In this Article
| Table of Contents | ||
|---|---|---|
|
Overview
The pipeline Execution Statistics pop-up provides information on the pipeline status when executed. Likewise, when validating a pipeline, you can view Pipeline Validation Statistics.
You can view Pipeline Execution Statistics from the following locations:
In Designer, click

to open statistics for the current execution or validation of a pipeline.
In the Dashboard > Pipeline, click on the status (Completed for past statistics and Started for active statistics) in the Status column.
...
As a pipeline executes, the statistics are updated periodically so that you can monitor its progress. If the execution is successful, the Snaps should transition from Started to Completed.
Snap Statistics tab | Extra Details tab |
|---|


|

 |
The Snap Statistics tab summarizes pipeline execution time, including fractional components representing seconds. The Extra Details tab gives a precise timestamp of pipeline start and completion times, aiding in understanding execution duration.
You might notice a difference between the pipeline execution time displayed in the Snap Statistics tab and the Extra Details tab on the pipeline dashboard. For example, the Snap Statistics tab displays pipeline execution completion time as 2.30 minutes, and the Extra Details tab shows completion time from Jan 25 at 1:37:54 am till Jan 25 at 1:40:12 am.
The time displayed in the Snap Statistics tab does not represent minutes and seconds in the traditional sense. Instead, it includes a fractional component representing a portion of a second. For instance, in this example, the 0.30 fraction of the time translates to 30/100*60 = 18 seconds. The actual execution time for the pipeline would be 2 minutes and 18 seconds. This aligns with the completion time indicated in the extra Extra details tab.
Snap Statistics
This tab displays the overall statistics for each Snap on the left and the statistics for the Snap's input, output, and error views on the right. You can change the order of the Snaps in the table by selecting Dataflow or Alphabetical on the top right. The Alphabetical listing listing orders statistics by the Snap name , while Dataflow orders statistics by placing adjacent Snaps together in the table (though if two or more Snaps are at the same depth in a pipeline, they are shown in random order because of the algorithms used to sort them).
| Note |
|---|
Selecting Dataflow displays displays the order of data flow in the current instance of the pipeline, which may differ from the data flow at the time when the pipeline was executed. |
| Note |
|---|
Owners of child pipelines can access runtime logs and Snap statistics of the parent pipelines if one or more of the following is true:
|
Failures
If the pipeline fails, you see inline, which Snap failed. 
...
If a Snap writes to its error view, the row in the table will be highlighted in red:
...

The Automated Pipeline Killer prevents high memory-consuming pipelines from causing node crashes. It tracks pipeline use and reservation of heap and non-heap memory. When the committed and used memory is excessive, it prevents the exhaustion of available memory. The Automated Pipeline Killer identifies the faulty Snap responsible for the high memory utilization, kills that pipeline, and adds an error message to the Snap. The The Automated Pipeline Killer:
Considers non-heap memory versus heap memory and committed memory versus used memory.
Adds information to the node log about the utilization of heap and non-heap memory, memory pools, and buffer pools.
Improves memory tracking by considering the ratio of total committed memory to physical memory to prevent an unresponsive JCC state.
Improves the pipeline termination process by ignoring completed Snaps and considering only running Snaps. The Pipeline Execution Statistics indicate details in the UI.
The Automated Pipeline Killer is enabled for all environments by default and has a threshold setting that controls its behavior. To adjust the threshold, contact your CSM.
Warnings and Errors
Warnings might display for Snaps if a potential problem is detected that should be addressed. For example, pipelines that use a deprecated version of the Join Snap display a warning, as shown in the following image:
...
pipeline executions with warnings show up in the Dashboard with a warning icon next to their execution status for easy identification:
pipeline completed with errors—indicates that a pipeline with error pipeline that processed at least one document.

The error pipeline displays a Completed status. When you hover over the status of the main pipeline, pipeline has snaps that processed error documents is displayed.
pipeline completed with warnings—indicates that warnings occurred for Snaps in the pipeline.

The current set of warnings are as follows:
Deprecated Snap: Snaps that are no longer supported should be replaced with newer versions of the Snap to avoid any potential issues.
Passing a string to the toLocaleDateTimeString(), toLocaleDateString(), and toLocaleTimeString() methods: Early versions of these methods would only accept a JSON-encoded string for the format argument. More recent versions accept an object literal, which is significantly faster and compliant with the ECMAScript standard.
Passing a JSON-Path to the hasOwnProperty() method: The hasOwnProperty() incorrectly treated its argument as a JSON-Path instead of a plain property name.
Pipeline Status States upon Completion
When you execute a pipeline on the Designer canvas, you can view the states of execution.
When a Snap encounters warnings, the warning icon displays on the Snap, as shown in the following image:![]()
...
When a Snap encounters errors, the error icon displays on the Snap, as shown in the following image:![]()
...
Details
The columns for each Snap are as follows:
The Duration bar charts provide an overview of how long the pipeline takes during the processing of each document. The width of the chart represents the overall run time of the Snap and is broken down into three sections with different colors:
Input wait time as green.
Execution time as blue.
Output wait time as purple.
The input time and output time are how long the Snap takes waiting for its neighbor Snaps to do their processing. The execution time is how long the Snap takes to process documents. You can mouse over the Duration bar to see the exact amount of time that the Snap takes waiting or executing.
...
When optimizing a pipeline, you can use the duration bar chart to identify the bottlenecks by looking for Snaps with a large blue bar.
Ultra pipelines have an additional Idle metric that indicates how long the pipeline has been idle and not processing any documents. The idle time is subtracted from the input wait time to indicate where bottlenecks are located in an Ultra pipeline.

The CPU %, Memory, and Net columns display the average resource usage for that Snap.
The CPU usage indicates how much CPU time the Snap itself consumed while working.
The Memory column indicates how much memory is being allocated by the Snap.
The Net column shows how much data the Snap received or transmitted over the network.
your Snaplex node
If you are seeing high resource usage onyour Snaplex node, you can use these metrics to help identify the potential causes. Hovering over these columns will open a dropdown list that shows additional detail.
Each Snap has Views that accept or produce documents to be processed. Each view has its own statistics display for the number of documents processed and the rate at which the documents flow through the view.
The Bytes column populated for Snaps that have binary views and displays the total amount of data that has passed through the view.
The Documents column shows how many structured or binary documents flowed through the view.
Note title Binary Views
Binary views can send multiple documents, for example,
a ZipFile Reader Snap will output a separate binary document for each file in the Zip.
The Rate column is a rough approximation of how quickly the documents flow through the view. If the Snap has binary views, the byte rate is also displayed.
When you mouse over the resource columns in a row, the row highlights and a dropdown will appear to show even more information. The top half of the dropdown has sections which display the average usage of a resource for every document that is processed, a chart showing the last minute of activity, and the total usage of the resource over the full run-time of the Snap. The bottom line shows the version and build information for the Snap class.
...
The CPU Time displays how much the CPU is consumed.
The Wait Time displays how much time the Snap took waiting for input/output or internal processes.
The Memory Allocated displays the number of bytes that are allocated by the Snap.
noteThis number does not reflect the amount of memory that was freed, and so it does not represent the peak memory usage of the Snap. Therefore, you should not necessarily rely on using this metric to estimate the required size of a Snaplex node. Rather, this number provides an insight into how much memory had to be allocated to process all of the documents.
For example, if the total allocated was 5MB and the Snap processed 32 documents, then Snap allocated roughly 164KB per document. When combined with the other statistics, this number can help you identify the potential causes of performance issues.
Info Caveats for Network Usage Statistics
During validation, the preview data that is written to SnapLogic cloud servers may also appear in these statistics. During a regular execution, that transfer is not recorded.
Only Linux nodes are supported right now (Windows is not supported).
Snaps that use an external program to transfer data, like some database bulk loaders, do not show any network usage.
Pipeline Parameters
While this tab appears for all pipelines, it only displays information for those pipelines that are run either by a task or by another Snap (such as the pipeline the pipeline Execute Snap). Values are returned only for those parameters that have Capture selected in the the pipeline Properties dialog. 
...
Extra Details
The Extra Details tabs provides provide basic information about the pipeline and its execution, including details about pipeline type and run policy.
In the following image, the Extra Details tab displays information about an Ultra pipeline Task.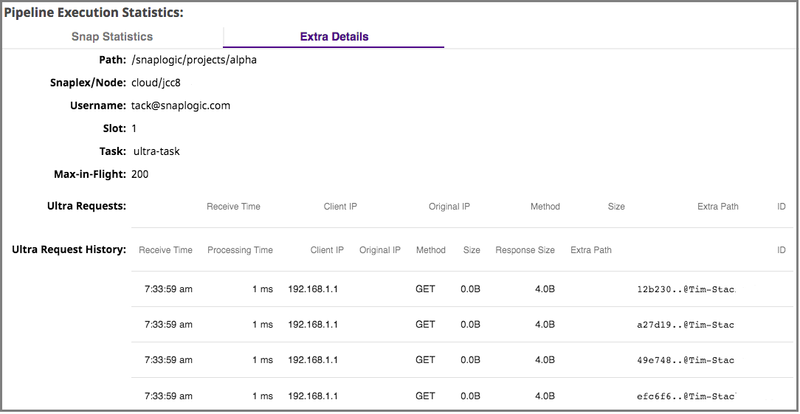
...
In the following image, the Extra Details tab displays information about a Resumable pipeline.
...
The Extra Details tab provides additional information about the pipeline run, including:
Path to the pipeline.
The Snaplex node is used to run the pipeline.
The username of the person who ran the pipeline.
The Slot Count.
SeeSee Maximum Slots on the Node Properties tab on the Update Snaplex dialog.
Resumable Mode
. Displaysdisplays as Enabled if the pipeline is resumable. If not, the status is Disabled.
The Task name
.: The name of the Task (if applicable).
The Max-In-Flight value. The maximum number of documents that can be processed by an Ultra task instance at any one time.
The Close reason for when an Ultra task goes into the Completed state.

The Stop Reason occurs when the system is unable to stop the pipeline on the node because the runtime cannot be found. The runtime status is set to Stopped, but the execution duration displayed may not be accurate. The possible execution duration is displayed in milliseconds.
Reference no longer exists or is inaccessible
Host Snaplex node restarted
The Ultra task has been updated
The task is no longer active
Closing Ultra pipeline instance to balance instances across the Snaplex
Ultra Requests. These statistics are displayed during the processing of documents.

Receive Time. The time that the request is received.
Client IP. The IP address that the FeedMaster sees when the load balancer forwards a request.
Original IP. The IP address of the external client that the load balancer, when configured to do so, forwards to the FeedMaster.
Method. The underlying HTTP method of the request.
Size. The size of the document payload in bytes.
Extra Path. The path of the Ultra pipeline task.
The Request History for Ultra tasks. These statistics display the last 100 documents processed in the Ultra pipeline.
infotitle Pipeline Monitoring API Available
You can also collect the Ultra history statistics using the pipeline Monitoring API.

Some statisticsSome statistics in common with those from the Ultra Request report are identical.
Receive Time. The time that the request is received.
Processing Time. The total time for the Ultra pipeline to process the documents associated with this request. For example, if the input document is copied, this time includes all the time needed to process each copy.
Client IP. The IP address that the FeedMaster sees when the load balancer forwards a request.
Original IP. The IP address of the external client that the load balancer, when configured to do so, forwards to the FeedMaster.
Method. The underlying HTTP method of the request.
Size. The size of the document payload in bytes.
Response Size. The size of the document in bytes payload inside the response.
Extra Path.
TheThe path of the Ultra pipeline task.
State Transition. These statistics display when multiple runs of an Ultra pipeline occur.
State. Current state of the Ultra pipeline.
Timestamp. The time that the most recent Ultra pipeline execution occurred.
Username. The username of the person invoking the Ultra pipeline.