...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
Snap type:
Write
...
Description:
This Snap executes a SQL Merge with the given properties. The documents that are provided in the input view will be merged into the provided table on the provided database. Each document on the input view is expected to be merged or created with/as a new record in the table.
This Snap supports SQL Server 2008 or newer.
| Note |
|---|
Merges will be batched up until the account's batch size property or until the structure of the update statement changes. An update statement will change if an incoming document contains different keys than a previous document. |
The merge condition can only use variables, no constants or pipeline parameters.
...
In this article
| Table of Contents | ||||
|---|---|---|---|---|
|
Overview
You can use this Snap to execute a SQL Merge with the specified properties.
The merge condition can only use variables; it does not support constants and pipeline parameters. For example
SALARY =$SALARY(here, we use the SALARY variable of the input document).
...
However, if you use
SALARY = '100000'(
...
the Snap cannot process this condition, because the provided columns in the condition are validated against the types defined in the table schema).
...
| Note |
|---|
While the expression toggle is available on the Merge Condition field, use of the expression toggle on the merge condition is not encouraged. |
...
You can rewrite this condition by using an upstream Mapper Snap, where '10000' is mapped to the SALARY variable, which then can be used in the
...
Merge condition as defined
...
in the earlier example. The same applies
...
to pipeline parameters, which
...
should be mapped upstream similarly using a Mapper Snap.
Expected upstream Snaps: The columns of the selected table need to be mapped upstream using a Mapper Snap. The Mapper Snap will provide the target schema,which reflects the schema of the table that is selected for the merge Snap.
Expected downstream Snaps: The Snap will output one document for every record merged, hence any document processing Snap can be used downstream.
...
Merges are batched until the account's batch size property or until the structure of the update statement changes. An update statement changes if an incoming document contains different keys than a previous document.
While the expression enabler is available on the Merge condition field, we recommend you to minimize the usage of the expression enabler for the Merge condition field.
...
Snap Type
SQL Server - Merge Snap is a Write-type Snap that executes an SQL Server merge.
Prerequisites
None.
Supported Versions
This Snap supports SQL Server 2008 or higher versions.
Support for Ultra Pipelines
Works in Ultra Pipelines.
Limitations & Known Issues
None.
Snap Views
Type | Format | Number of Views | Examples of Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
Input | Document |
|
| The documents that are provided in the input view will be merged into the provided table on the provided database. Each document on the input view is expected to be merged or created with/as a new record in the table. |
Output |
...
Document |
...
None
...
- Ultra pipelines: May work in Ultra Pipelines.
- Spark mode: Not supported in Spark mode.
...
This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See SQL Server Account for information on setting up this type of account.
...
|
| If an output view is available, then the original document that was used to create the statement will be output with the status of the merge executed. A document which represents the status of the merge operation for that document. Each merge operation is represented as one document in the output view. | |
Error |
This Snap has at most one error view and produces zero or more documents in the view.
| Note |
|---|
| Because the Snap must report what is reported by the database, the Snap sends all records to the error view and no record to the output view. If you want to see accurate results for each row you must set the batch size to 1 and execute the pipeline. |
...
Settings
Label
...
Error handling is a generic way to handle errors without losing data or failing the Snap execution. You can handle the errors that the Snap might encounter when running the Pipeline by choosing one of the following options from the When errors occur list under the Views tab:
Learn more about Error handling in Pipelines. |
Snap Settings
| Info |
|---|
|
Field Name | Field Type | Description |
|---|---|---|
Label* Default Value: SQL Server - Merge | String | Specify the name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. |
Schema |
...
name Default Value: N/A | String/Expression | Specify the database schema name. In case it is not defined, then the suggestion for the Table Name will retrieve all |
|---|
...
tables names of all schemas. The property |
...
is suggestible |
...
and will retrieve available database schemas during suggest values. |
...
Table Name
...
The values can be passed using the pipeline parameters but not the upstream parameter. |
Example: SYS
Default value: [None]
Table name* Default Value: N/A | String/Expression | Specify the table to execute the merge on. |
|---|
...
The values can be passed using the pipeline parameters but not the upstream parameter. |
Number of Retries Default Value: 0 |
|---|
...
Default value: [None]
...
Merge condition
...
: 3 | Integer/Expression | Specify the maximum number of attempts to be made to receive a response. The request is terminated if the attempts do not result in a response.
|
|---|---|---|
Retry Interval (Seconds) Default Value: 1 | Integer/Expression | Specify the time interval between two successive retry requests. A retry happens only when the previous attempt resulted in an exception. When you enable retry and a connection failure occurs that cannot be recovered by retry, the Snap writes a connection failure error in the error view. In some cases, the error view records might contain duplicate data that was written to the database. Ensure to verify all the records in the error file before you restart the merge request. You can locate the duplicate records in the error view by checking the $reason property for the sub-string: Connection is not available, request timed out. |
Merge condition* Default Value: N/A | String/Expression | Specify the ON condition of the merge statement. A boolean-type expression is expected. |
...
See Merge Syntax for an explanation of merge syntax |
...
Default value: [None]
...
Identity column
...
. | ||
Identity column Default Value: N/A | String/Expression | Specify the table's identity column. If this is not set and the column is set to be generated always, then the merge will fail. |
|---|---|---|
Enable identity insert Default |
...
Execute during preview
This property enables you to execute the Snap during the Save operation so that the output view can produce the preview data.
Default value: Not selected
Examples
...
Value: Deselected | Checkbox | Select the check box to insert values from the input document into the target table identity column. Ensure that the target table contains an identity column. If you do not select the check box, then the Snap strips any value that is meant for the identity column from the input document. | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Default Value: Validate & Execute | Dropdown list |
|
Examples
Merge data into a table
The following example pipeline demonstrates how to merge data into a specific table using the SQL Server Merge Snap.
...
In this example, two documents with customer information from upstream Snap are passed to the downstream Snap.
Configure the JSON Generator Snap to pass customer-related data (input data) as shown below.
...
Configure the SQL Server - Merge Snap as shown below. The customer data needs to be merged into a table called customer1. One of the documents has the data of existing
...
customers with an updated 'phoneno' field and
...
another document is of a new customer.
Following is the sample pipeline:
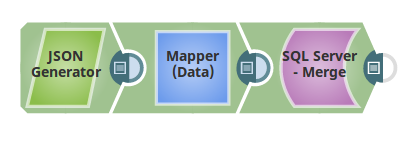
Input data is passed using the JSON Generator Snap. Following is the sample data passed:
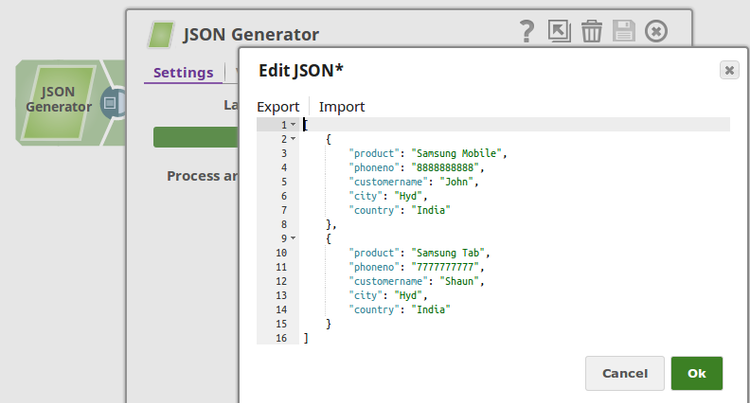
...
Once the Merge Snap execution completes, the record with customername 'John'
...
is updated with phoneno, and a new record is created for customer 'Shaun'.
...

...
The output is as follows:
...
Related Information
...
...
Snap Pack History
| Expand | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
...