value or an expression. This is applicable only when the Mask Method is Replace. | N/A | 0 |
| Execute during preview | N/A | Specify the execution type from the following options:
| Validate & Execute | Validate & Execute |
Example
This Pipeline demonstrates how the Mask Snap helps you hide sensitive information in a dataset. In this example, the input dataset is a demographic of the Oscar award winners. We want to pass on the dataset to a third party to derive the analytics. However, before we pass on the data, we want to hide sensitive information from the dataset. We use the Mask Snap to identify and replace/remove all sensitive information from the Oscar award winners list. While the dataset here is public data, you can apply the masking policies that the Mask Snap provides to hide confidential or sensitive data from your organization.

Download the Pipeline.
The dataset is derived from Kaggle and is a demographic of Oscar award winners in the Best Director category from 1927 through 1976. The input document is picked up using the File Reader Snap and is passed through the CSV Parser Snap. A preview of the dataset in CSV format is per the following:
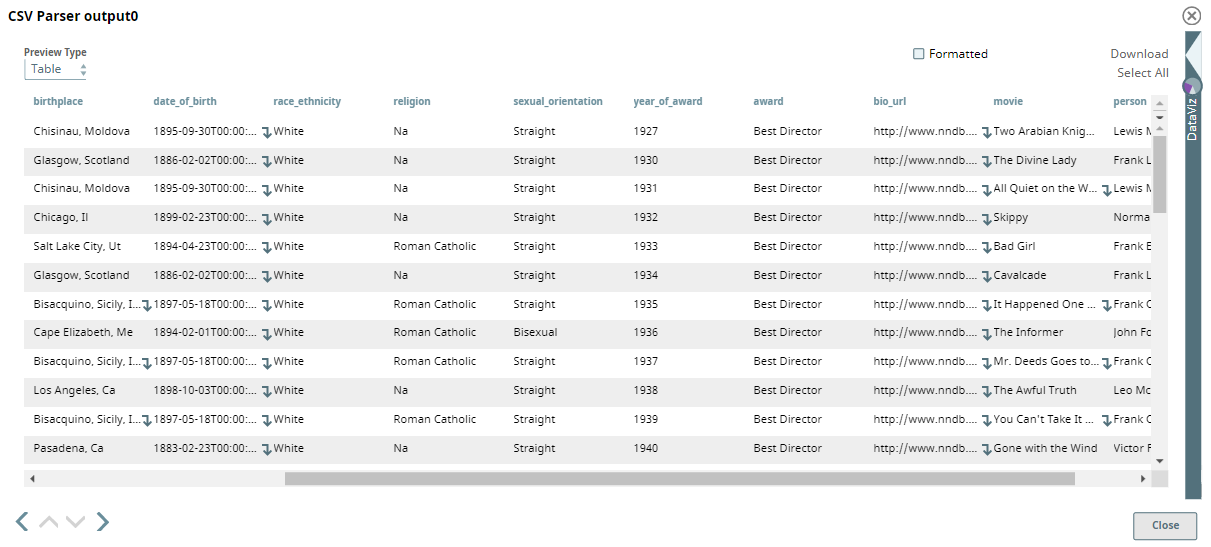
The dataset is passed to the Mask Snap to hide sensitive data. In this example, we want to mask the following fields:
- date_of_birth: Replace all dates of birth with the first day of the respective year of birth
- bio_url: Delete all HTTP/HTTPS URLs from the dataset
- person: Replace the name of the winner with the text "Winner name is masked"
For this purpose, we have configured the Mask Snap per the following:
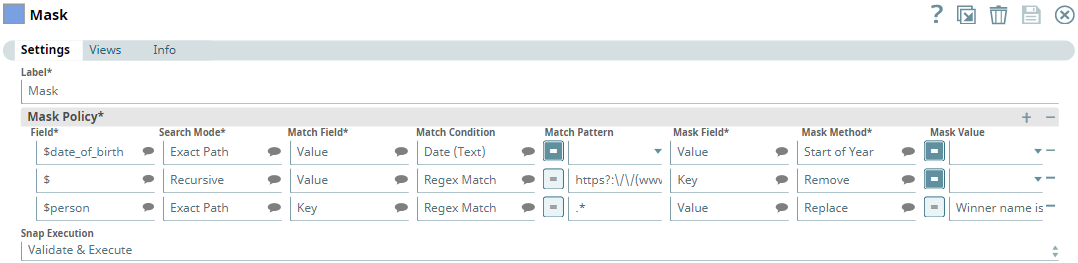
We have added three rows under Mask Policy, and each row enables us to mask one of the fields discussed above.
The first row under Mask Policy enables us to mask the date_of_birth field. We specify the Field as $date_of_birth and select the Search Mode as Exact Path. You can use Exact Path when you are sure that the field does not contain any data which is nested or in an array. The Match Field is Value and the Match Condition is Date (Text). The Mask Method is set to Start of Year. With this configuration, the Snap replaces all $date_of_birth values that are in standard date format with the first day of the year of birth. For example, in the first row of the dataset, the date of birth is 1895-09-30. The Snap replaces this value with 1895-01-01.
The second row under Mask Policy enables us to mask the bio_url field. We specify the Field as $ and select the Search Mode as Recursive. Recursive mode will search for all possible fields that could contain a URL that matches the regular expression, https?:\/\/(www\.)?[-a-zA-Z0-9@:%._\+~#=]{1,256}\.[a-zA-Z0-9()]{1,6}\b([-a-zA-Z0-9()@:%_\+.~#?&\/\/=]*), in the Match Pattern. This regular expression matches all HTTP and HTTPS URLs in the dataset. In this case, the Match Field is Value, the Mask Field is Key, the Match Condition is Regex Match, and the Mask Method is Remove. The Snap completely deletes all keys that contain an HTTP/HTTPS value. Hence, we do not see the bio_url field in the output.
In Recursive mode, you can mask multiple fields at a time depending on the condition specified. For example, if you think your data is nested, or in an array, and that you cannot specify the exact path, you can use Recursive mode. In this example, we are not sure how many fields contain URLs. Hence, we use recursive mode to mask all field values that contain a URL.
The third row under Mask Policy enables us to mask the name of the winner. We specify the Field as $person and select the Search Mode as Exact Path. The Match Field is Key and the Match Condition is Regex Match, and the Match Pattern is .* which matches any value that is entered in the $person field. The Mask Method is Replace and the Mask Field is Value. The Mask Value is Winner name is masked. The Snap replaces all $person value with Winner name is masked. For example, in the first row of the dataset, the value Lewis Milestone is replaced with Winner name is masked. You can use this feature when you do not want to remove a value but replace it with static text to let the consumer of the dataset know that the original value is masked.
After the dataset is passed through the Mask Snap and the different mask conditions are applied to it, the output dataset is per the following screenshot:
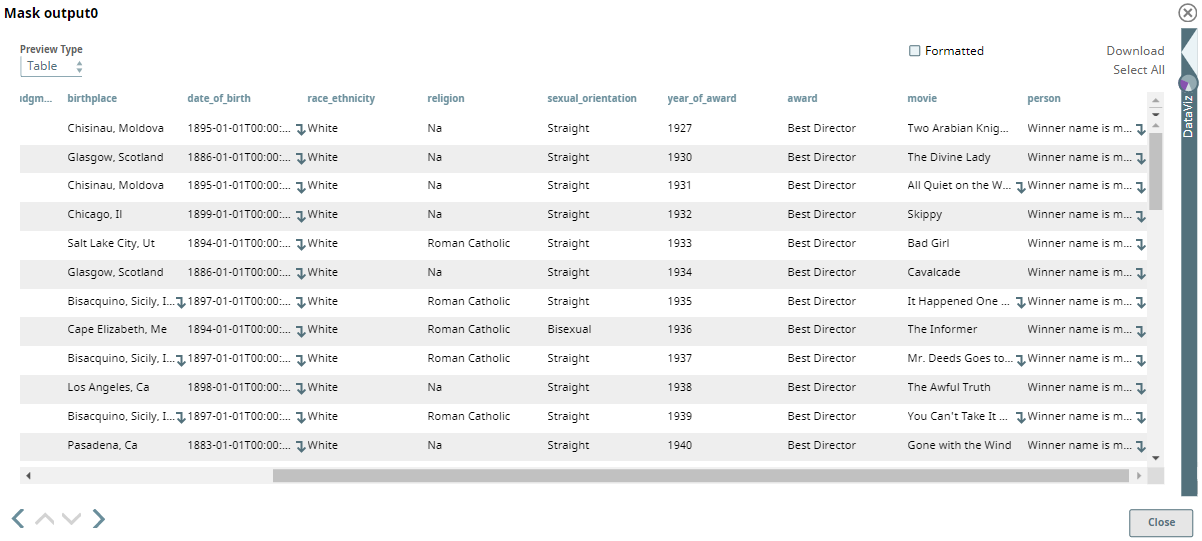
In the output dataset preview, we can see that the date_of_birth field shows the first date of a year instead of the exact birth date, the bio_url field is removed, and the person field shows Winner name is masked instead of the real name.
The masked dataset output of the Mask Snap is then converted to CSV format using the CSV Formatter Snap and then passed to a File Writer Snap.
See Also
Snap Pack History
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2024 SnapLogic, Inc.