On this Page
| Info | ||
|---|---|---|
| ||
After upgrading to 425patches10152, the snap might fail when you select Map input to first repeating element in XSD checkbox with an error Could not convert the document to an XML. In such cases, ensure that you provide a complete path from the root element for an object and map the input properly to the root element. |
| Table of Contents | ||||
|---|---|---|---|---|
|
Snap type: | Format | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Description: | This Snap formats the incoming SnapLogic document objects into XML data format. The conversion from the internal JSON structure to XML follows the StAXON mapping convention. This mapping uses naming conventions to turn JSON object fields into XML nodes and attributes. For example, using the default Snap settings, the following two documents will be collected and written out as a single chunk of XML:
The output of the formatter for these two documents will look something like the following. Note that the "msg" fields are turned into nodes in the XML structure, fields that start with "@" are turned into attributes on those nodes and "$" fields are turned into text nodes. The "DocumentRoot", "Document", and related fields are part of the wrappers added by the formatter when it collects multiple documents into a single file.
If you would like generate a file without the wrapper elements, you can clear the "Root Element" property and the Snap will produce a single binary document for every input document, like so: The Snap can also validate documents against a provided schema to ensure that the output is well-formed. Any invalid documents will be written to the error output view. The Snap by default produces XML that is not canonical. You can transform the XML output to canonical XML by selecting the Format as Canonical XML checkbox. The canonical form of an XML output from XML Formatter Snap is an XML representation that excludes the XML prolog and includes the start and end tag for all the XML elements. For more information about Canonical XML Version 1.0 specifications, see https://www.w3.org/TR/xml-c14n. | |||||||||||||
| Prerequisites: | [None] | |||||||||||||
| Support and limitations: | Works in Ultra Task Pipelines if Root Element is not selected. | |||||||||||||
| Account: | Accounts are not used with this Snap. | |||||||||||||
| Views: |
| |||||||||||||
Settings | ||||||||||||||
Label | Required. The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | |||||||||||||
Outbound schema | XSD schema definition file URL for the outgoing data. The currently supported url protocols are SLDB, HDFS, S3. Example: sldb:///foo/bar/customer.xsd Default value: [None] | |||||||||||||
| Validate output | Required. Specifies the incoming data to be validated against the provided XSD schema definition in Inbound Schema property.
Example: False Default value: False | |||||||||||||
| Root element | The name of the XML element under which all the incoming documents will be added. If empty, no wrapping will be done and each document will be written out as a separate binary. Example: DocumentRoot Default value: DocumentRoot | |||||||||||||
| Ignore empty stream | If selected, the Snap will do nothing when no document has been received in the input view. If not selected, the Snap will write an empty XML data with a header at the output view when no document has been received in the input view. Default value: Not selected | |||||||||||||
Map input to first repeating element in XSD |
| |||||||||||||
| Format as Canonical XML | If selected, the Snap produces a canonical XML output. The canonical form of an XML output (from XML Formatter Snap) is an XML representation that excludes the XML prolog and includes the start and end tag for all the XML elements. For more information about Canonical XML Version 1.0 specifications, see https://www.w3.org/TR/xml-c14n. | |||||||||||||
| Max schema levels | This configuration limits the number of schema levels provided by the outbound schema on the SnapLogic input view to a maximum of 10 levels. This configuration does not effect the validation capability. It serves to prevent outbound schemas from consuming too much memory and processing time. Default value: 10 | |||||||||||||
|
| |||||||||||||
Schema language supported : W3C XML Schema 1.0
Troubleshooting
XML Formatter and XML Generator Output Differs for the Same XSD File Input
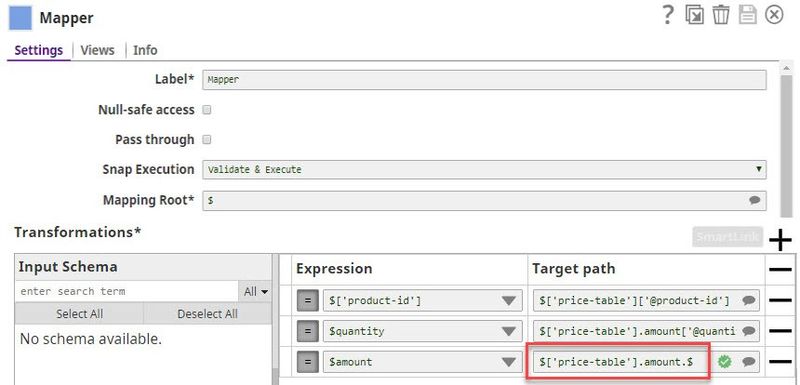
The XML Formatter and XML Generator Snaps work differently for an XSD file as the input document. To generate the same output from both the Snaps, append the following to the required schema in the Target path property of the preceding Mapper Snap:
- XML Formatter:
.$ - XML Generator:
.value
Examples
In the following example, the Map input to first repeating element in XSD field is set to True.
Assume the given XSD file is:
| Code Block |
|---|
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema" targetNamespace="urn:books" xmlns:bks="urn:books">
<xsd:element name="books" type="bks:BooksForm"/>
<xsd:complexType name="BooksForm">
<xsd:sequence>
<xsd:element name="book" type="bks:BookForm" minOccurs="0" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="BookForm">
<xsd:sequence>
<xsd:element name="author" type="xsd:string" maxOccurs="unbounded"/>
<xsd:element name="title" type="xsd:string"/>
<xsd:element name="genre" type="xsd:string"/>
<xsd:element name="price" type="xsd:float" />
<xsd:element name="pub_date" type="xsd:date" />
<xsd:element name="review" type="xsd:string"/>
</xsd:sequence>
<xsd:attribute name="id" type="xsd:string"/>
</xsd:complexType>
</xsd:schema>
|
Assume two input documents are:
| Code Block |
|---|
[
{
"@id": "bk001",
"title": "The First Book",
"author": "John Smith",
"genre": "Fiction",
"price": "44.95",
"pub_date": "2000-10-01",
"review": "An amazing story of nothing." },
{
"@id": "bk002",
"title": "The Poet's First Poem",
"author": "Mary Parker",
"genre": "Poem",
"price": "24.95",
"pub_date": "2000-10-01",
"review": "Least poetic poems." }
] |
The Snap extracts "books" as the root element name and "book" as the wrapper name from the XSD file.
The default XML output will be:
| Code Block |
|---|
<?xml version='1.0' encoding='UTF-8'?>
<books>
<book id="bk001">
<title>The First Book</title>
<author>John Smith</author>
<genre>Fiction</genre>
<price>44.95</price>
<pub_date>2000-10-01</pub_date>
<review>An amazing story of nothing.</review>
</book>
<book id="bk002">
<title>The Poet's First Poem</title>
<author>Mary Parker</author>
<genre>Poem</genre>
<price>24.95</price>
<pub_date>2000-10-01</pub_date>
<review>Least poetic poems.</review>
</book>
</books> |
The canonical XML output will be:
| Code Block |
|---|
<books>
<book id="bk001">
<title>The First Book</title>
<author>John Smith</author>
<genre>Fiction</genre>
<price>44.95</price>
<pub_date>2000-10-01</pub_date>
<review>An amazing story of nothing.</review>
</book>
<book id="bk002">
<title>The Poet's First Poem</title>
<author>Mary Parker</author>
<genre>Poem</genre>
<price>24.95</price>
<pub_date>2000-10-01</pub_date>
<review>Least poetic poems.</review>
</book>
</books> |
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|