On this Page
...
Input | This Snap has at least two document input views. |
|---|---|
| Output | This Snap has exactly one document output view. |
| Error | This Snap has at most one document error view. |
Troubleshooting
None.
Limitations and Known Issues
None.
Modes
- Ultra pipelinesPipelines: Does not work in Ultra pipelinesPipelines.
- Spark mode: Does not work in Spark mode.
Snap Settings
| Label | Required. The name for the Snap. You can modify this to be specific, especially if you have more than one of the same Snap in your pipeline. | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Policy | Specify the base and reference datasets and fields. | ||||||||||
| Base view | The input view to which the base dataset is connected. Default value: input0 (name of the input view) | ||||||||||
| Base path | The field in the base dataset that is to be used as the base field. This has to be the common identifier for joining with the reference dataset. Example: $customer_id Default value: [None] | ||||||||||
| Ref view | View where the reference dataset is the input. Default value: input0 (name of the input view) | ||||||||||
| Ref path | The field in the reference dataset that is to be used. This field must have the same values as in the base field. Example: $customer_id Default value: [None] | ||||||||||
|
|
...
| Expand | ||
|---|---|---|
| ||
The base dataset in this example is a collection of customer records. It has the following fields:
The reference dataset is a collection of transactions made by the customers listed in the base dataset. It has the following fields:
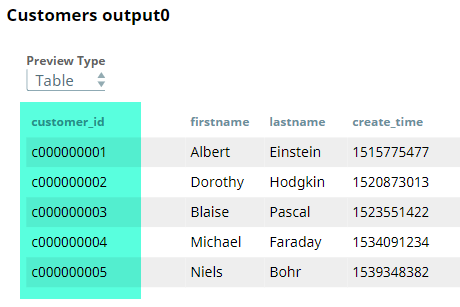
Both datasets are provided by the CSV Generator Snaps titled Customers and Transactions. These are passed through a Type Converter Snaps so that all data types are mapped correctly. This is required to enable the Feature Synthesis Snap to generate features accurately. A preview of the customer and transaction datasets that are output by the CSV Generator Snaps is as shown below:
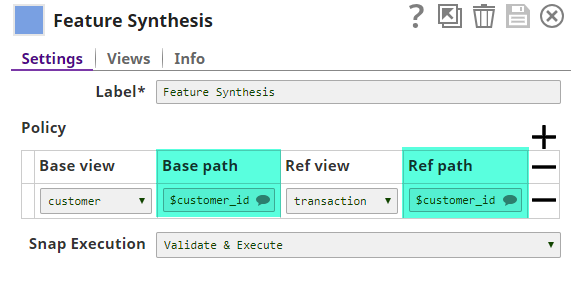
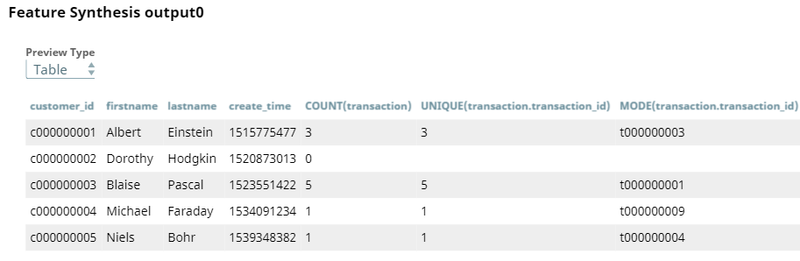
The field $customer_id is common between both datasets. The Feature Synthesis Snap will use this field to join datasets and is configured as shown below: The customer dataset is connected to the first input view (titled customer); so this view becomes the Base view. Similarly, the transaction dataset is connected to the second input view (titled transaction); so that becomes the Ref view. Upon successful execution, the Feature Synthesis Snap generates features and adds them to the base dataset as shown below:
The same output is shown in a JSON format to let you see the full list of features:
Download this Pipeline. |

Downloads
| Multiexcerpt include macro | ||||
|---|---|---|---|---|
|
| Attachments | ||
|---|---|---|
|
Additional Resources
...
...
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|