In this article
...
Field Name | Field Type | Description | |||
|---|---|---|---|---|---|
Label* Default Value: Mapper | String | The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your Pipeline. | |||
Null-safe access Default Value: Deselected | Checkbox | Select this checkbox to set the target value to null in case the source path does not exist. For example, | |||
Pass through Default Value:Deselected | Checkbox | This setting determines if data should be passed through or not. If you select this checkbox, then all the original input data is passed into the output document together with the data transformation results. If you deselect this checkbox, then only the data transformation results that are defined in the mapping section appear in the output document and the input data is discarded.
When to always select Pass through Always select Pass through if you plan to leave the Target path field blank; else, the Snap displays an error that the field that you want to delete does not exist. This is the expected behavior. For example, you have an input file that contains a number of attributes; but you need only two of these downstream. So, you connect a Mapper to the downstream Snap supplying the input file, select the two attributes you need by listing them in the Expression fields, leave the Target path field blank, and select Pass through. When you execute the Pipeline, this Snap evaluates the input documents/binary data and picks up the two attributes that you want, and passes the entire document/binary data through to the Target schema. From the list of available attributes in the Target Schema, the Mapper Snap picks up the two attributes you listed in the Expression fields, and passes them as output. However, if you had not selected the Pass through checkbox, the Target Schema would be empty, and the Mapper would display a | |||
Transformations* | Use this fieldset to configure the settings for data transformations. | ||||
Mapping Root Default Value: $ | String/Suggestion | Specify the sub-section of the input data to be mapped. Learn More: Understanding the Mapping Root. Default: | |||
Input Schema | Dropdown list | Select the input data (that comes from the upstream Snap) that you want to transform. | |||
Mapping table | Use this field set to specify the source path, expression, and target path columns used to map schema structure. This field set contains the following fields:
| ||||
Expression Default Value: N/A | String/Expression | Specify the expression to write to the target path. Expressions that are evaluated will remove the source targets at the end of the run.
Lear More: Understanding Expressions in SnapLogic and Using Expressions for usage guidelines. Managing Numeric Inputs in Mapper Expressions While working with upstream numeric data, you may see some unexpected behavior. For example, consider a mapping that reads as follows: Expression: Target path: For example, the value being passed from upstream for $num is 20.05. You would expect the value of $numnew to now be 120.05. But, when you execute the Snap, the value of $numnew is shown as 20.05100. This happens because, as of now, the Mapper Snap reads all incoming data as strings, unless they are expressly listed as integers (INT) or decimals (FLOAT). So, to ensure that the upstream numeric data is appropriately interpreted, parse the data as a float. This will convert the numeric data into a decimal; and all calculations performed on the upstream data in the Mapper Snap will work as expected: Expression: Target path: The value of $numnew is now shown as 120.05. | |||
Target path Default Value: N/A | String/Suggestion | Specify the target path at which the expression should be written. Target Path Recommendation
For example, you have the Expression $Emp.Emp_Personal.FirstName in one of your Pipelines. And you have set the Target path for this expression as $FirstName. Now, if you use the expression $Emp.Emp_Personal.FirstName in a new Pipeline, then Iris suggests $FirstName as one of the recommended Target paths. This helps you standardize the naming standards within your org. The following video illustrates how Iris recommends Target path in a Mapper Snap: 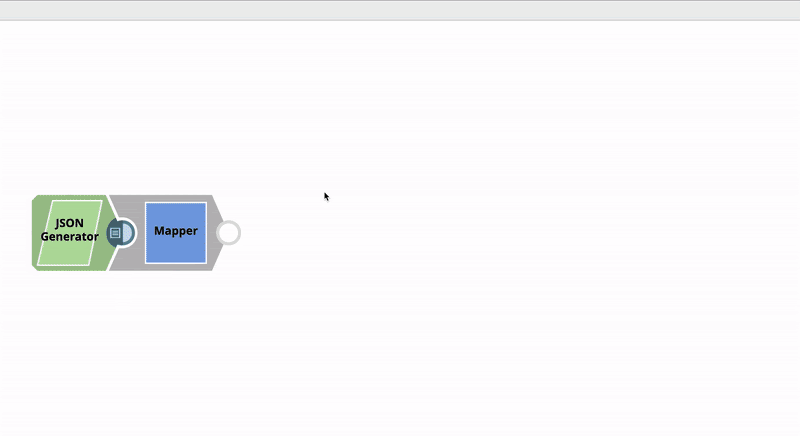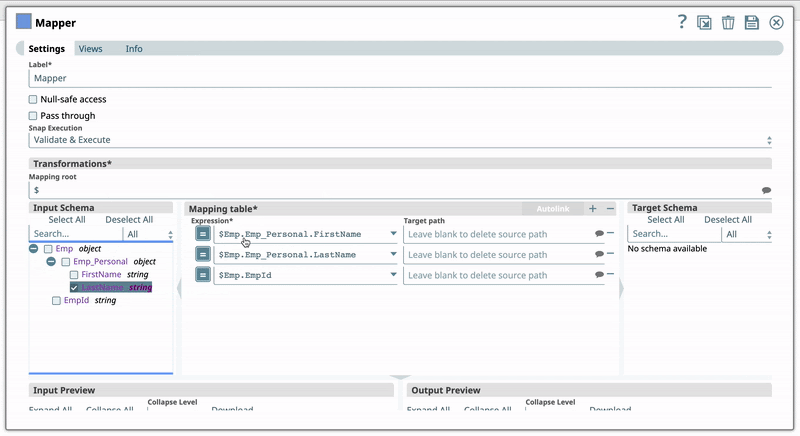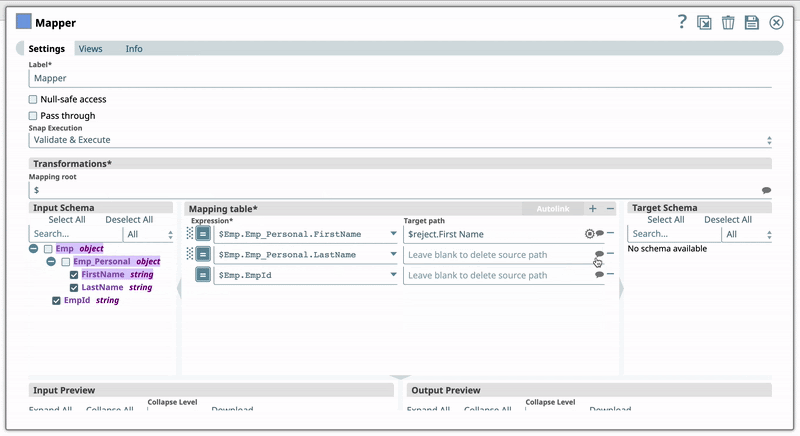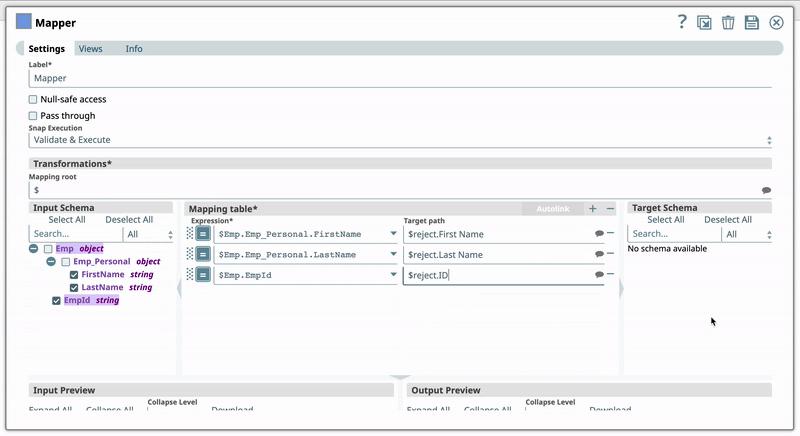 | |||
Snap Execution | Dropdown list | Select one of the three modes in which the Snap executes. Available options are:
| |||
...
If the Escape Character is | Use Expression | Sample Output | ||
|---|---|---|---|---|
Single quote (') | JSON: $original.mapValues((value,key)=> value.toString().replaceAll("'","''")) OR $original.mapValues((value,key)=> value.toString().replaceAll("'","\''")) CSV: $[' Business-Name'].replace ("'","''") |   | ||
Ampersand (&) | JSON: $original.mapValues((value,key)=> value.toString().replaceAll("'","\&'")) OR $original.mapValues((value,key)=> value.toString().replaceAll("'","&'")) CSV: $[' Business-Name'].replace ("'","&'") |   | ||
Backslash (\) | JSON: $original.mapValues((value,key)=> value.toString().replaceAll("'","\\'"))
CSV: $[' Business-Name'].replace ("'","\\'") |   |
In this way, you can customize the data to be passed on to downstream Snaps using the Expression field in the Mapper Snap.
...
Community Links:
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|