...
Known Issues
None.
Snap Views
Type | Format | Number of Views | Examples of Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
Input | Document |
| Mapper | Input document must not contain any data other than data to be bulk-loaded. If the number of keys is smaller than the number of columns in the target table, the Snap fills missing keys with null values. If key names in the input document is different from column names, Mapper Snap can be used to map key names to column names. |
Output | Document |
| JSON Formatter | This Snap has at the most one document output view. If an output view is available, it produces the number of records loaded.Reports the bulk-load result in a key-value pair, e.g. {"status" : "34687 records loaded"} |
Error | Error handling is a generic way to handle errors without losing data or failing the Snap execution. You can handle the errors that the Snap might encounter while running the Pipeline by choosing one of the following options from the When errors occur list under the Views tab. The available options are:
Learn more about Error handling in Pipelines. | |||
Snap Settings
| Info |
|---|
|
Field Name | Field Type | Field Dependency | Description | ||
|---|---|---|---|---|---|
Label* Default Value: Azure Synapse SQL - Bulk Load | String | N/A | Specify a unique name for the Snap. | ||
Schema Name Default value: None | String/Expression | N/A | Specify the database schema name. In case it is not defined, then the suggestion for the table name retrieves all tables names of all schemas. The property is suggestible and retrieves available database schemas during suggest values. | ||
Table Name* Default Value: None | String/Expression | N/A | Specify the table name or select the table from the suggestion list to load the incoming data into. | ||
Data Source Default Value: Input View | Dropdown list | N/A | Select either of the following sources from where the data must load:
When the Data Source is Input View, the incoming data is written to a temporary file in the Snaplex and then uploaded to the staged location (Azure storage) using the Azure API. After uploading the files to Azure storage, the Snap runs the COPY INTO command to load the data from files to table. The temporary files are deleted after the execution (failed or successful) is completed. Hence, if you are running huge data Pipelines, we recommend you to configure your Snaplex instance disk space accordingly. | ||
Create table if not present Default Value: Deselected | Checkbox | Appears only when you select Input view for Data Source. | Select this checkbox to create the target table if it does not exist. Otherwise, the system displays the "table not found" error. If a target table does not exist when the Snap tries to do the bulk load, and if you select this checkbox, the Snap creates the table with the columns and data types. If you want a table to be created with the same schema as a source table, you can include a second input view for this Snap. This view can be used to pass metadata about the table, effectively allowing you to replicate a table from one database to another. The table metadata document that is read in by the second input view contains a dump of the JDBC DatabaseMetaData class. The document can be manipulated to affect the CREATE TABLE statement that is generated by this Snap. For example, to rename the name column to full_name, you can use a Mapper Snap that sets the The Snap does not automatically fix the errors encountered during table creation, because it may require user intervention to resolve correctly. For example, if the source table contains a column with a type that does not have a direct mapping in the target database, Snap fails to execute. In such a case, add a Mapper Snap to change the metadata document to explicitly set the values required to produce a valid CREATE TABLE statement. | ||
Purge files Default Value: Deselected | Checkbox | Appears only when you select External storage for Data Source. | Select this checkbox if you want to purge the data files automatically from the external storage after the data is loaded successfully.
| ||
Table Column Settings | Use this field set to define columns to map the source data to the columns in the target table. The source data can be either from the input view or external storage. | ||||
Column Name Default Vaue: N/A | String/Expression/Suggestion | N/A | Specify the column name in the target table. | ||
Default Value Default Vaue: N/A | String/Expression | N/A | Specify the default value that replaces null value if any in the input file. | ||
Source Column Position Default Value: None | String/Expression | Appears only when you select Exteranl storage for Data Source. | Specify the position of the column for the source file within a row. | ||
Add Quotes Default Vaue: Deselected | Checkbox | N/A | Select this checkbox to enclose default value in quotes. | ||
File List | Appears only when you select External source for Data Source. Use this fieldset to specify the list of files that must be loaded to the target table. | ||||
File | String/Expression | Appears only when you select External source for Data Source. | Specify the file to be loaded to the target table. | ||
File Name Pattern | String/Expression | Appears only when you select External source for Data Source. | Specify an expression or string that indicates the absolute path of the file names to match the files in the external location. | ||
File Format Type | Dropdown list | Appears only when you select External source for Data Source. | Choose one of the following file format types to load data into the target table or unload data from the target table:
When the file format type is PARQUET or ORC and you specify the FILE_FORMAT in the Copy Arguments fieldset, the Snap overrides the FILE TYPE. 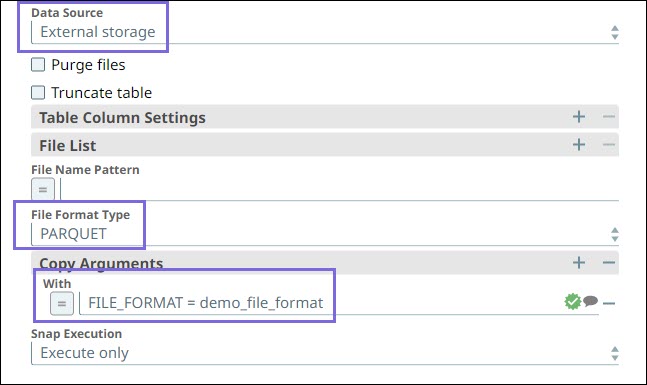 | ||
Copy Arguments | Use this fieldset to configure the list of arguments that you want the Snap to generate for the copy command. | ||||
With Default Value: None | String/Expression | N/A | Specify the list of arguments to be used when loading the data. For example, the argument With MAXERRORS=1000 enables the Snap to ignore 1000 record errors and continues with the execution of the Snap and terminates the operation after exceeding the 1000 errors. When the Data Source is Input View, this Snap suggests few copy arguments that allows you to configure the arguments. The Snap uses default values for the following properties (as shown below) to prepare the external stage file:
| ||
Parallel Transfer Options | This property enables in faster loading of data. | ||||
Max Concurrency* Default Value: 5 | Integer | N/A | Specify the maximum number of parallel requests that are to be issued at a given time as part of a single parallel transfer. | ||
Block Size (MB)* Default Value: 2 | Integer | N/A | Specify the size of data that must be chunked to transfter at a time. | ||
Snap Execution Default Value: Execute only | Dropdown list | N/A | Select one of the three modes in which the Snap executes. Available options are:
| ||
Examples
Loading Data in Bulk to Azure Synapse SQL
...
...