In this Article
| Table of Contents | ||||
|---|---|---|---|---|
|
Snap type: | Flow | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Description: | This Snap is for executing Pipelines and passing documents into and out of these executions. The following execution modes are supported by this Snap:
You can execute Pipelines on the same Snaplex node that the parent Pipeline is running without contacting the SnapLogic cloud. In this mode, the Snap does not need to connect with the SnapLogic cloud servers, allowing you to use this Snap in an Ultra Pipeline. For example, you can use Snaps that do not support Ultra mode with this design.
This Snap will eventually replace the ForEach and Task Execute Snaps, as well as the Nested Pipeline mechanism.
| ||||||||||||||||||
| Prerequisites: | None | ||||||||||||||||||
| Support and limitations: |
| ||||||||||||||||||
| Account: | Accounts are not used with this Snap. | ||||||||||||||||||
| Views: | The Input/Output views on the Views tab are configurable.
| ||||||||||||||||||
Settings | |||||||||||||||||||
| Label | Required. The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your Pipeline. | ||||||||||||||||||
| Pipeline | Required. The absolute or relative path to the child Pipeline to run. If only the Pipeline name is given, then the Snap searches for the Pipeline in the following folders in this order:
You can also dynamically choose the Pipeline to execute by turning this property into an expression. For example, to execute all of the Pipelines in a project, you can connect the SnapLogic List Snap to this Snap to get the list of Pipelines in the project and execute each one. Note |
The child Pipeline must be designed to be compatible with this Snap. The current requirements are:
Default value: N/A | |||||||||||||||||
| Execute On | Select the Snaplex or node on which you want to execute the child Pipeline:
Default value: LOCAL_NODE | ||||||||||||||||||
| Snaplex Path | Required when the option selected in the Execute Execution On field is SNAPLEX_WITH_PATH. Enter Select the name of the Snaplex on which you want the child Pipeline to run. To select from the list of Snaplexes available in your Org, click the Default value: N/A | ||||||||||||||||||
| Execution label | The label to display in the Pipeline view of the Dashboard. By default, the child Pipeline's label is used. You can use this property to differentiate one execution from another. Default value: N/A | ||||||||||||||||||
| Pipeline parameters | You can configure Pipeline parameters used for executing the Pipeline in this property. Select the Pipeline parameters defined for the Pipeline selected in the Pipeline field. The Parameter value is the expression property that you can configure as an expression based on incoming documents, or this value can be a constant.
| ||||||||||||||||||
| Parameter name | The Parameter name is the name of the parameter used while executing the Pipeline. You can select the Pipeline parameters defined for the Pipeline selected in the Pipeline field. Default value: N/A | ||||||||||||||||||
| Parameter value | The Parameter value is the expression property that can be configured as an expression based on incoming documents or can be entered as a constant. If the value is configured as an expression based on the input, each incoming document or binary data is evaluated for the given expression and the value is set as the parameter value for the parameter name while invoking the Pipeline. The result of the expression evaluation is JSON-encoded if it is not a string. The child Pipeline then needs to use the Default value: N/A When reuse is enabled, the parameter values cannot change from one invocation to the next. | ||||||||||||||||||
| Reuse executions to process documents | This flag specifies the execution mode to use. When enabled, the Snap starts a child execution and passes multiple inputs to the Pipeline. Reusable executions continue to live until all of the input documents to this Snap have been fully processed. If this flag is not enabled, then a new Pipeline execution is created for each input document. Pipeline parameter values can only be changed if this flag is not enabled. In other words, reusable executions cannot have different Pipeline parameter values for different documents. Ultra Mode CompatibilityIf If reuse is enabled and this Snap is used in an Ultra Pipeline, then the Snaps in the child Pipeline must also be Ultra-compatible. If you need to use Snaps that are not Ultra-compatible in an Ultra Pipeline, you can create a child Pipeline with those Snaps and use a Pipeline Execute Snap with reuse disabled to invoke the Pipeline. Since the child Pipeline is executed for every input document, the Ultra Pipeline restrictions do not apply. For example, if you want to run an SQL Select operation on a table that would return more than one document, you can put a Select Snap followed by a Group By N Snap with the group size set to zero in a child Pipeline. In that configuration, the child Pipeline is executed, performs the select operation, and then the Group By Snap gathers all of the outputs into a single document or binary data. That single output document or binary data can then be used as the output of the Ultra Pipeline. Default value: Not selected | ||||||||||||||||||
| Number of Retries | The maximum number of retry attempts that the Snap must make in case of a network failure. If the child Pipeline does not execute successfully, an error document is written to the error view.
Example: 3 Default value: 0 | ||||||||||||||||||
| Retry Interval | The minimum number of seconds for which the Snap must wait between two successive retry requests. A retry happens only when the previous attempt resulted in an exception. Example: 10 Default value: 1 | ||||||||||||||||||
| Pool size | Multiple input documents or binary data can be processed concurrently by specifying an execution pool size. When the pool size is greater than one, the Snap starts executions as needed up to the given pool size. When Reuse is enabled, the Snap starts a new execution only if all executions are busy working on documents or binary data and the total number of executions is below the pool size. However, in Spark mode, if you execute multiple Pipelines simultaneously, the Hadoop cluster might face resource constraints, depending upon the complexity of the Pipelines and the size of the documents being processed. Default value: 1 | ||||||||||||||||||
| Timeout | The maximum number of seconds for which the Snap must wait for the child Pipeline to complete execution. If the child Pipeline does not complete executing before the timeout, the execution process stops and is marked as failed. Example: 10 Default value: 0 (No timeout is the default) | ||||||||||||||||||
|
| ||||||||||||||||||

Examples
Execute Child Pipeline Multiple Times
| Expand | ||
|---|---|---|
| ||
The project, PE_Multiple_Executions,demonstrates how the Pipeline Execute Snap can be configured to execute a child Pipeline multiple times. It contains the following Pipelines:
|
Converting Existing Pipelines
| Expand | ||
|---|---|---|
| ||
The Pipeline Execute Snap can replace some uses of the Nested Pipeline mechanism as well as the ForEach and Task Execute Snaps. For now, this Snap only supports child Pipelines with unlinked document views (binary views are not supported). If these limitations are not a problem for your use case, read on to find out how you can transition to this Snap and the advantages of doing so. Nested PipelineConverting a Nested Pipeline will require the child Pipeline to be adapted to have no more than a single unlinked document input view and no more than a single unlinked document output view. If the child Pipeline can be made compatible, then you can use this Snap by dropping it on the canvas and selecting the child Pipeline for the Pipeline property. You will also want to enable the Reuse property to preserve the existing execution semantics of Nested Pipelines. The advantages of using this Snap over Nested Pipelines are:
ForEachConverting a ForEach Snap to the Pipeline Execute Snap is pretty straightforward since they have a similar set of properties. You should be able to select the Pipeline you would like to run and populate the parameter listing. The advantages of using this Snap over the ForEach Snap are:
Task ExecuteConverting a Task Execute Snap to the Pipeline Execute Snap is also straightforward since the properties are similar. To start, you only need to select the Pipeline you would like to use, you no longer have to create a Triggered Task. If you set the Batch Size property in the Task Execute to one, then you will not want to enable the Reuse property. If the Batch Size was greater than one, then you should enable Reuse. The Pipeline parameters should be the same between the Snaps. The advantages of using this Snap over the Task Execute Snap are:
"Auto" RouterConverting a Pipeline that uses the Router Snap in "auto" mode can be done by moving the duplicated portions of the Pipeline into a new Pipeline and then calling that Pipeline using a Pipeline Execute. After refactoring the Pipeline, you can adjust the "Pool Size" of the Pipeline Execute Snap to control how many operations are done in parallel. The advantages of using this Snap over an "Auto" Router are:
|
Propagate Schema Backward – 1
| Expand | ||
|---|---|---|
| ||
The project, PE_Backward_Schema_Propagation_Contacts, demonstrates the schema suggest feature of the Pipeline Execute Snap. It contains the following files:
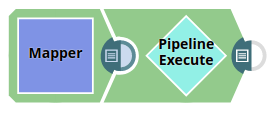
The parent Pipeline is shown below:
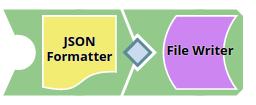
The child Pipeline is as shown below:
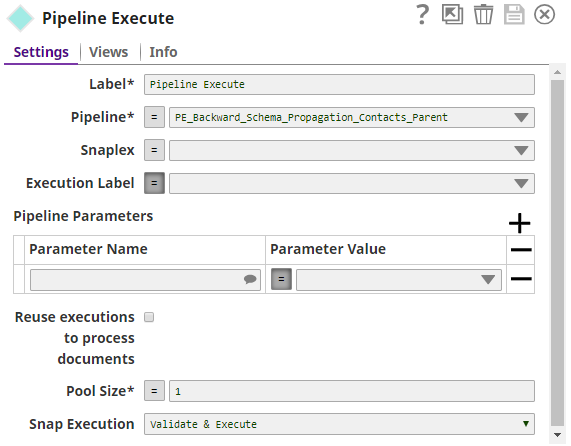
The Pipeline Execute Snap is configured as:
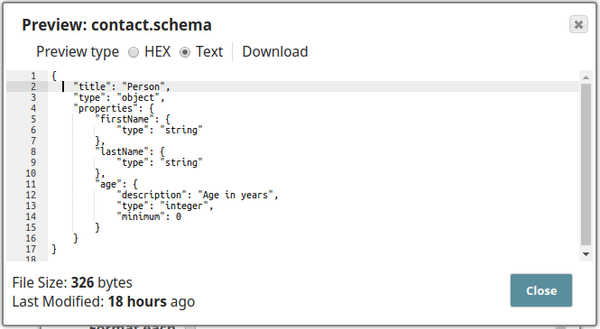
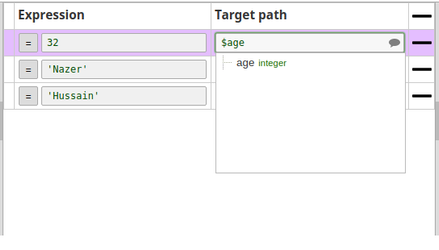
The following schema is provided in the JSON Formatter Snap. It has three properties - $firsName, $lastName, and $age. This schema is back propagated to the parent Pipeline.
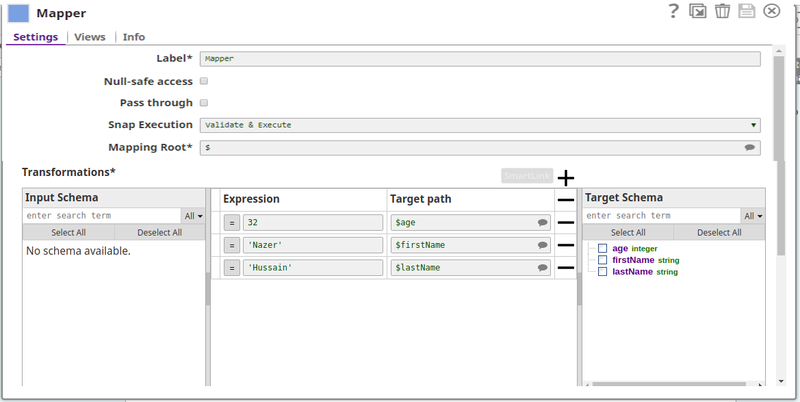
The parent Pipeline must be validated in order for the child Pipeline's schema to be back-propagated to the parent Pipeline. Below is the Mapper Snap in the parent Pipeline:
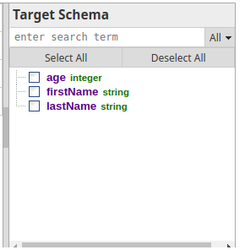
Notice that the Target Schema section shows the three properties of the schema in the child Pipeline:
Upon execution the data passed in the Mapper Snap will be written into the test.json file in the child Pipeline. The exported project is available in the Downloads section below. |
Schema Propagation in Parent Pipeline – 2
| Expand | ||
|---|---|---|
| ||
The project PE_Backward_Schema_Propagation_Books demonstrates the schema suggest feature of the Pipeline Execute Snap wherein a new record is inserted into the target table with the MySQL Insert Snap being the one that back-propagates schema. It contains the following Pipelines:
The record to be inserted is passed through the parent Pipeline is shown below:
The parent Pipeline must be validated in order for the child Pipeline's schema to be back propagated to the parent Pipeline. Below is the Mapper Snap in the parent Pipeline. Notice that the Target Schema section shows the three properties of the schema in the child Pipeline:
The Pipeline Execute Snap is configured as:
The child Pipeline is as shown below:
The MySQL Insert Snap is configured as shown below, note here that only specifying the table name will also suffice, the schema shown in the Mapper Snap is automatically taken from the table.
Upon execution the record (passed through the Pipeline Execute Snap) is written into the target table. This can be confirmed using a standalone MySQL Select Snap. The following screenshot shows all the records in the target table after the Pipeline is executed with the latest insert highlighted.
The exported project is available in the Downloads section below. |





Propagate Schema Backward and Forward
| Expand | ||
|---|---|---|
| ||
The project, PE_Backward_Forward_Schema_Propagation, demonstrates the Pipeline Execute Snap's capability of propagating schema in both directions – upstream as well as downstream. It contains the following Pipelines:
The parent Pipeline is as shown below: 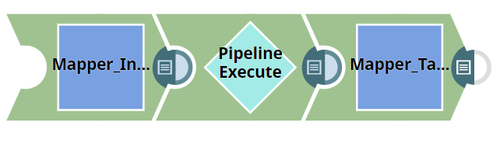 The Pipeline Execute Snap is configured to call the Pipeline schema-child. This child Pipeline consists of a Mapper Snap that is configured as shown below: 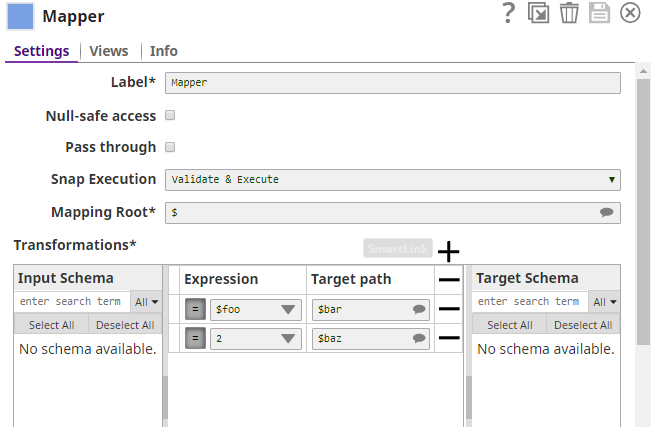 The Mapper Snaps upstream and downstream of the Pipeline Execute Snap: Mapper_InputSchemaPropagation, and Mapper_TargetSchemaPropagation are configured as shown below: 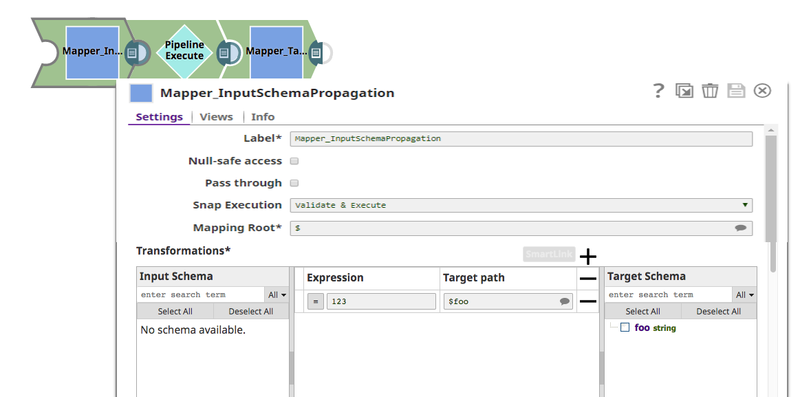 When the Pipeline is executed, data propagation takes place between the parent and child Pipeline:
The exported project is available in the Downloads section below. |
| Note |
|---|
These zip files are exported projects. They have to be imported into a project space to be used. To do this go to Manager, navigate to a project space and select Import from the drop-down menu. If you are unable to import the project, the Pipeline's files (SLP) are also included in the Download section for you to download and import. |
Downloads
| Attachments | ||
|---|---|---|
|
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|