| Table of Contents |
|---|
Overview
This account is used by the Snaps in the Hive Snap Pack. The account can be configured with and without Kerberos and supports SSL connection.
You can create an account from Designer or Manager. In Designer, when working on pipelines, every Snap that needs an account prompts you to create a new account or use an existing account. The accounts can be created in or used from:
- Your private project folder: This folder contains the pipelines that will use the account.
- Your Project Space’s shared folder: This folder is accessible to all the users that belong to the Project Space.
- The global shared folder: This folder is accessible to all the users within an organization in the SnapLogic instance.
Account Configuration
In Manager, you can navigate to the required folder and create an account in it (see Accounts). To create an account for a generic JDBC driver:
- If you have not already done so, upload the JDBC driver for this database as a file for the specific project.
- Click Create, then select Hive > Hive Database Account or Generic Hive Database Account (as required).
- Supply an account label.
- Supply the necessary properties for your database.
- Supply the necessary JDBC driver jars for your driver.
- (Optional) Supply additional information on this account in the Notes field of the Info tab.
- Click Apply.
| Warning |
|---|
Avoid changing account credentials while pipelines using them are in progress. This may lead to unexpected results, including locking the account. |
Account Types
Hive Database Account
Account Settings
Label
Account properties
Hostname
Required. The server address to connect to.
Default value: [None]
Port number
Required. The database server's port to connect to.
Default value: 10000
Database name
Default value: [None]
Username
Username that is allowed to connect to the database. Username will be used as the default username when retrieving connections. The username must be valid in order to set up the data source.
Example: Snapuser
Default value: [None]
Password
Password used to connect to the data source. Password will be used as the default password when retrieving connections. The password must be valid in order to set up the data source.
Example: Snapuser
Default value: [None]
JDBC jars
List of JDBC JAR files to be loaded. A different driver binary for a driver must have a different name, the same name can not be reused for a different driver. If this property is left blank, a default JDBC driver will be loaded.
Example: hiveJDBC4
Default value: [None]
| Note |
|---|
|
JDBC Driver Class
Required. The JDBC Driver class name to use.
Example: com.vertica.jdbc.Driver
Default value: [None]
Advanced Properties
Auto commit
optional
If false (not selected), then a transaction is started for the Snap run and committed upon run success. The transaction will be rolled back if the Snap fails.
Default value: Selected
| Note |
|---|
For a DB Execute Snap, assume that a stream of documents enter the input view of the Snap and the SQL statement property has JSON paths in the WHERE clause. If the number of documents are large, the Snap executes in more than one batches rather than executing one per each document. Each batch would contain a certain number of WHERE clause values. If Auto commit is turned on, a failure would only roll back the records in the current batch. If Auto commit is turned off, the entire operation would be rolled back. For a single execute statement (with no input view), the setting has no practical effect. |
Batch size
Required. Number of statements to execute at a time.
Using a large batch size could use up the JDBC placeholder limit of 2100.
Example: 10
Default value: 50
Fetch size
Required. Number of rows to fetch at a time when executing a query.
Large values could cause the server to run out of memory.
Example: 100
Default value: 100
Max pool size
Required. Maximum number of idle connections a pool will maintain at a time.
Example: 10
Default value: 50
Max idle time
Required. Minutes a connection can exist in the pool before it is destroyed.
Example: 30
Default value: 30
Idle connection Test period
Default value: 5
Checkout timeout
Required. Number of milliseconds to wait for a connection to be available in the pool. Zero waits forever. After set time, then an exception will be thrown and the pipeline will fail.
Example: 10000
Default value: 10000
Url Properties
Properties to use in JDBC Url.
Example: maxAllowedPacket | 1000
Default value: [None]
Authentication method
Required. Authentication method to use when connecting to the Hadoop service.
- None: Allows connection even without the Username and Password
- Kerberos: Allows connection with Kerberos details such as Client Principal, Keytab file, and Service principal
- User ID: Allows connection with Username only
- User ID and Password: Allows connection with Username and Password
Default value: None
Use Zookeeper
Specifies if Zookeeper be used to locate the Hadoop service instead of a specific hostname.
If the checkbox is selected, we should use Zookeeper to resolve the location of the database instead of using the 'hostname' field in the standard block.
Default value: Not selected
Zoo Keeper URL
If you intend to use Zookeeper, then you must provide the following details:
You must provide the URL of the Zookeeper service. Zookeeper URL formats are different for CDH and HDP.
- For HDP:
- Format: hostname1:port,hostname2:port/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2
- Example: na77sl-ihdc-ux02011.clouddev.snaplogic.com:2181,na77sl-ihdc-ux02012.clouddev.snaplogic.com:2181,na77sl-ihdc-ux02013.clouddev.snaplogic.com:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2
- For CDH:
- Format: zk=hostname1:port,hostname2:port/hiveserver2
- Example: Zk = jdbc:hive2://cdhclusterqa-1-1.clouddev.snaplogic.com:2181,cdhclusterqa-1-2.clouddev.snaplogic.com:2181,cdhclusterqa-1-3.clouddev.snaplogic.com:2181/hiveserver2
Default value: None
| Note |
|---|
This is NOT the URL for the Hadoop service being sought. |
JDBC Subprotocol
Required. JDBC Subprotocol to be used. The options available are Hive and Impala.
Default value: Hive
Client Principal
Used to authenticate to Kerberos KDC (Kerberos Key Distribution Center - Network service used by the clients and servers for authentication).
Default value: [None]
Keytab file
Keytab file(file used to store encryption keys) used to authenticate to Kerberos KDC.
Default value: [None]
Service principal
Principal used by an instance of a service.
Examples:
- If you are connecting to a specific server:
- hive/host@REALM or impala/host@REALM
- If you are connecting(more common for the Snap) to any compliant host (see Use Zookeeper property's description) in which case the principal is:
- 'hive/_HOST@REALM' or 'impala/_HOST@REALM'.
Default value: [None]
Generic Hive Database Account
Account Settings
Label
Account properties
Username
Username that is allowed to connect to the database. Username will be used as the default username when retrieving connections. The username must be valid in order to set up the data source.
This is not a mandatory field.
Example: Snapuser
Default value: [None]
Password
Password used to connect to the data source. Password will be used as the default password when retrieving connections. The password must be valid in order to set up the data source.
This is not a mandatory field.
Example: Snapuser
Default value: [None]
JDBC URL
The URL of the JDBC database.
Example: jdbc:hive://hostname/dbname;sasl.qop=auth-int
Default value: [None]
JDBC jars
List of JDBC JAR files to be loaded. A different driver binary for a driver must have a different name, the same name can not be reused for a different driver. If this property is left blank, a default JDBC driver will be loaded.
Example: hiveJDBC4
Default value: [None]- The JDBC driver can be uploaded through Designer or Manager and it is stored on a per-project basis. That is, only users with access to that project will see JDBC drivers uploaded. To provide access to all users of your org, place the driver in the /shared project.
- See Advanced Configurations: Configuring Hive with Kerberos section below for a list of JAR files to be uploaded when configuring Hive with Kerberos.
JDBC Driver Class
Required. The JDBC Driver class name to use.
Example: com.vertica.jdbc.Driver
Default value: [None]
Advanced Properties
Auto commit
If false (not selected), then a transaction is started for the Snap run and committed upon run success. The transaction will be rolled back if the Snap fails.
Default value: Selected
For a DB Execute Snap, assume that a stream of documents enter the input view of the Snap and the SQL statement property has JSON paths in the WHERE clause. If the number of documents are large, the Snap executes in more than one batches rather than executing one per each document. Each batch would contain a certain number of WHERE clause values. If Auto commit is turned on, a failure would only roll back the records in the current batch. If Auto commit is turned off, the entire operation would be rolled back. For a single execute statement (with no input view), the setting has no practical effect.
Batch size
Required. Number of statements to execute at a time.
Using a large batch size could use up the JDBC placeholder limit of 2100.
Example: 10
Default value: 50
Fetch size
Required. Number of rows to fetch at a time when executing a query.
Large values could cause the server to run out of memory.
Example: 100
Default value: 100
Max pool size
Required. Maximum number of idle connections a pool will maintain at a time.
Example: 10
Default value: 50
Required. Minutes a connection can exist in the pool before it is destroyed.
Example: 30
Default value: 30
Default value: 5
Required. Number of milliseconds to wait for a connection to be available in the pool. Zero waits forever. After set time, then an exception will be thrown and the pipeline will fail.
Example: 10000
Default value: 10000
Url Properties
Properties to use in JDBC Url. These properties will need to be configured when setting up SSL connection. See Additional Configurations: Configuring Hive with SSL section below for details.
Example: maxAllowedPacket | 1000
Default value: [None]
Authentication method
Required. Authentication method to use when connecting to the Hadoop service.
- None: Allows connection even without the Username and Password
- Kerberos: Allows connection with Kerberos details such as Client Principal, Keytab file, and Service principal
- User ID: Allows connection with Username only
- User ID and Password: Allows connection with Username and Password
Default value: None
Use Zookeeper
Specifies if Zookeeper be used to locate the Hadoop service instead of a specific hostname.
If the checkbox is selected, we should use Zookeeper to resolve the location of the database instead of using the 'hostname' field in the standard block.
Default value: Not selected
If you intend to use Zookeeper, then you must provide the following details:
You must provide the URL of the Zookeeper service. Zookeeper URL formats are different for CDH and HDP.
- For HDP:
- Format: hostname1:port,hostname2:port/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2
- Example: na77sl-ihdc-ux02011.clouddev.snaplogic.com:2181,na77sl-ihdc-ux02012.clouddev.snaplogic.com:2181,na77sl-ihdc-ux02013.clouddev.snaplogic.com:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2
- For CDH:
- Format: zk=hostname1:port,hostname2:port/hiveserver2
- Example: Zk = jdbc:hive2://cdhclusterqa-1-1.clouddev.snaplogic.com:2181,cdhclusterqa-1-2.clouddev.snaplogic.com:2181,cdhclusterqa-1-3.clouddev.snaplogic.com:2181/hiveserver2
Default value: None
| Note |
|---|
This is NOT the URL for the Hadoop service being sought. |
JDBC Subprotocol
Conditional. This is required when the Authentication method is Kerberos. JDBC Subprotocol to be used. The options available are Hive and Impala.
Default value: Hive
Kerberos properties
Client Principal
Used to authenticate to Kerberos KDC (Kerberos Key Distribution Center - Network service used by the clients and servers for authentication).
Default value: [None]
Keytab file
Keytab file(file used to store encryption keys) used to authenticate to Kerberos KDC.
Default value: [None]
Service principal
Principal used by an instance of a service.
Examples:
- If you are connecting to a specific server:
hive/host@REALM or impala/host@REALM - If you are connecting(more common for the Snap) to any compliant host (see Use Zookeeper property's description) in which case the principal is:
'hive/_HOST@REALM' or 'impala/_HOST@REALM'.
Default value: [None]
Account Encryption
If you are using Standard Encryption, the High sensitivity settings under Enhanced Encryption are followed.
If you have the Enhanced Account Encryption feature, the following describes which fields are encrypted for each sensitivity level selected for this account.
Account:
- High: Password, Key tab file
- Medium + High: Password, Key tab file
- Low + Medium + High: Password, Key tab file
Additional Configurations
Configuring Hive with Kerberos
Following is the recommended list of JARs to be uploaded for the JDBC4 drivers on Hive with Kerberos:
- hive_metastore.jar
- hive_service.jar
- HiveJDBC4.jar
- libfb303-0.9.0.jar
- libthrift-0.9.0.jar
- TCLIServiceClient.jar
Configuring Hive with SSL
The following URL properties have to be configured:
In this article
| Table of Contents | ||||||
|---|---|---|---|---|---|---|
|
In this section
| Child pages (Children Display) |
|---|
Overview
You must create Hive accounts to connect to data sources that you want to use in your Pipelines. You can configure your Teams accounts in SnapLogic using either the Designer or Manager.
For more information on SnapLogic Accounts, refer to Accounts.
Configuring Hive Accounts Using SnapLogic Designer
Drag a Hive Snap to the Canvas and click the Snap to open its settings. Click the Account tab. You can now either use an existing account or create a new one.
Selecting an existing account
SnapLogic organizes and displays all accounts to which you have access, sorting them by account type and location. To select an existing account:
In the Account tab, click the dropdown
 icon to view the accounts to which you have access, and select the account that you want to use.
icon to view the accounts to which you have access, and select the account that you want to use.Click the Save
icon.
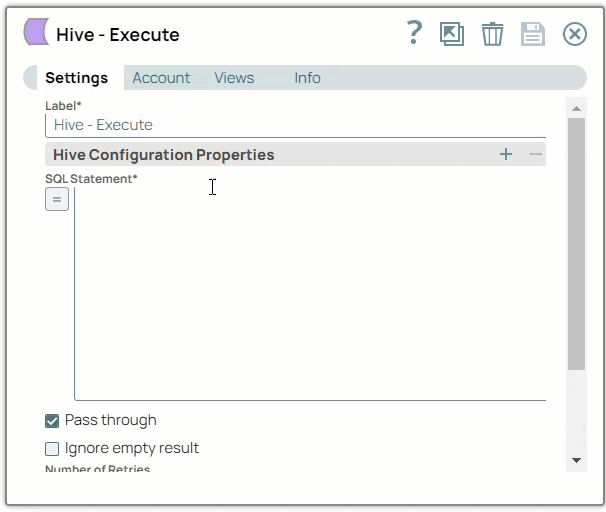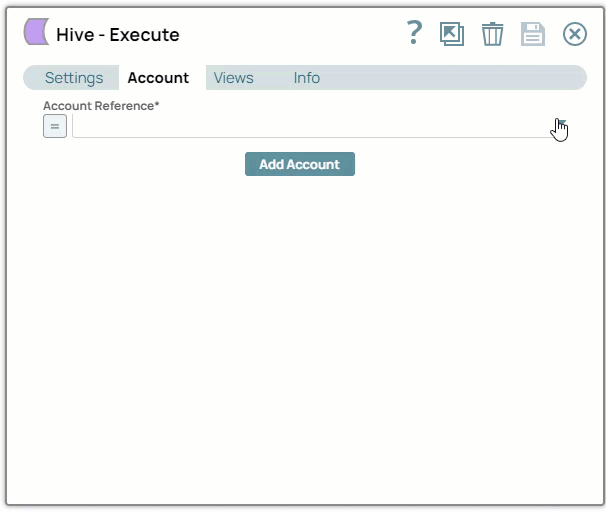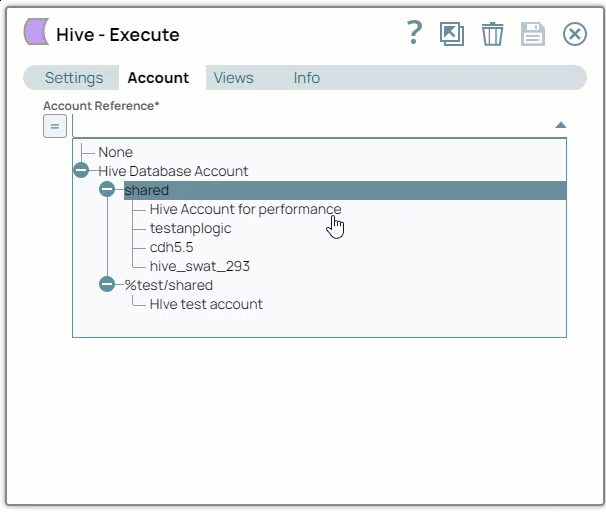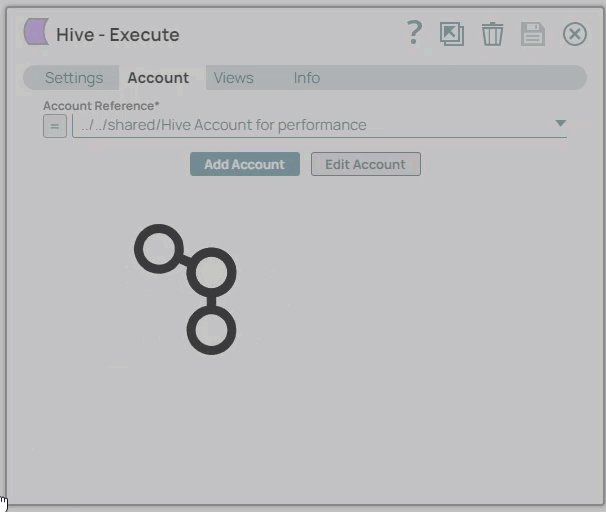
Creating an account
In the Account tab, click Add Account below the Account Reference field.
Select the Location in which you want to create the account, select the Account Type, and click Continue. The Add Account dialog window associated with the account type is displayed.
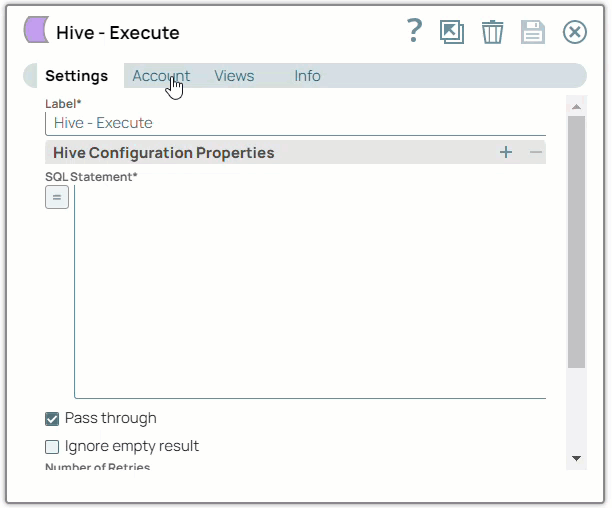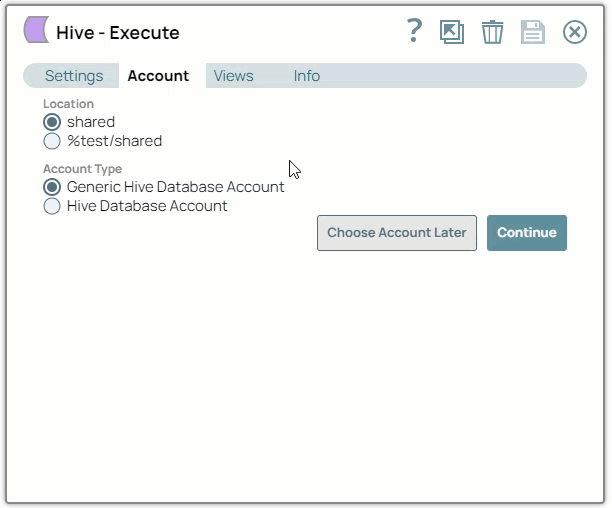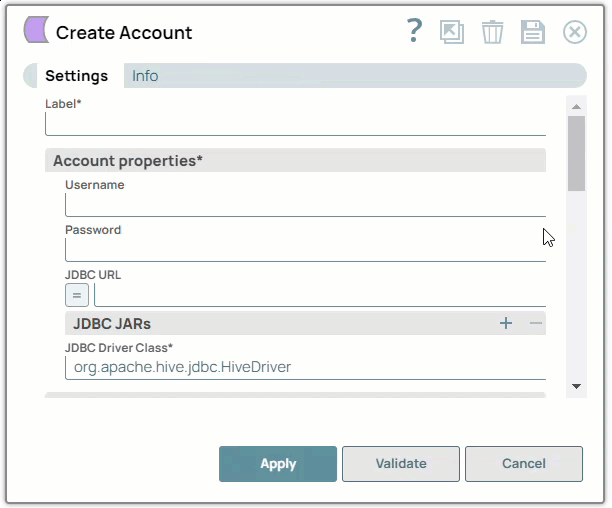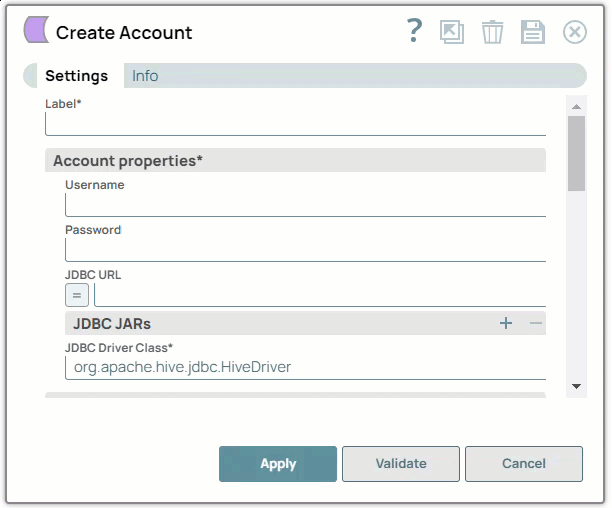
Enter the required account details. For detailed guidance on how to provide the information required for each account type, refer to Generic Hive Database Account and Hive Database Account.
Click Validate to verify the account, if the account type supports validation.
Click Apply to complete configuring the Hive account.
| Info |
|---|
Enter additional information on this account in the Notes field of the Info tab. This will help you–and other users–understand the purpose of the account, especially if there are multiple accounts of the same type. |
Configuring Hive Accounts Using SnapLogic Manager
You can use Manager to create accounts without associating them immediately with Pipelines.
Accounts in SnapLogic are associated with projects. You can use accounts created in other projects only if you have at least Read access to them.
In the left pane, browse to the project in which you want to create the account and click
> Account > Hive, followed by the appropriate account type. The Create Account dialog associated with the selected account type is displayed.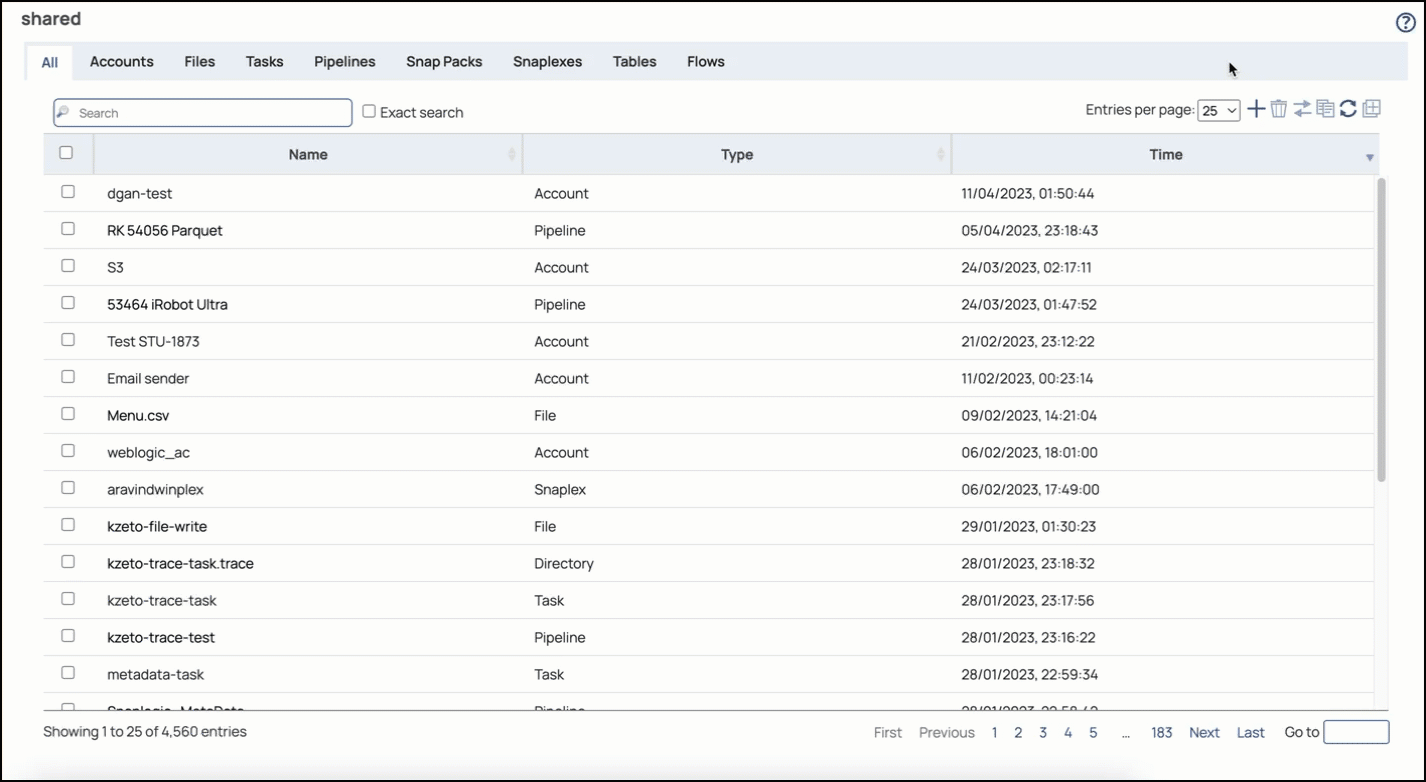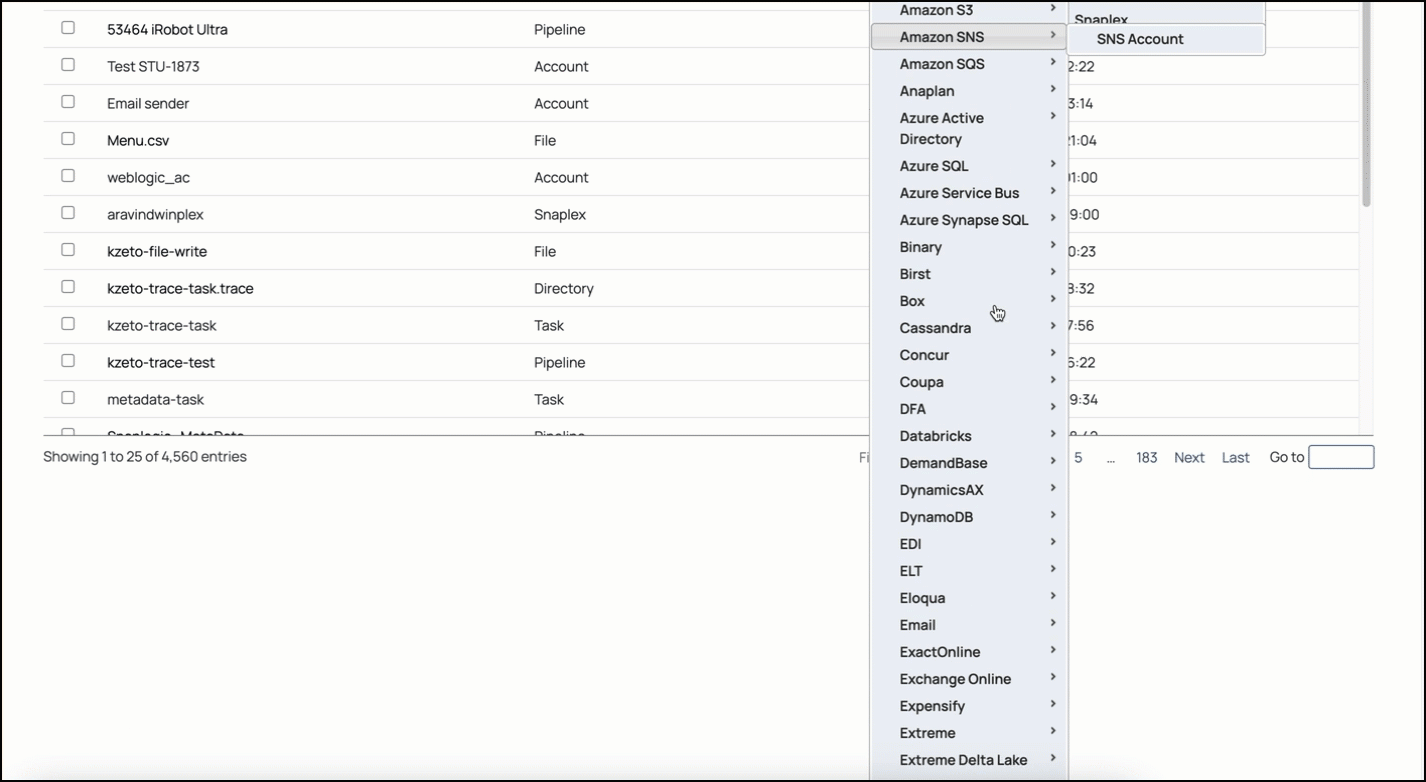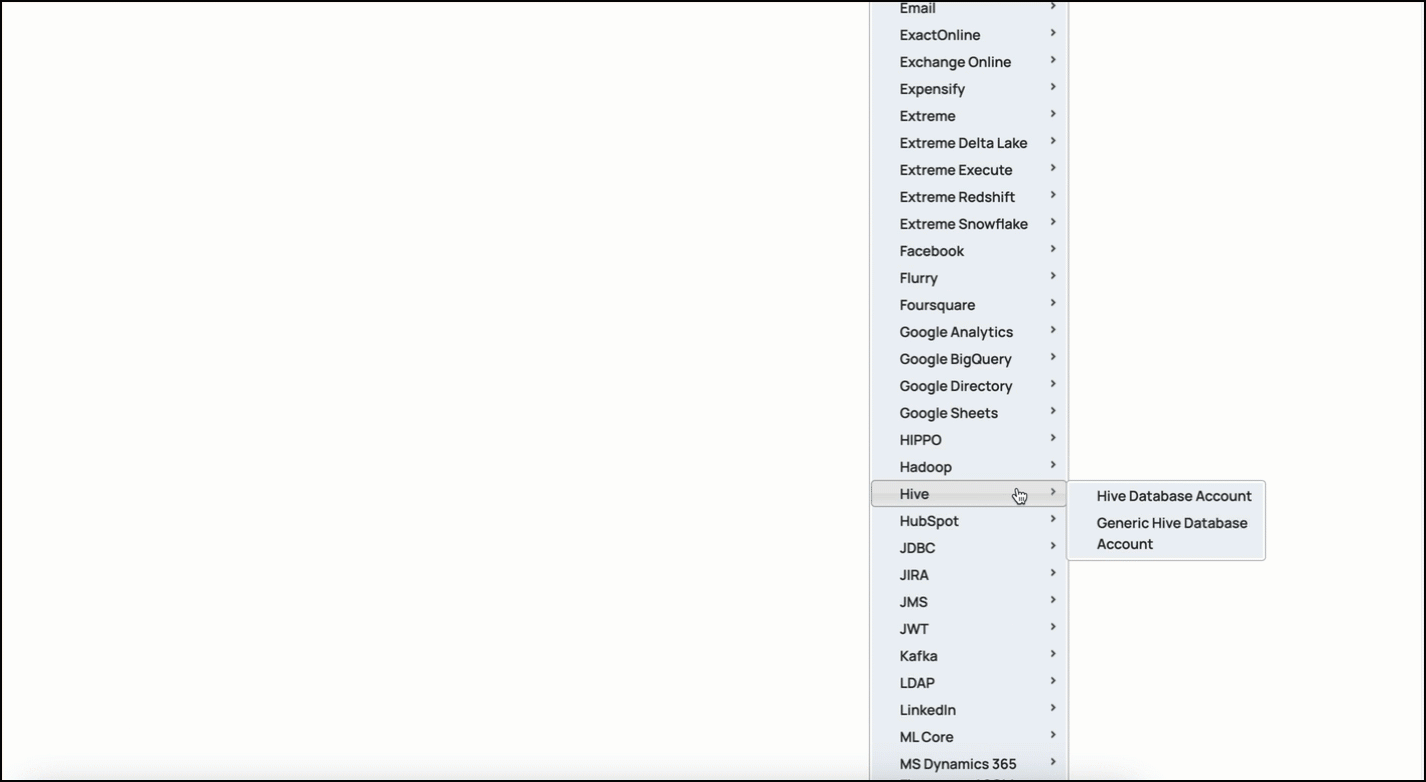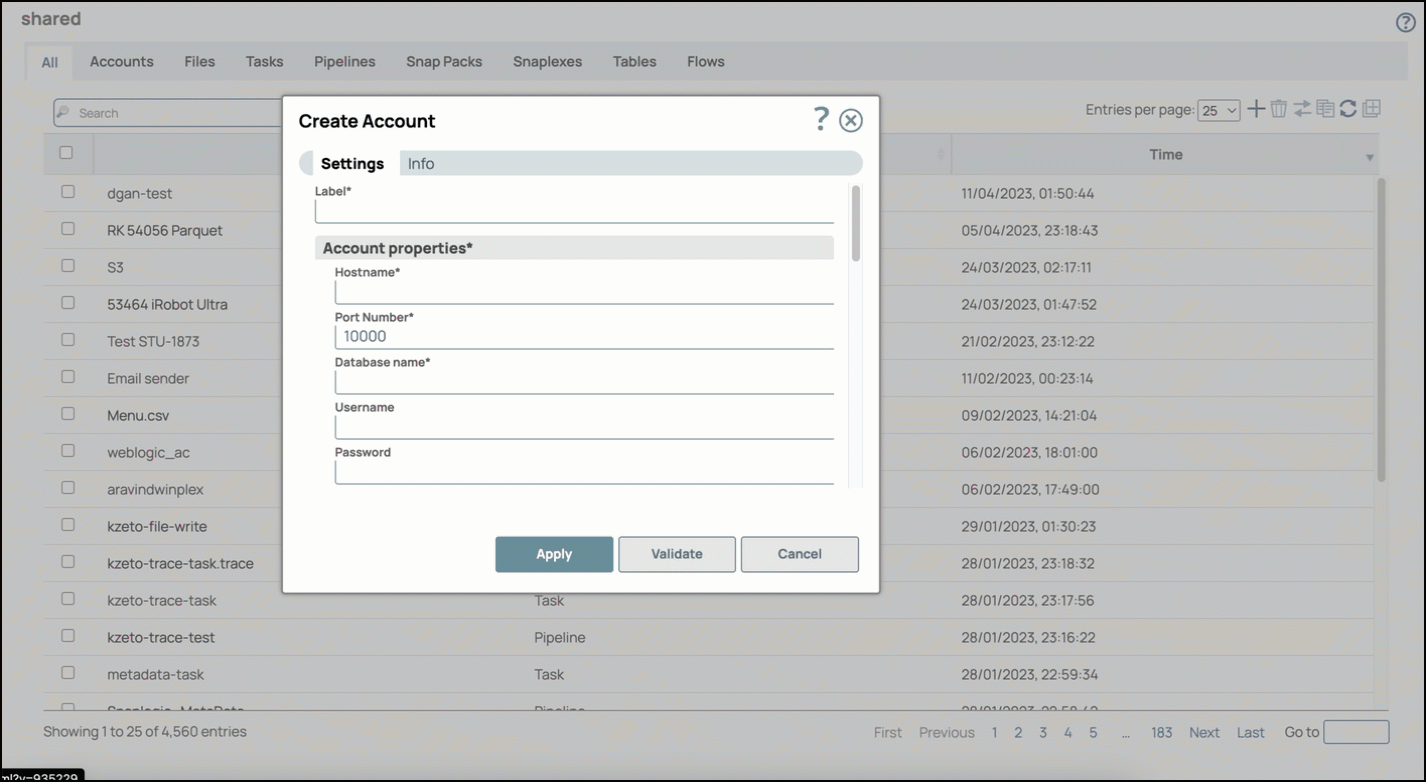
Repeat the steps numbered 3 through 5 in the Creating an account section.
Avoid updating account credentials while Pipelines using that account are executing. Doing so may lead to unexpected results, including your account getting locked.
Additional Configurations
Configuring Hive with SSL
Add the following properties to the Url properties table to configure Hive with SSL. These configurations work only with Groundplexes and not Cloudplexes.
URL Property Name | URL Property Value |
|---|---|
ssl | Required. Binary value to denote that SSL is enabled. This value must always be 1. |
sslTrustStore | Required. |
The path of |
SSL |
Trust store key file pointing to a JKS, PEM or CER file. The file can be referenced from the Groundplex's file system. | |
sslTrustStorePassword | Required. |
Password configured for the SSL |
Trust store. | |
AllowSelfSignedCerts | Binary value to denote |
whether the driver allows the server to use self-signed SSL certificates |
. Pass the value 1 to allow the use. | |
CAIssuedCertNamesMismatch | Binary value to denote that the driver requires the CA issued SSL certificate's name |
to match the host name of the Hive server. |
Pass the value 1 to indicate the names must match. |
| Info |
|---|
The above list is specific to Hive with or without Kerberos enabled. With Kerberos enabled, the properties such |
as Client Principal, |
Key tab file |
Testing Environment
Hive Version: Hive 1.1.0and Service principal have to be additionally provided. |
Limitations or known issues
"Method not supported" error while validating Apache Hive JDBC v1.2.1 or earlier
The Hive Snap Pack does not validate with Apache Hive JDBC v1.2.1 jars or earlier because of a defect in Hive. HDP 2.6.3 and HDP 2.6.1 run on Apache Hive JDBC v1.2.1 jars.
To validate Snaps that must work with HDP 2.6.3 and HDP 2.6.1, use JDBC v2.0.0 jars.
Supported Versions
Hive Version: Hive 1.1.0, Hive 1.2.0, Hive 3.1.3
Hive with Kerberos works only on Hive JDBC4 driver 2.5.12 and above
Hive with SSL
works only on Hive JDBC4 driver 2.5.12 and above.
Cluster Versions: CDH 5.
| borderColor | black |
|---|---|
| borderWidth | 1 |
| borderStyle | solid |
| title | Account History |
4.14 (snapsmrc490)
- Added a new account type: Generic Hive Database Account, this enables connecting to different types of clusters using JDBC URL.
4.8.0
Info tab added to accounts.
Database accounts now invalidate connection pools if account properties are modified and login attempts fail.
4.7.0
Enabled the account with Kerberos authentication.16, CDH 6.1.1 , HDP 3.1.4, HDP 2.6.5, CDP 7.1.7
Snap Pack History
| Expand | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|