In this article
| Table of Contents | ||||||
|---|---|---|---|---|---|---|
|
In this section
| Child pages (Children Display) |
|---|
Overview
You must create Hive accounts to connect to data sources that you want to use in your Pipelines. You can configure your Teams accounts in SnapLogic using either the Designer or or Manager.
For more information on SnapLogic Accounts, refer to Accounts.
Configuring Hive Accounts Using SnapLogic Designer
Drag a Hive Snap to the Canvas and click the Snap to open its settings. Click the Account tab. You can now either use an existing account or create a new one.
Selecting an existing account
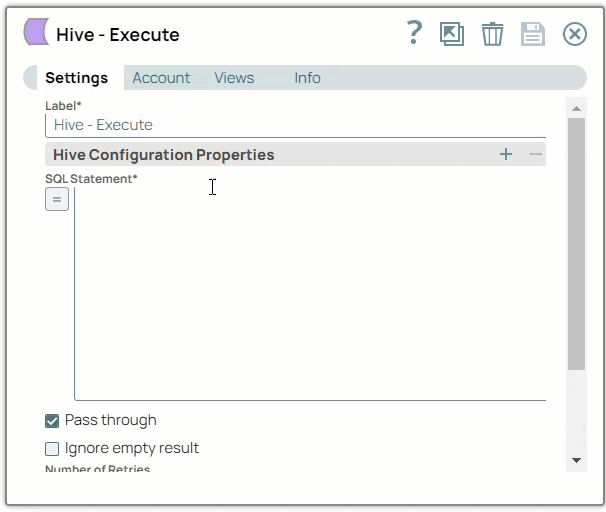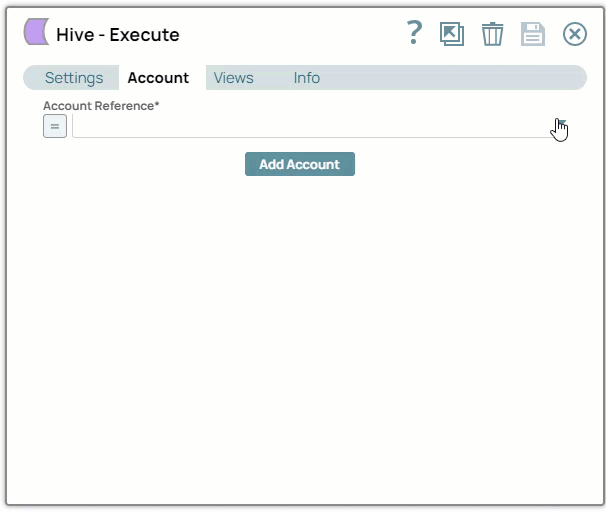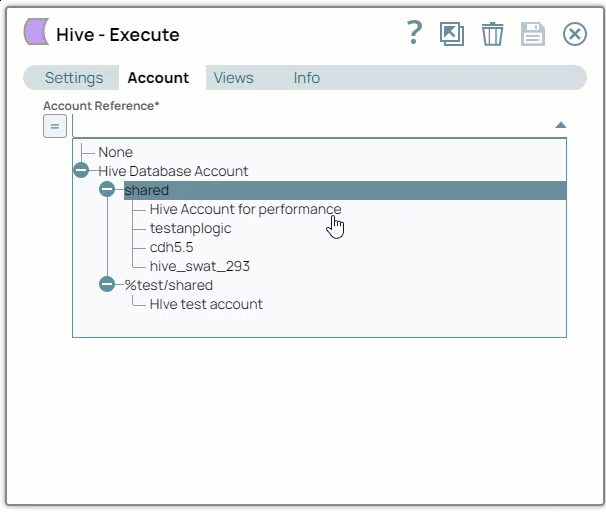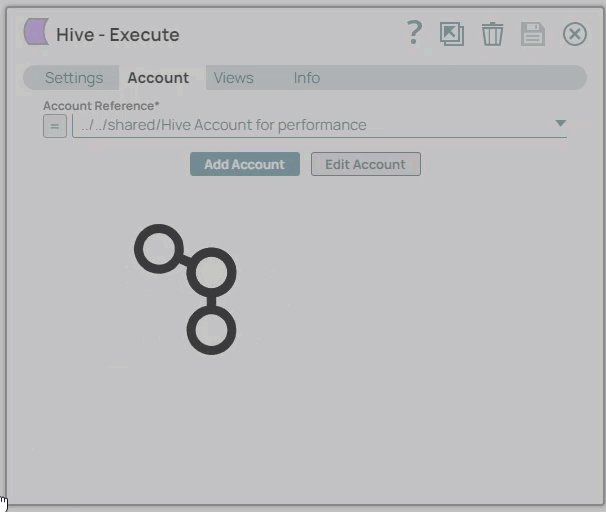
SnapLogic organizes and displays all accounts to which you have access, sorting them by account type and location. To select an existing account:
In the Account tab, click the dropdown
 icon to view the accounts to which you have access, and select the account that you want to use.
icon to view the accounts to which you have access, and select the account that you want to use.Click the Save
icon.
Creating an account
In the Account tab, click Add Account below the Account Reference field.
Select the Location in which you want to create the account, select the Account Type, and click Continue. The Add Account dialog window associated with the account type is displayed.
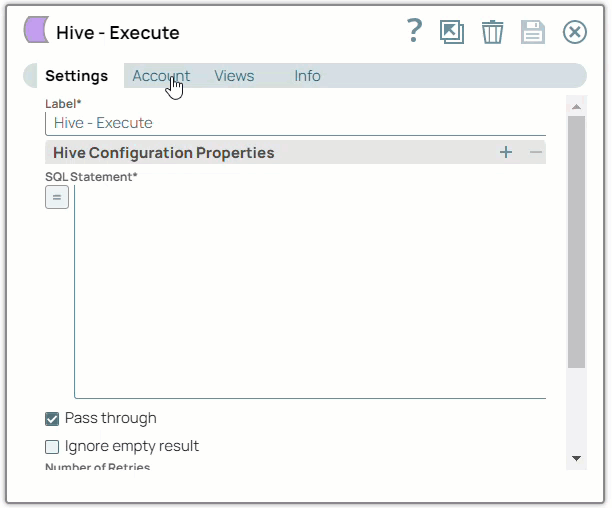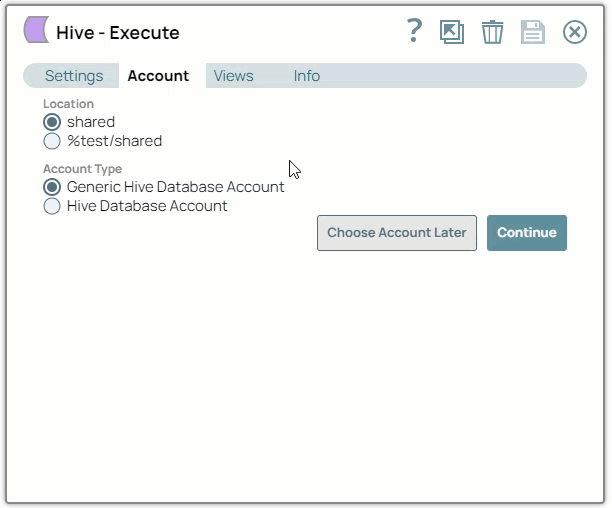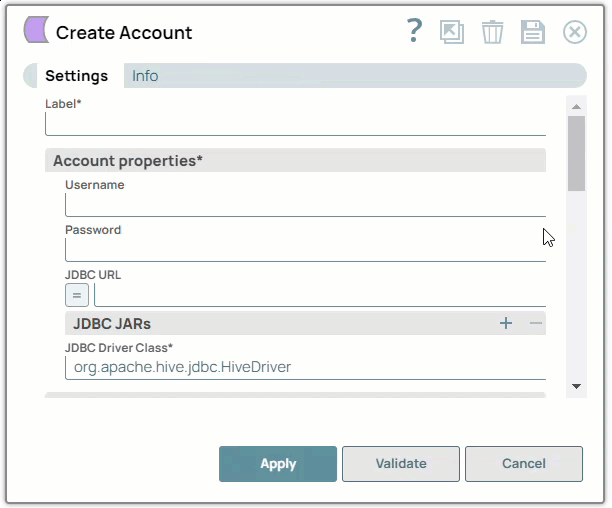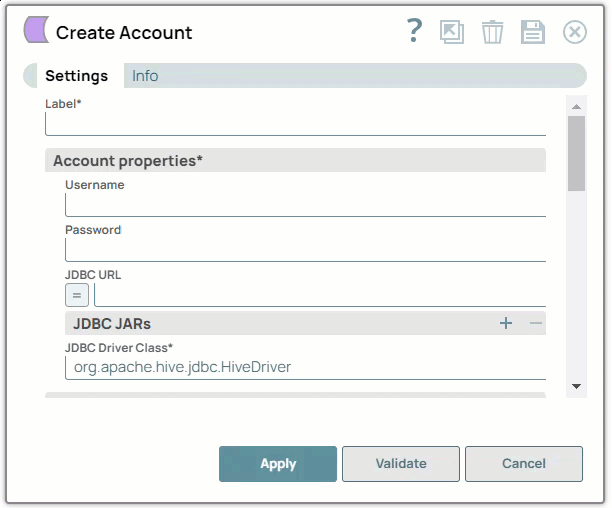
Enter the required account details. For detailed guidance on how to provide the information required for each account type, refer to Generic Hive Database Account and Hive Database Account.
Click Validate to verify the account, if the account type supports validation.
Click Apply to complete configuring the Hive account.
| Info |
|---|
Enter additional information on this account in the Notes field of the Info tab. This will help you–and other users–understand the purpose of the account, especially if there are multiple accounts of the same type. |
Configuring Hive Accounts Using SnapLogic Manager
You can use Manager to create accounts without associating them immediately with Pipelines.
Accounts in SnapLogic are associated with projects. You can use accounts created in other projects only if you have at least Read access to them.
In the left pane, browse to the project in which you want to create the account and click
> Account > Hive, followed by the appropriate account type. The Create Account dialog associated with the selected account type is displayed.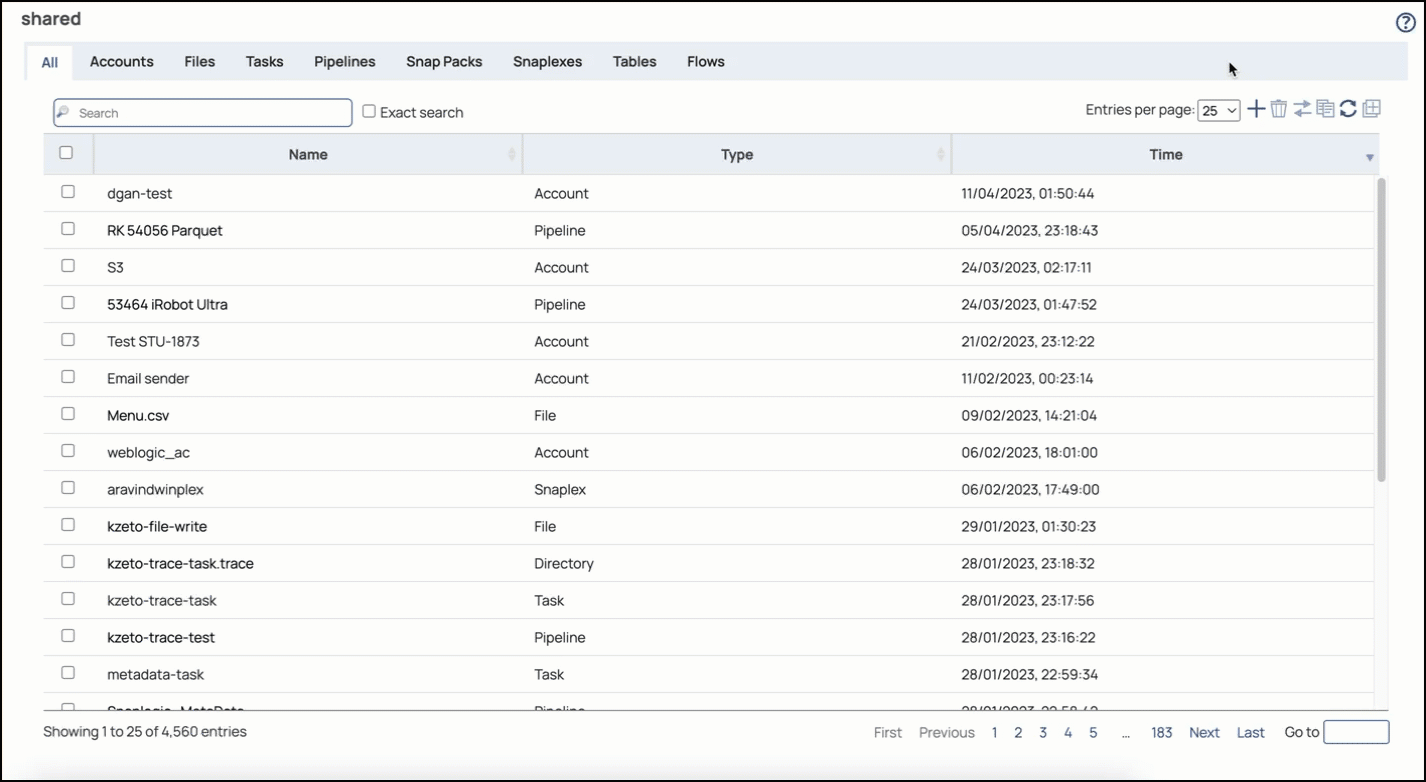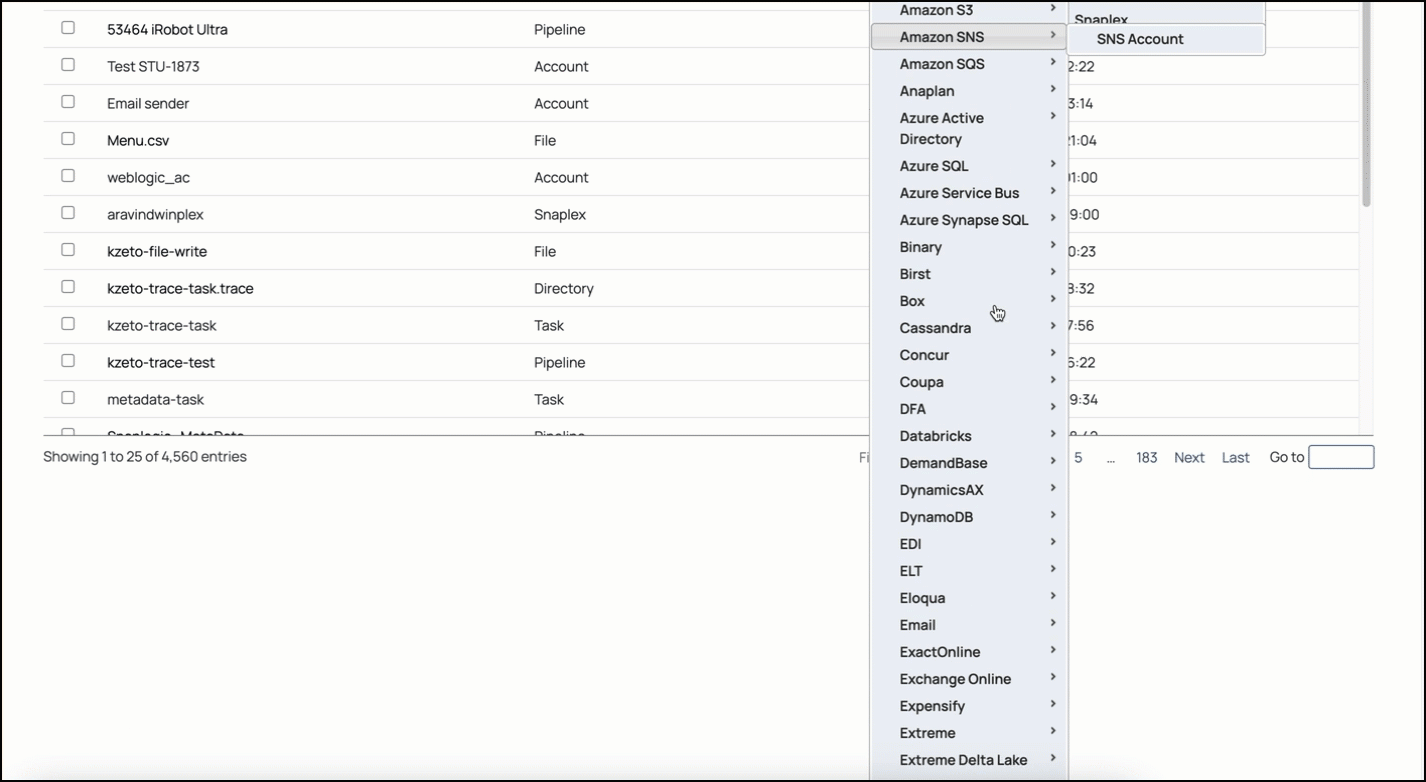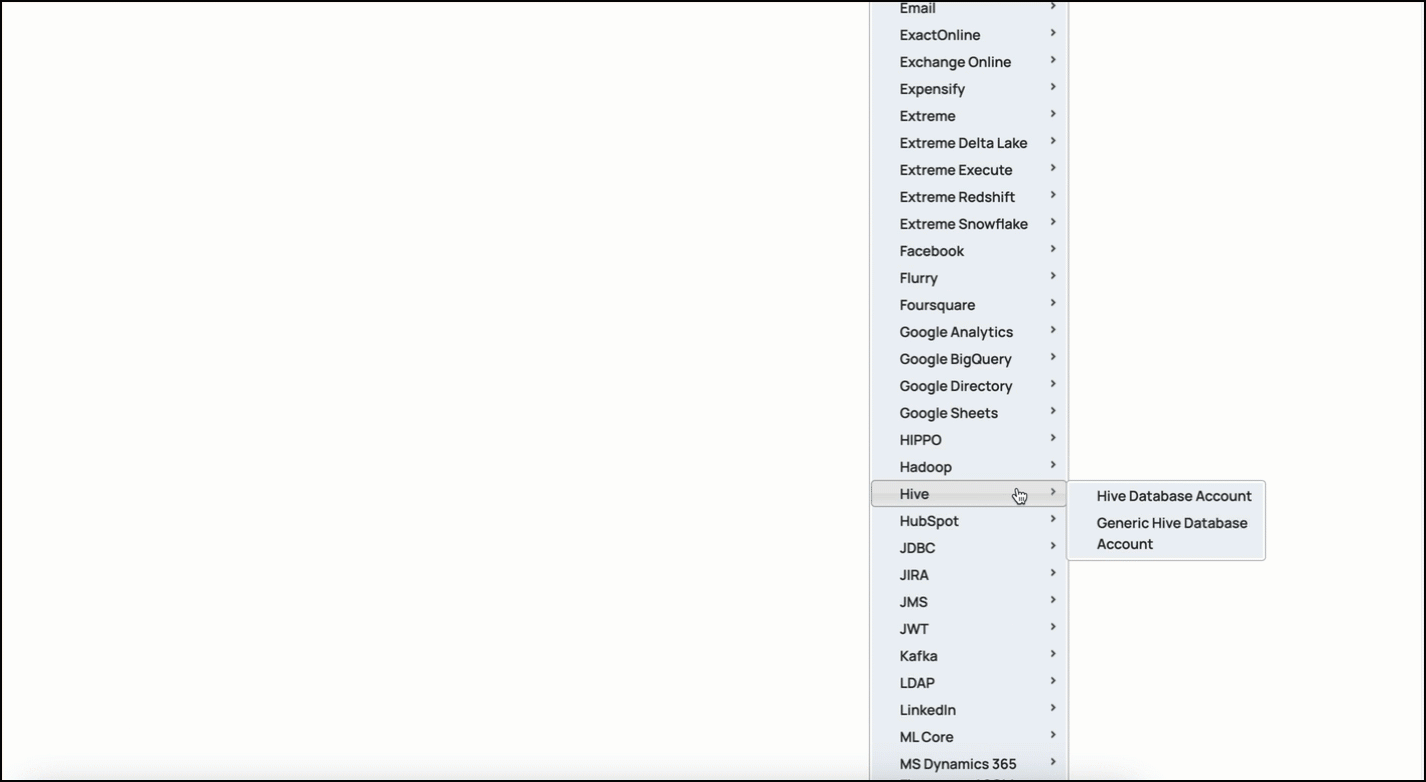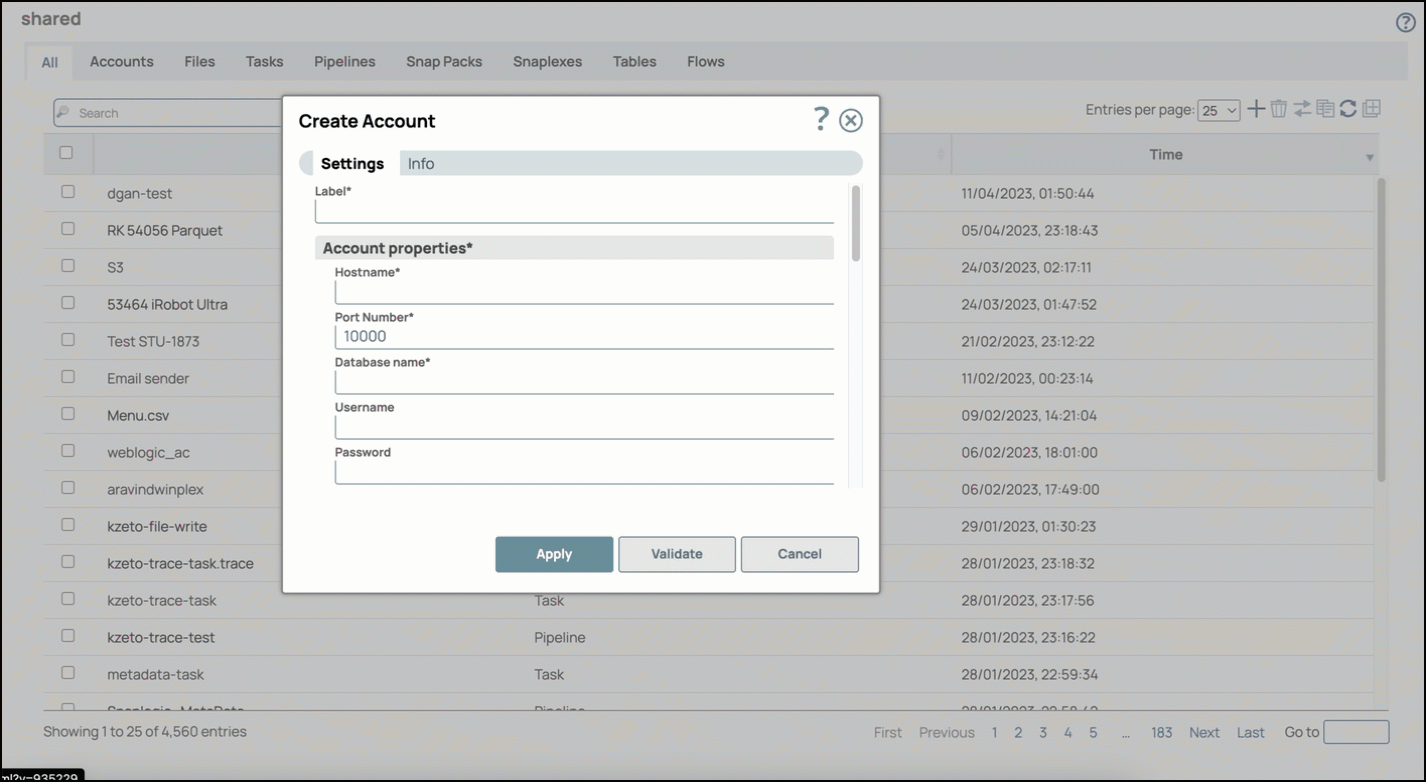
Repeat the steps numbered 3 through 5 in the Creating the Creating an account sectionaccount section.
Avoid updating account credentials while Pipelines using that account are executing. Doing so may lead to unexpected results, including your account getting locked.
Account Types
Hive Database Account
| Expand | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Generic Hive Database Account
| Expand | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Additional Configurations
Configuring Hive with SSL
Add the following properties to the Url properties table to configure Hive with SSL. These configurations work only with Groundplexes and not Cloudplexes.
URL Property Name | URL Property Value |
|---|---|
ssl | Required. Binary value to denote that SSL is enabled. This value must always be 1. |
sslTrustStore | Required. The path of SSL Trust store key file pointing to a JKS, PEM or CER file. The file can be referenced from the Groundplex's file system. |
sslTrustStorePassword | Required. Password configured for the SSL Trust store. |
AllowSelfSignedCerts | Binary value to denote whether the driver allows the server to use self-signed SSL certificates. Pass the value 1 to allow the use. |
CAIssuedCertNamesMismatch | Binary value to denote that the driver requires the CA issued SSL certificate's name to match the host name of the Hive server. Pass the value 1 to indicate the names must match. |
| Note |
|---|
The above list is specific to Hive with or without Kerberos enabled. With Kerberos enabled, the properties such as Client Principal, Key tab file and Service principal have to be additionally provided. |
Limitations or known issues
"Method not supported" error while validating Apache Hive JDBC v1.2.1 or earlier
The Hive Snap Pack does not validate with Apache Hive JDBC v1.2.1 jars or earlier because of a defect in Hive. HDP 2.6.3 and HDP 2.6.1 run on Apache Hive JDBC v1.2.1 jars.
To validate Snaps that must work with HDP 2.6.3 and HDP 2.6.1, use JDBC v2.0.0 jars.
Testing Environment
Hive Version: Hive 1.1.0, Hive 1.2.0
Hive with Kerberos works only on Hive JDBC4 driver 2.5.12 and above
Hive with SSL works only on Hive JDBC4 driver 2.5.12 and above.
Cluster Versions: CDH 5.16.1, CDH 5.10, HDP 2.6.1, HDP 2.6.3
Snap Pack History
| Expand | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|