On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
Snap type: | Flow | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Description: | This Snap routes binary documents to different output views based on a boolean expression. A binary document consists of the binary content and a header that contains metadata for that content. For example, a file containing JSON data might have a header with a 'content-type' field set to 'application/json'. This Snap then allows you to separate a single stream of binary documents into multiple streams based on their header data. For example, when unzipping an archive with the ZipFile Read Snap, any files with a "content-type" of "application/json" could be sent to a JSON Parser and "text/xml" files could be sent to an XML Parser. The set of header fields available depends on the Snap that outputs the binary document. You can click on the preview icon for a binary view to see the content and headers that are being generated for each binary document. The following fields are often available:
| ||||||||||||||||||
| Prerequisites: | [None] | ||||||||||||||||||
| Support and limitations: | Ultra pipelines: Works in in Ultra Pipelines.Spark mode: Not supported in /wiki/spaces/SD/pages/1437917 modeTask Pipelines. | ||||||||||||||||||
| Account: | Accounts are not used with this Snap. | ||||||||||||||||||
| Views: |
| ||||||||||||||||||
Settings | |||||||||||||||||||
Label | Required. The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | ||||||||||||||||||
Routes | Required. Expression to evaluate and output views to write a binary document if the expression evaluates to true. The Expression should be applied to the fields available in binary document header. List of expressions can be seen here.
Default value: [None] | ||||||||||||||||||
First match | If true (selected), then the first output view whose corresponding expression evaluates to true will only have the binary document written to it even if there are other matches. If false (not selected), then all output views whose corresponding expression evaluates to true will have the binary document written to it. Expression | Output View Name | ||||||||||||||||||
|
| ||||||||||||||||||
Examples
Pipeline Demonstrating the Binary Router Snap
This pipeline demonstrates the Binary Router Snap.
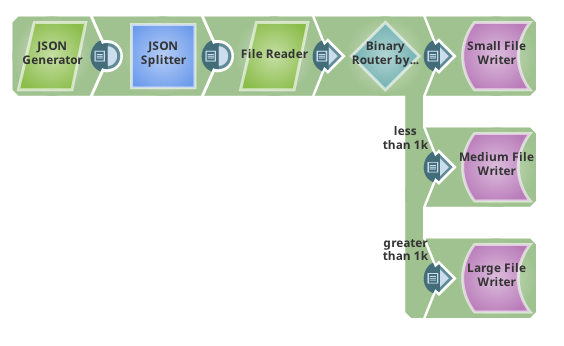
The first Snap reads a JSON document that contains three filenames. The JSON Splitter Snap turns it into three documents and the filename is passed as a parameter to the File Reader Snap. That Snap reads the first file, passes it to the Binary Router Snap where it is evaluated, a new file is written and then the next file is read and the process is repeated.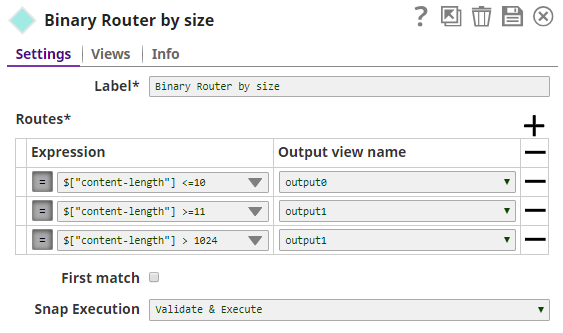
The evaluation in the Binary Router looks at the content-length and sends it to a different output view depending on size based on the following criteria:
$["content-length"] <= 10
$["content-length"] >= 11 && $["content-length"] <= 1023
$["content-length"] > 1024
Downloads
| Attachments | ||||||
|---|---|---|---|---|---|---|
|
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|