In this article
| Table of Contents | ||||
|---|---|---|---|---|
|
Overview
You can use this Snap to apply aggregate functions on input data using the Group By support. You can perform a calculation on a set of values to return a single scalar value.
...
The following are the commonly used SQL Aggregate functions:
...
Field Name | Type | Description | |
|---|---|---|---|
Label* Default Value: Aggregate | String | Specify the name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your Pipeline. | |
Aggregate fields* | Use this field set to define the type of Aggregate function to perform on the field and the key name to be used in the output. This field set contains the following fields:
| ||
Function* Default Value: SUM | String | Select the functions that applies to the aggregate field value in the input data. The available functions and the supported datatypes are:
When you select the AVG function, the Snap rounds up all numeric values that have more than 16 digits. The AVG function handles the numeric values as below:
| |
Field* Default value: [None] | String/Expression | Specify a JSON path to the field on which the Aggregate function should be applied such as | |
Result field* Default value: [None] | String | Specify the field name to be used for mapped data in the output. This value is the aggregate computed result corresponding to the GROUP-BY field values. | |
GROUP-BY fields* | Use this field set to define field paths and names. If you leave this field blank, the Snap produces only one output document. This field set contains the following fields:
| ||
Field Default value: [None] | String/Expression | Specify a JSON path for the GROUP-BY field. | |
Output field Default value: [None] | String | Specify the GROUP-BY field name to be used in the output map data. If left blank, the Field path is used instead. | |
Integer mode Default value: Deselected | Checkbox | Select this checkbox if you want the Snap to produce integer results rounded half up. The input data can be mixed in integers and floating-point numbers, and the Snap maintains intermediate results in floating-point numbers. The value of this field is ignored in the COUNT Aggregate function. | |
Sorted streams* Default value: Unsorted | Dropdown list | Select an option to specify if the input documents are sorted or not. This option enables the Snap to verify if the input is sorted as it processes each document and performs the aggregation efficiently and displays an error if the records are not sorted. The available options are:
If the input data stream contains several documents, then presort the input using the Sort Snap—this uses less memory and results in an effective performance. If the data is not presorted, the Snap consumes memory equal to the input data stream. | |
Snap Execution Default value: Validate & Execute | Dropdown list | Select one of the three modes in which the Snap executes. Available options are:
| |
...
The following example Pipeline shows how to use the Aggregate Snap to count the occurrences of a given product name.
Snap Configuration | Output |
|---|---|
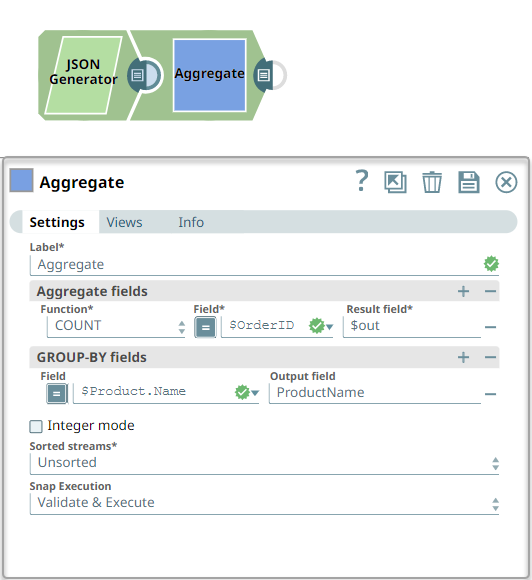 | 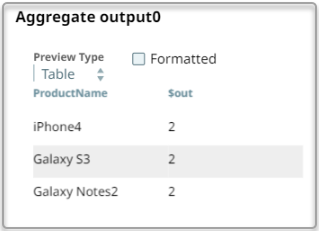 |
Downloads
| Info |
|---|
|
...