On this Page
On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
Snap Type: | Transform | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Description: | This Snap reads JSON document data from its input view, and formats and writes it as JSON binary data to its output view. A schema file can also be attached to the Snap that allows it to share the schema with upstream Snaps like the Mapper Snap. | |||||||||||||
| Prerequisites: | None | |||||||||||||
| Support and limitations: | Works in Ultra Task Pipelines if Format each document is selected. | |||||||||||||
| Account: | Accounts are not used with this Snap. | |||||||||||||
| Views: |
| |||||||||||||
Settings | ||||||||||||||
Label | Required. The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your Pipeline. | |||||||||||||
| Schema | For uploading JSON schema files, this is helpful when the formatted JSON has to follow a certain schema. This is particularly useful when used with Mapper Snap, the schema from the JSON Formatter Snap will be back-propagated to the Mapper Snap. This is a suggestible property, click on the browse button to select file from your project folder. Example: contact.schema Default value: [None]
| |||||||||||||
| Binary Header Properties | The properties to add to the binary document's header. The properties in the header of a binary document can be accessed in expression properties of downstream Snaps. For example, a 'content-location' property added to the header in this Snap can be referenced in the file name property of a File Writer snap with the expression: $['content-location']. When this Snap is configured to output a single binary document, the headers are computed from the first input document. When the "Format each document" option is enabled, the headers are computed separately for each binary output. | |||||||||||||
| Expression | Enter the function to be used to transform the data such as combine, concat or flatten. Default value: None | |||||||||||||
| Target Path | Enter in the target JSON path where the value from the expression will be written. Example: $person.firstname to write the field ' Default value: None | |||||||||||||
| Content | The input object or field whose data must be written to the output stream. For example, $group, $payload or $emp_salary. Use $ to write the entire data. See Filtering Output Data Using the JSON Formatter Snap's Content Setting further in this page for filtering the input data based on the Content field. Default value: $ | |||||||||||||
Ignore empty stream | Required in Standard mode. The Ignore empty stream property specifies that an empty array will be written to the output view in case no documents were received on the input view (disabled). Default value: Not Selected | |||||||||||||
Format each document | If enabled, the property defines that Snap creates one binary output stream is created for every document on its input view. If disabled, will write it writes one binary output stream for all documents on its input view which are enclosed by a JSON array element [ .. ]. See See the example: Using Using JSON Formatter Snap to render outputs from Group By Snaps, for a simple but less-frequent scenario. Default value: Not Selected | If selected, writes all documents to a single output file, with each document
Default value: Not selected | ||||||||||||
JSON lines | If selected, the Snap writes all documents to a single output file, with each document appearing as a single line followed by a new line. This field cannot be used with Pretty-print properties check box. See the example: Using JSON Formatter Snap to render outputs from Group By Snaps, for for a simple but less-frequent scenario.
Default value: Not selected | |||||||||||||
Pretty-print | If enabled, formats the output to make it more readable/printable. Default value: Not Selected | |||||||||||||
Derive Schema from a Sample Size of* | Required Select the size of the number of initial input documents to be used when deriving the schema to be added to the binary output header. The sizing that you choose depends on the uniformity of the source schema. For example, if the schema is uniform across the documents, then choose Small. If the schema differs from document to document, then choose a larger size (Medium or Large) to attain a more accurate sampling of your schema. The performance impact on the Pipeline execution/validation is greater, the larger the sample size is. If you select None, then the schema is not sampled. | |||||||||||||
|
| |||||||||||||
Examples
| |||
Examples
Using JSON Formatter Snap to render outputs from Group By Snaps
This example demonstrates how
, effective 4.23 GA and onwards, youyou can use the JSON Formatter Snap to render groups data from upstream Snaps such as Group By Fields Snap.
In a scenario where the JSON Formatter Snap needs to format
groups in the incoming datadata groups, we can enhance
Snapthe Snap's output to
haveformat each group
renderedas a separate
outputdocument, where each line is a member
of the group.
of the group.
We use the JSON Generator Snap to pass the raw JSON content to be formatted.
| JSON Generator Snap | Output (JSON content to be formatted) |
|---|---|
|
|
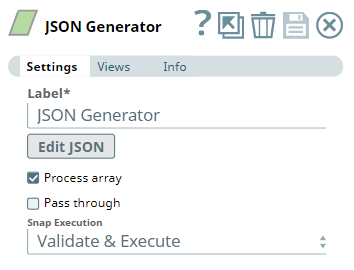
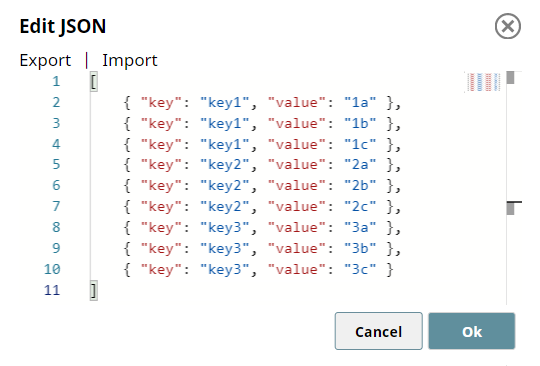
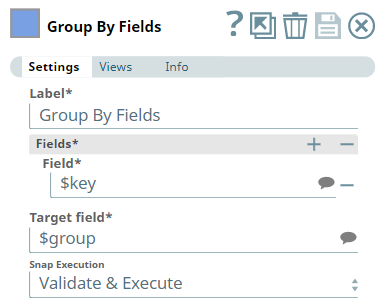
The Group By Fields Snap is set to group the incoming data by $key with the Target field as $group.
| Group By Fields Snap | Output (Raw JSON rendered into groups) |
|---|---|
| 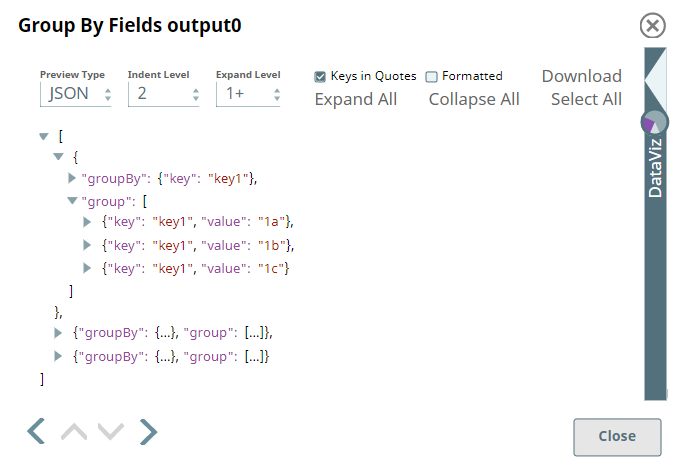 |
Notice that the incoming data is grouped by key in this output.
| JSON Formatter Snap |
|---|
|
| Output (one document per group and one line per group member) |
|
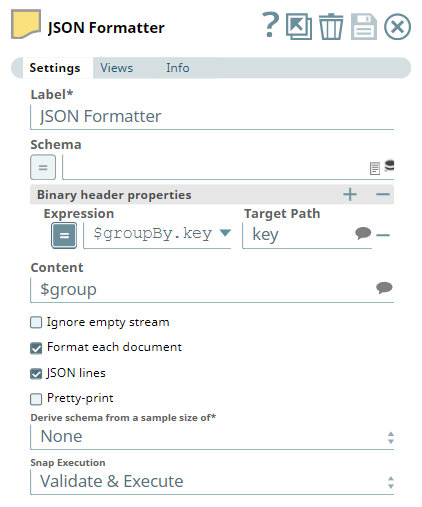
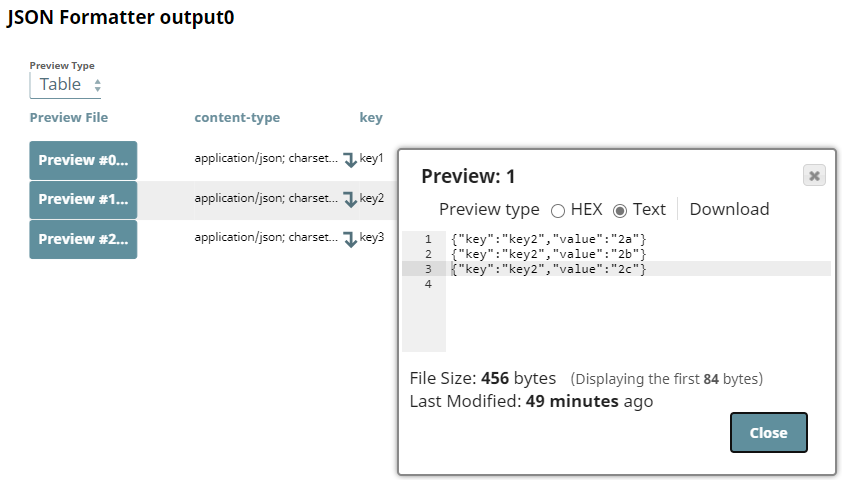
When the JSON Formatter Snap received data groups, we can
useselect the fields JSON lines and Format each document
incheck boxes in unison and
renderthe Snap formats the content
$group to achieve an output withas multiple documents
each corresponding to one group– one per group (key1, key 2 and key3 in this example)
andwith one line for each element in these groups
(Content array).
.
Filtering Output Data Using the JSON Formatter Snap's Content Setting
This example demonstrates how, effective 4.20 Patch transform8670 and onwards, you can use the JSON Formatter Snap to filter the input JSON data.
Download the Sample Pipeline.
- Using the sample Pipeline shown above, generate a JSON document using the JSON Generator Snap.

- In the Mapper Snap, map the input fields:
interface_id, failed_pipeline, target_url,andpayloadto the required output fields.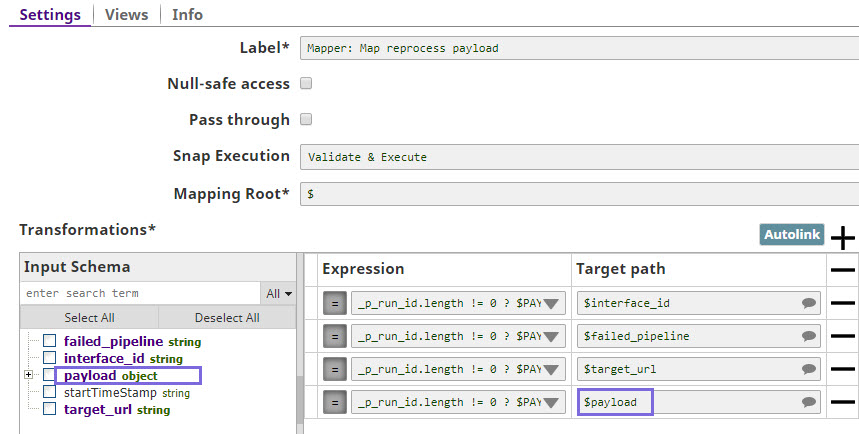
- In in the JSON Formatter Snap, in the Content field under Settings select
$payload as the object to be included in the output.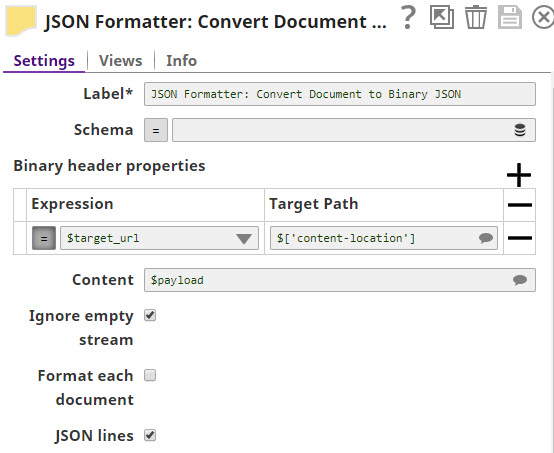
- Select the JSON lines check box to ensure each record appears as a separate line in the output file.
- Provide the name of the file to write to in the File Writer Snap and save it.
- Validate and execute the Pipeline.
| Current behavior | Old behavior |
|---|---|
With
| Prior to
|

Passing the
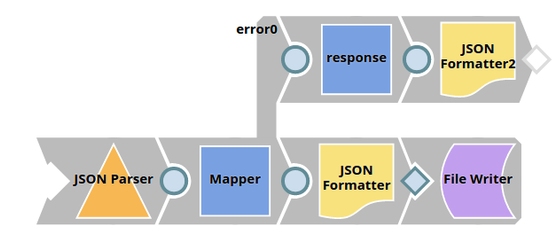
execution status code through Binary Header Properties of the JSON Formatter SnapPassing theExecution Status Code through Binary Header Properties of the JSON Formatter Snap
In this pipeline, the pipeline execution status is routed to the error view, which is redirected to reflect on the browser using the Binary Header Properties of the JSON Formatter Snap. This allows us to view the status on the browser same as on the output view of the triggered pipeline.
| Note |
|---|
This workaround of using the Binary Header properties is mainly useful when the user wants to view the exact execution status of the triggered task which may or may not be consistent with the status code otherwise reflected on the browser. |
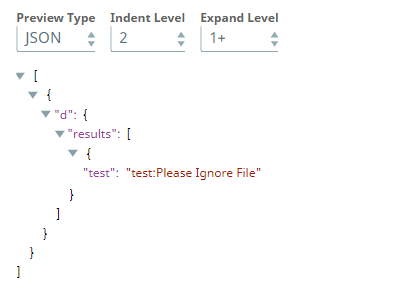
The JSON Formatter Snap passes the actual status code to the browser via the Binary Header Properties:
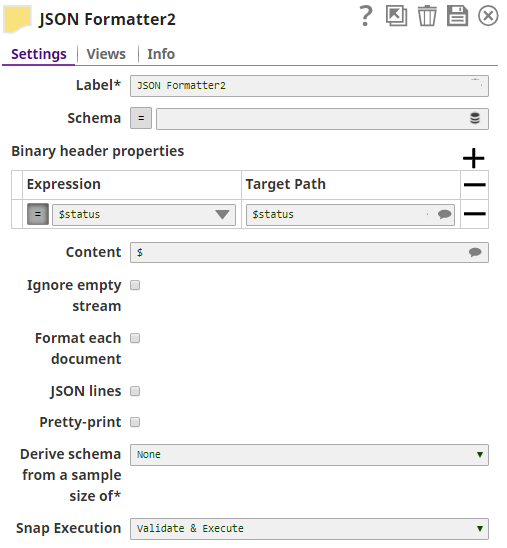
The status code (405) as retrieved from the pipeline is mapped to the response:
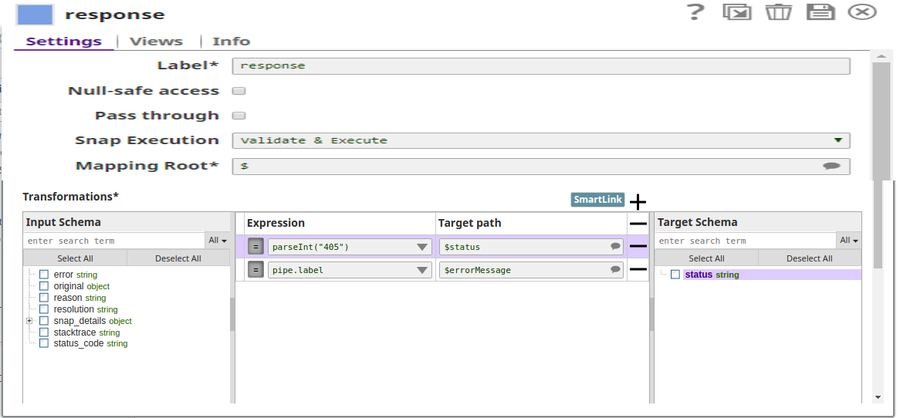
The JSON Formatter Snap passes the actual status code to the browser via the Binary Header Properties:
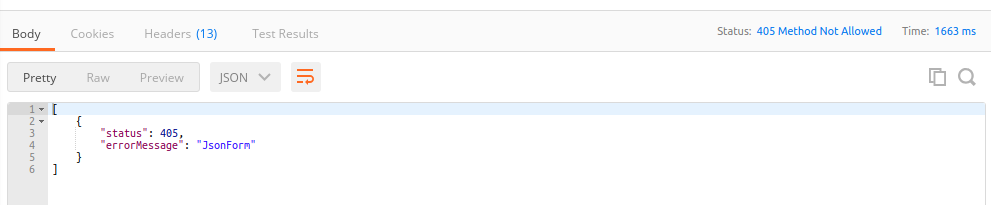
The status code (405) as reflected on the browser (Postman):
Creating
file with header value in a specific locationCreatinga File with Header Value in a Specific Location
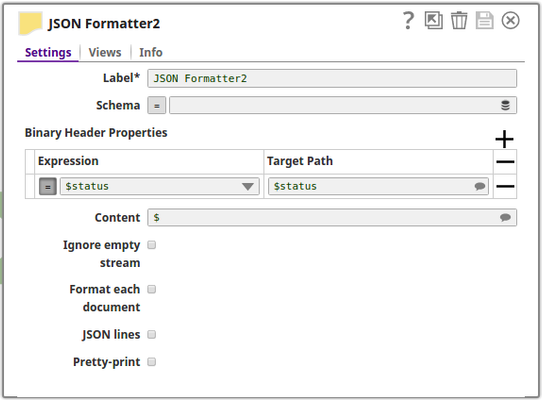
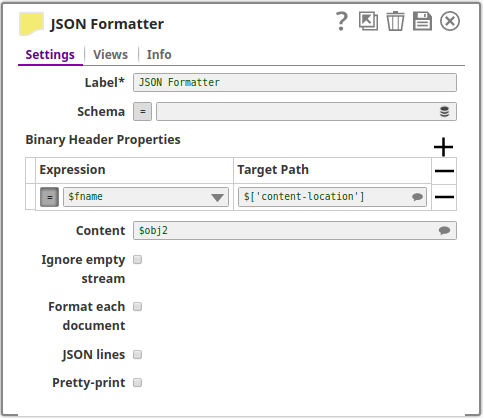
In this pipeline, the JSON Formatter Snap, creates a file with a header value on a specified location. The metadata is passed to the File Writer Snap using the Binary Header and the Content properties on the JSON Formatter Snap.

The JSON Generator Snap passes the values for the file and the records to be created.

The JSON Formatter Snap passes the metadata to the File Writer Snap.
The File Writer Snap creates the file "demo-" + $['content-location'] + ".json" on a specified content location.
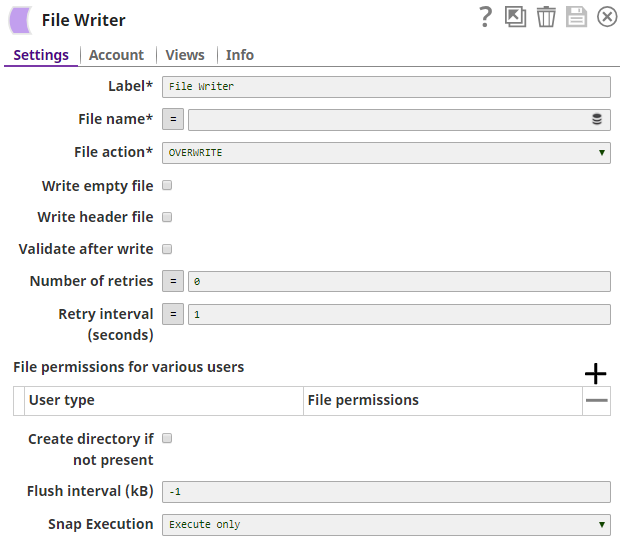
The successful execution of the pipeline displays the below output preview:
Note the file headers created on the sldb location, and the files names as demo-abc.json and so on.
Schema Suggest to Upstream Snap
In the example pipeline, Basic Use Case_JSON Formatter Schema Property, the Mapper Snap is used to write employee data into a file. The input data has to cater to a specified JSON schema, to enable this the Schema property is configured with a schema file. this allows the user to see the schema of the target file in the Mapper Snap.
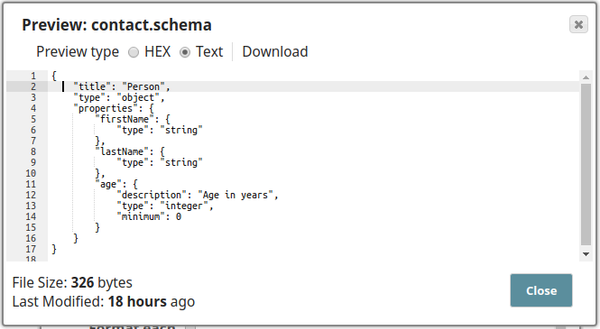
The JSON Formatter Snap is configured in the following manner, the schema file contact.schema is uploaded in the Schema property:
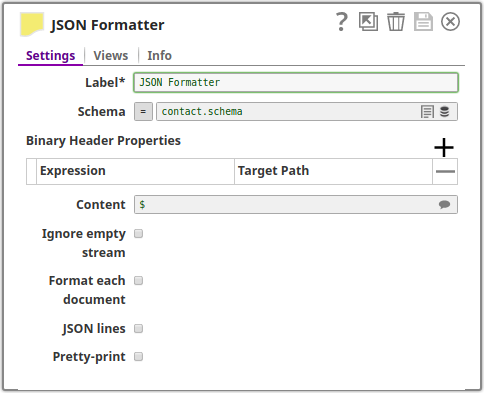
The schema defined in the contact.schema file is shown below:
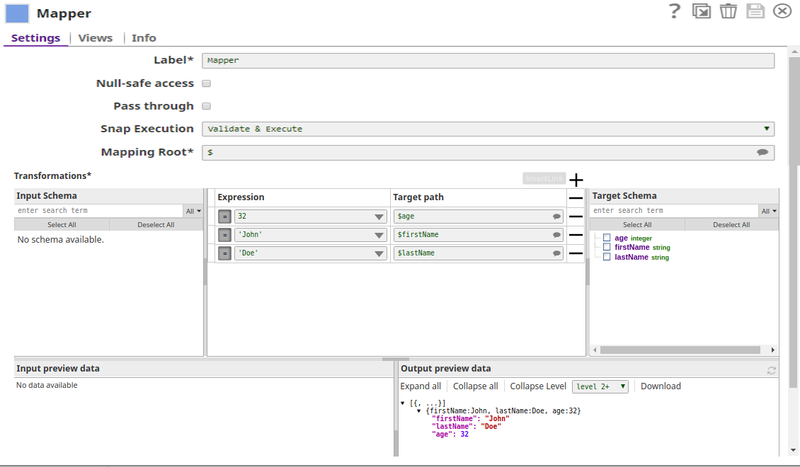
Below is the Mapper Snap's configuration, note the Target Schema and the Output preview data sections where the schema of the target file and the mapped data are shown:
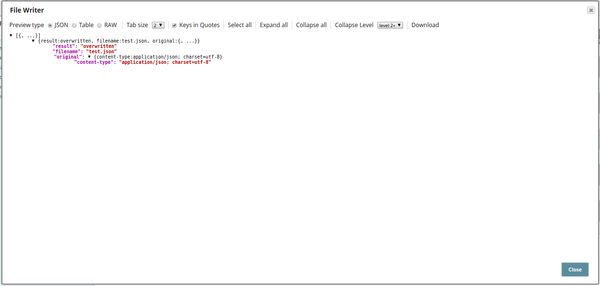
When executed the input record from the Mapper will be mapped to the specified path based on the target schema and written into the target file.
Exported pipeline is available in the Downloads section below.
Downloads
| Attachments | ||
|---|---|---|
|
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|