In this articleTable of Contents
| Table of Contents | ||||
|---|---|---|---|---|
|
Overview
...
| Panel | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||
|


| Parameter | Field Dependency | Description | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Label* | None. | Required. Unique user-provided label for the account. Default Value: N/A Example: ELT DLP Azure Account AD ON | ||||||||||||
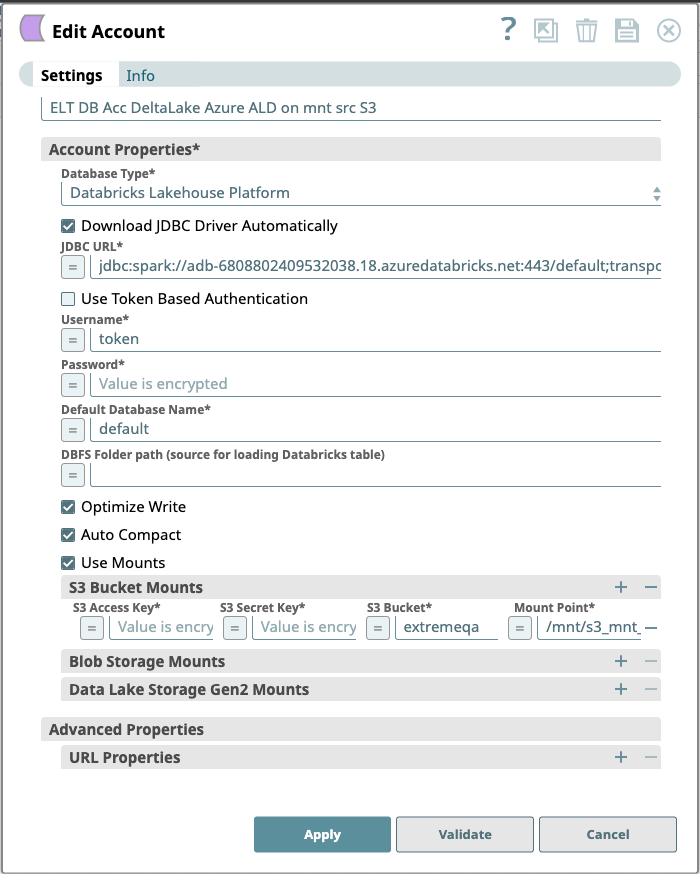
| Account Properties* | Use this field set to configure the information required to establish a JDBC connection with the account. This field set consists of the following fields:
| |||||||||||||
| Database Type* | None. | Select the target data warehouse into which the queries must be loaded, that is Databricks Lakehouse Platform. This activates the following fields:
Default Value: N/A Example: Databricks Lakehouse Platform | ||||||||||||
| Download JDBC Driver Automatically | None. | Select this checkbox to allow the Snap account to download the certified JDBC Driver for DLP. The following fields are disabled when this checkbox is selected.
To use a JDBC Driver of your choice, clear this checkbox, upload (to SLDB), and choose the required JAR files in the JDBC JAR(s) and/or ZIP(s): JDBC Driver field.
Default Value: Not Selected Example: Selected | ||||||||||||
| JDBC JAR(s) and/or ZIP(s): JDBC Driver | Required when the Download JDBC Driver Automatically checkbox is not selected. | Upload the JDBC driver and other JAR files that you want to use into SLDB. Click Default Value: N/A Example: SimbaSparkJDBC42-2.6.21.1021.jar | ||||||||||||
| JDBC driver class* | Required when the Download JDBC Driver Automatically checkbox is not selected. | Specify the driver class to use for your application. We recommend that you use com.simba.spark.jdbc.Driver for DLP, as other classes and methods may change due to future enhancements. Default Value: N/A Example: com.simba.spark.jdbc.Driver | ||||||||||||
| JDBC URL* | None. | Enter the JDBC driver connection string that you want to use in the syntax provided below, for connecting to your DLP instance. See Microsoft's JDBC and ODBC drivers and configuration parameters for more information.
Alternatively, you can make use of the Username, Password, and Database Name fields, along with the Advanced Properties > URL Properties field set to provide the parameters required for building your JDBC URL. See Passing your JDBC URL for more information.
Default Value: N/A Example: jdbc:spark://adb-2409532680880038.18.azuredatabricks.net:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/2409532680880038/0326-212833-drier754;AuthMech=3; | ||||||||||||
Use Token Based Authentication | Database Type is Databricks Lakehouse Platform | Select this checkbox to use token-based authentication for connecting to the target database (DLP) instance. Activates the Token field. Default value: Selected Example: Not selected | ||||||||||||
| Token* | When Use Token Based Authentication checkbox is selected. | Enter the token value for accessing the target database/folder path. Default value: N/A Example: <Encrypted> | ||||||||||||
| Default Database Name* | None. | Enter the name of the database to use by default. This database is used if you do not specify one in the ELT Select, ELT Insert-Select, or ELT Merge Into Snaps. Default value: N/A Example: EMPLOYEEDB | ||||||||||||
| DBFS Folder path (source for loading Databricks table) | Database Type is Databricks Lakehouse Platform | Required for ELT Load Snap. Specify the fully qualified path to a target folder in your DBFS instance. It should begin with / which denotes the DBFS Root folder.
Default value: N/A Example: /my_DBFS/mounted0408_folder | ||||||||||||
| Optimize Write | Database Type is Databricks Lakehouse Platform. | Select this checkbox to dynamically optimize the Apache Spark partition sizes based on the actual data. If selected, DLP attempts to write 128 MB files (this is an approximate size and can vary depending on dataset characteristics) for each table partition. Default Value: Not Selected Example: Selected | ||||||||||||
| Auto Compact | Database Type is Databricks Lakehouse Platform. | Select this checkbox to allow DLP to compact small files being written into a Delta table. Default Value: Not Selected Example: Selected | ||||||||||||
| Use Mounts | Checkbox | If this checkbox is selected, it provides three different sources to mount DBFS. | ||||||||||||
| S3 Bucket Mounts | Use this field set to provide the information required to configure the S3 Database account. It consists of the following fields:
| |||||||||||||
S3 Access Key | String | Specify the S3 access key ID that you want to use for AWS authentication. Default Value: N/A | ||||||||||||
| S3 Secret Key | String | Specify the S3 secret key associated with the S3 Access-ID key listed in the S3 Access-key ID field. Default Value: N/A | ||||||||||||
| S3 Bucket | String | Specify the name of the S3 bucket that you want to use for staging data to Snowflake. Default Value: N/AExample: sl-bucket-ca Default Value: N/A | ||||||||||||
Mount Point | String | The directory within DBFS to mount the source. Data written to mount point paths ( In the case of ELT Load Snap (DataBricks only) the priority of the loading from paths is as follows:
Learn more at Defining mount points. | ||||||||||||
| Blob Storage Mounts | Use this field set to provide the information required to configure the blob storage mounts. It consists of the following fields:
| |||||||||||||
Azure Blob Account Name | Database Type is Databricks Lake Platform. External Location is Blob Storage or Azure Data Lake Gen2. | Enter your Account name to access the selected Azure external storage location. You must configure this field if you want to use the ELT Load Snap. Default value: N/A Example: adlsgen2v02 | ||||||||||||
Azure Blob Storage Key | Database Type is Databricks Lake Platform. External Location is Blob Storage or Azure Data Lake Gen2. Azure Auth Type is Shared Access Signature, Managed Identity, or Service Principals. | Enter the storage access key value corresponding to the Azure account mentioned in Storage Account field. See COPY INTO (Transact-SQL) in Microsoft Docs for more information on the expected values for this field. This field is needed only when you want to define the File Name Pattern in the ELT Load Snap to locate and read the file/s from the Azure Folder path. Else, leave it blank. Default value: N/A Example: ufv!befDIuf#fnb$KH&_hweuf | ||||||||||||
Container Name | Database Type is Databricks Lake Platform. External Location is Blob Storage or Azure Data Lake Gen2. | Enter the name of the container in the Azure storage account. Azure Container is not applicable to does not apply to the Redshift database. Default value: N/A Example: hrdepartment | ||||||||||||
Mount Point | String | The directory within DBFS to mount the source. Data written to mount point paths ( In the case of ELT Load Snap (DataBricks Databricks only) the priority of the loading from paths is followingas follows:
Learn more at Defining mount points. | ||||||||||||
Data Lake Storage Gen2 Mounts | Use this field set to provide the information required to configure the Data Lake Storage Gen2 Mounts. It consists of the following fields:
| |||||||||||||
Application Id | Database Type is Databricks Lake Platform. External Location is Blob Storage or Azure Data Lake Gen2. | Enter the name of theapplication (client) ID for the Azure Active Directory application that you want to configure. Default value: N/A Example: 635f1f0e-2378bd-412683734777efa9ef | ||||||||||||
ADLS Gen2 Oauth2 Secret Key | Database Type is Databricks Lake Platform. External Location is Blob Storage or Azure Data Lake Gen2. | Enter the Oauth2 secret key which is part of ADLS Gen2 account authentication in the Azure portal. Default value: N/A Example: 7ed4587-a77f-43bf-94c5dfg | ||||||||||||
ADLS Gen2 Tenant Id | Database Type is Databricks Lake Platform. External Location is Blob Storage or Azure Data Lake Gen2. | Enter the Tenant ID obtained after creating the application in the Azure portal. Default value: N/A Example: 2060aaafe-89d9-9514-eac46338ec05 | ||||||||||||
ADLS Gen2 Account Name | Database Type is Databricks Lake Platform. External Location is Blob Storage or Azure Data Lake Gen2. | Enter the name of the account. Default value: N/A Example: Gen2 account name | ||||||||||||
ADLS Gen2 Container Name | Database Type is Databricks Lake Platform. External Location is Blob Storage or Azure Data Lake Gen2. | Enter the name of the container in the Azure storage account. Azure Container is not applicable to does not apply to the Redshift database. Default value: N/A Example: hrdepartment | ||||||||||||
| Mount Point | String | The directory within DBFS to mount the source. Data written to mount point paths ( In the case of ELT Load Snap (DataBricks only) the priority of the loading from paths is as follows: Account.
Learn more at Defining mount points. | ||||||||||||
| Advanced Properties | Other parameters that you want to specify as URL properties. This field set consists of the following fields:
| |||||||||||||
| URL Properties | None. | The account parameter's name and its corresponding value. Click + to add more rows. Add each URL property-value pair in a separate row. Specify the name of the parameter in the URL Property Name field and its value in the URL Property Value field. Default value: N/A Example: MAX_CONCURRENCY_LEVEL: 3 | ||||||||||||
Click Validate after entering the required details to ensure that all fields have been filled accurately. Click Apply to save the settings.
| Note | ||
|---|---|---|
| ||
If you have used Pipeline parameters or expressions to define values for the account fields above, the account validation (done by clicking the Validate button) is not supported. However, the Snaps that use this account may connect to the endpoint successfully depending on the accuracy and validity of the expressions and parameters used. |
...
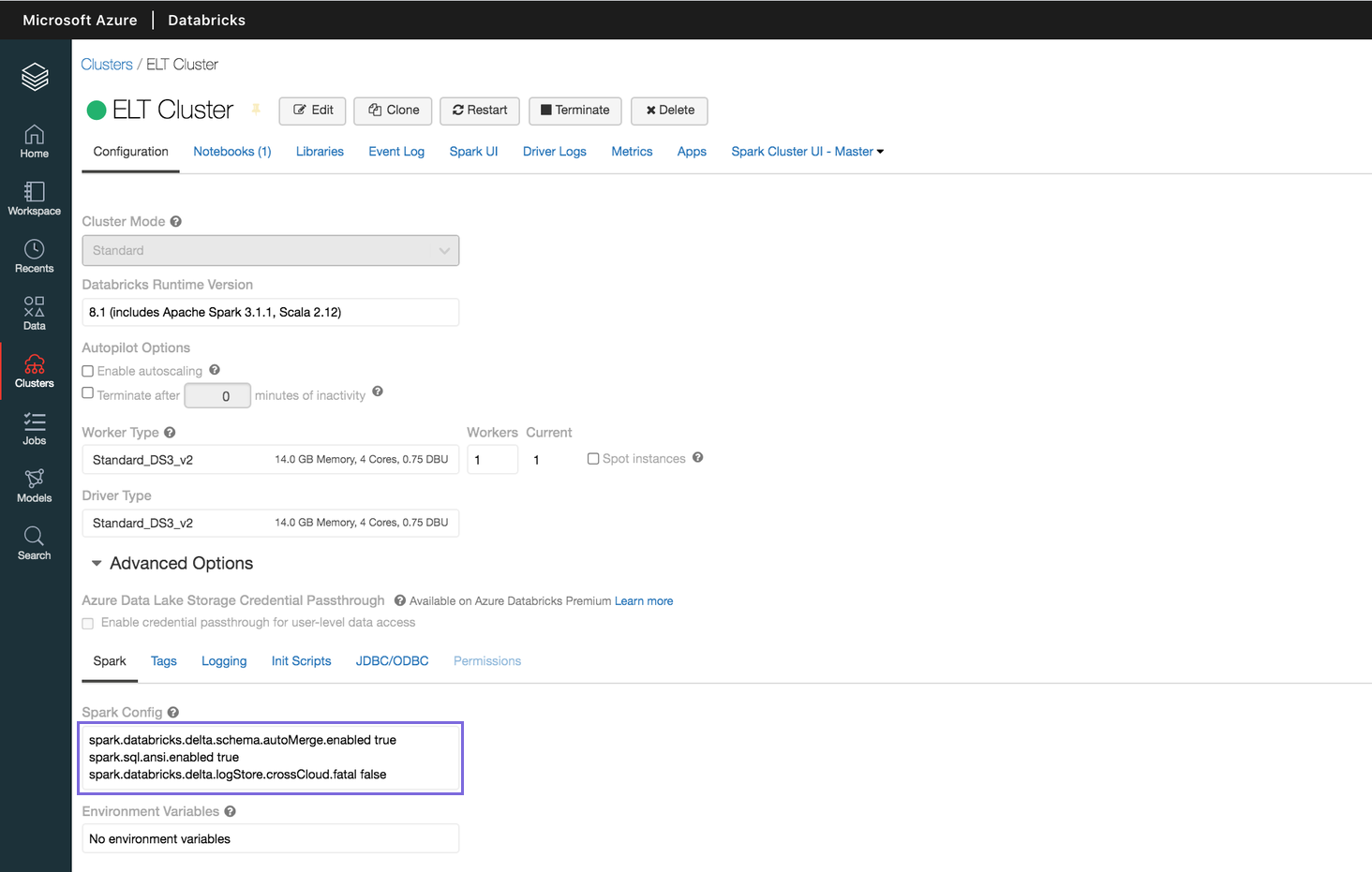
The following image depicts the Spark configuration properties defined for a sample DLP instance.
Defining mount points
You can use the following external (cloud storage) buckets/containers and their folder paths for reading, writing, and loading Databricks delta tables.
AWS S3 (accessed using S3A protocol)
Azure Blob Storage (accessed using WASBS protocol)
ADLS Gen 2 (accessed using ABFSS protocol)
To enable Databricks runtime to access externally located data files from the Databricks cluster, you need to mount your bucket/container on to DBFS path. Once the ‘mount point’ is created through a cluster, the corresponding DBFS path allows accessing the external data location (cloud storage).
Security considerations
The mount point is only a pointer to your cloud storage location, so the data is never synced locally (i.e data is never moved into DBFS)
Once a mount point is created through a Python Notebook attached to a cluster, users of that cluster can immediately access the mount point.
To use the mount point in another running cluster, you must run
dbutils.fs.refreshMounts()on that running cluster to make the newly created mount point available.All users have read and write access to all the objects in the buckets/containers mounted to DBFS.
Azure Blob storage supports three blob types: block, append, and page. You can only mount block blobs to DBFS.
Mount an S3 Bucket on DBFS Path
Use Databricks Python Notebook to run the
fsutils.mount()command with your access credentials, as follows:Paste code macro language sql title Mounting an S3 bucket on DBFS access_key = 'XXXX...' secret_key = 'abcd...' mount_name = 'my_s3_mnt_point' s3_bucket_name = 'my-s3-bucket' encoded_secret_key = secret_key.replace('/', '%2F') dbutils.fs.mount('s3a://%s:%s@%s' % (access_key, encoded_secret_key, s3_bucket_name), '/mnt/%s' % mount_name)- Verify that the mount point is created by running the
display(dbutils.fs.mounts())command.
Mount an Azure Blob Storage’s Container on DBFS Path
Use Databricks Python Notebook to run the
fsutils.mount()command with your access credentials, as follows:Paste code macro language sql title Mounting an Azure Blob Storage’s Container on DBFS storage_account_name = '<SA_name>' storage_account_access_key = '<XXX...>' container_name = '<container_name>' mount_name = '<my_wasb_mnt_point>' dbutils.fs.mount( source = 'wasbs://%s@%s.blob.core.windows.net/' % (container_name, storage_account_name) mount_point = '/mnt/%s' % mount_name, extra_configs = {'fs.azure.account.key.%s.blob.core.windows.net' % storage_account_name : '%s' % storage_account_access_key} )- Verify that the mount point is created by running the
display(dbutils.fs.mounts())command.
Mount an ADLS Gen2 Container on DBFS Path
The steps below assume you have created the OAuth2 application to access your containers.
...