...
Field Name | Field Type | Description | |||
|---|---|---|---|---|---|
Label* Default Value: CSV Formatter | String | Specify a unique name for the Snap. | |||
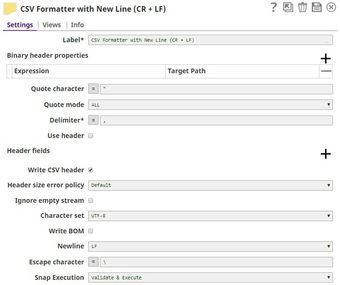
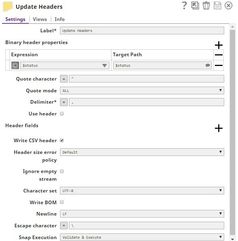
Binary header properties | Use this fieldset field set to add binary-header properties to the output data. These properties contain data related information that enables the system to interpret data. Binary headers in a document can be accessed and used in the expression-enabled properties of downstream Snaps. For example, you can use binary headers to specify custom statuses associated with the output data. Similarly, a 'content-location' property added to the binary header in this Snap can be referenced in the File name property of a File Writer Snap with the expression: $['content-location']. Expression-enabled fields in Binary header properties are evaluated against the first input document only. | ||||
Expression Default valueValue: N/A | String | Specify the value to be associated with a specific binary header property. | |||
Field 2Target Path Default Value: N/A | String | Specify the target JSON path where the value in the expression is written. | |||
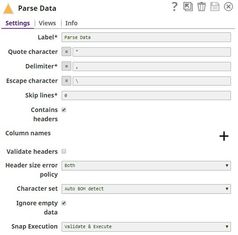
Quote character Default valueValue: “ | String | The character that you want to use as the escape character in the CSV document. For example, if you use double quotes (") as the escape character, then commas in the actual data will need to be escaped using double-quotes on both sides. This property can be an expression. However, if the value associated with the expression contains more than one character, only the first character is used as the quote character. | |||
Quote mode Default valueValue: ALL | Dropdown list | Select an option to specify how the quote character should be used in formatting the CSV data. Available options are:
If the Quote character property is empty, the selection of this property is ignored and the Snap uses NONE for the Quote mode. | |||
Delimiter Default valueValue:
| String/Expression | Specify the string or the character to be used as a delimiter in formatting the delimited data. Any combination of characters may be used, adhering to the following guidelines. The input must be submitted with any control characters escaped. For example,
| |||
Use header Default valueValue: Deselected | Checkbox | Select this checkbox to indicate whether the column names in the Header fields property should be used to format the CSV data. If this checkbox is deselected, the key set of the first document data is used as a CSV header.
| |||
Header fields | Default valueUse this field set to define the header values you want to use in the CSV output data. | ||||
Field names
| String | Specify the header values that you want to use in the output CSV datafield name for the header. | |||
Write CSV header Default valueValue: Selected | Checkbox | Select this checkbox to indicate whether the header strings listed in the Header fields properties should be written to the output CSV data. | |||
Header size error policy Default valueValue: Default | Dropdown list | Select an option to handle any header size errors.
The header size error condition occurs when any subsequent input document has additional column names which are not present in the header. To handle header size errors, you can select any of the following options:
| |||
Ignore empty stream Default valueValue: Deselected | Checkbox | Select this This checkbox to indicate determines whether you want the Snap to must or not ignore empty streams received at the input view during Pipeline pipeline execution. If this option is selected, the Snap does Select this checkbox to ignore empty input data and not produce any output stream; else, the Snap writes . Deselect this checkbox to write an empty array to the output stream. | |||
Character set Default valueValue: UFT-8 | Dropdown list | Select the character set in which the input CSV data is encoded. The available options are:
| |||
Write BOM Default valueValue: Deselected | Checkbox | Select this This checkbox to indicate determines the behavior of the Snap when it starts to write the CSV output data. If this option is selected, the Snap writes Select this checkbox to write the BOM (Byte Order Mark) for the character set selected in the Character-set encoding property; else, the Snap skips writing BOM. | |||
Newline Default valueValue: LF | Dropdown list | Select an option to specify the newline characters that you want to use as a line break. The available options are: LF, CR+LF and CR. | |||
Escape character Default valueValue: \ | String/Expression | Specify the escape character that is to be used when formatting rows. Only single characters are supported. As of 4.3.2, this property can be an expression You can also use the expression enabler to enter a value, which is evaluated with the values from the pipeline parameters. Leave this property field empty if no escape character is used in the input CSV data. | |||
Snap Execution Default Value: Validate & Execute | Dropdown list | Select one of the three modes in which the Snap executes. Available options are:
| |||
Examples
...
Specify Line Feeds for Windows while Formatting Documents
Text files created on Windows have different line endings than files created on Linux. Windows uses the carriage return and line feed ("\r\n") as a line ending, while Linux uses just a line feed ("\n").
In this example, we create a Pipeline that reads CSV data and then formats it for Windows-style line feeds using the CSV Formatter Snap.
...
Download this Pipelinepipeline.
| Expand | ||
|---|---|---|
| ||
Use the CSV Generator Snap to supply CSV documents:
 Notice how the double - quotes used in the first line of the input CSV data is escaped in the output document. The CSV Formatter Snap formats the input data and produces an output in the Windows-style line feeds for Windows style. We selected the Newline Property with CR+LF to give the line feeds in Windows format. We also leave the Quote character field unchanged as '"'. This tells the Snap that all special characters have to be placed in quotes in the CSV output.
 Use the File Writer Snap to create a file using the output. Successful execution of the Pipeline displays the following output: 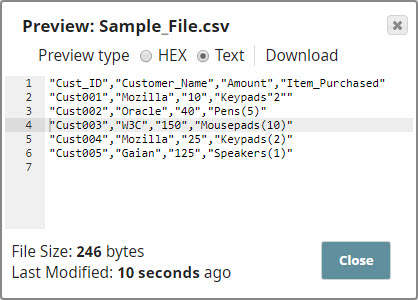 |
...
Create Filenames Using the CSV Formatter Snap
In this example, pick up CSV This example demonstrates how to use CSV Formatter Snap to (documents that contain details related to simple purchases purchase-related details and, depending on the value of the purchases, we ) to route them into two documents, picking up their names using the output of the CSV Formatter Snap.
...
Download this Pipelinepipeline.
| Expand | ||
|---|---|---|
| ||
For the purposes of this example, we are picking up CSV data from a CSV Generator Snap. You can also supply this data using a combination of File Reader and CSV Parser Snaps. The CSV Generator Snap contains transaction details, as shown below: 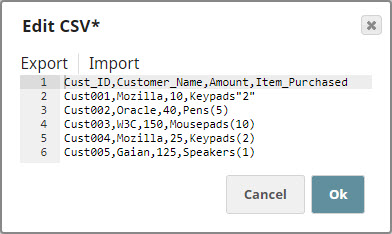 We copy the output of the CSV Generator Snap and connect each copy to a Filter Snap, where we filter out transactions based on whether they are worth more or less than $40: 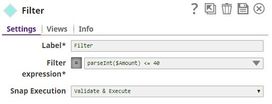 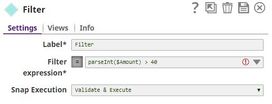 We now add a 'Bill_Type' binary header property to each set of filtered outputs, so each document is tagged appropriately: 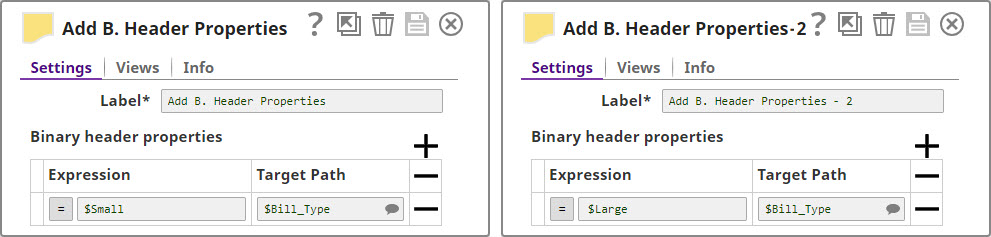
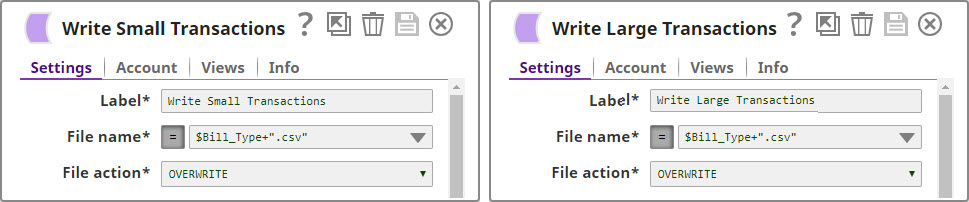 You can now see that two new files were created in the project: $Small.csv and $Large.csv: 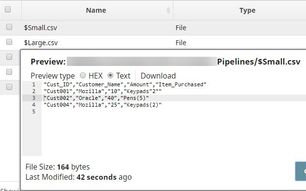 Download this Pipeline. |
...
Pass Execution Status Codes through Binary Header Properties of the CSV Formatter Snap
In this example, we shall send CSV data from ServiceNow into SnapLogic using a Triggered Task. We shall then see how you can use the CSV Formatter Snap in the triggered Pipeline pipeline to manipulate the execution status (error) codes generated during Pipeline pipeline execution.
...
Download this Pipeline.
| Expand | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||||||||
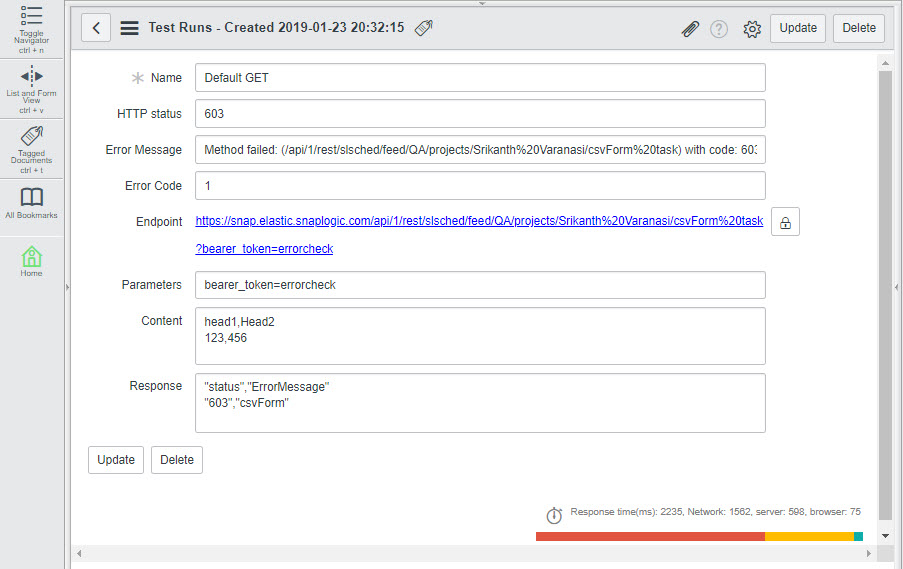
For the example to work, the Pipeline pipeline triggered by the Task should lead to an error. We shall route the error output to an error view. We shall then use the error view to manipulate the Status header of the error document. Once this is done, the parent Task sends the updated error output back to ServiceNow, and we should see the updated status code in the ServiceNow Administration interface. We need to perform the following tasks:
Let us look at each of these tasks in some detail: CreatingCreate aPipelinepipeline to accept CSV and manipulate error document dataThis Pipeline is structured as shown in the screenshot above. Let us now look at its constituents:
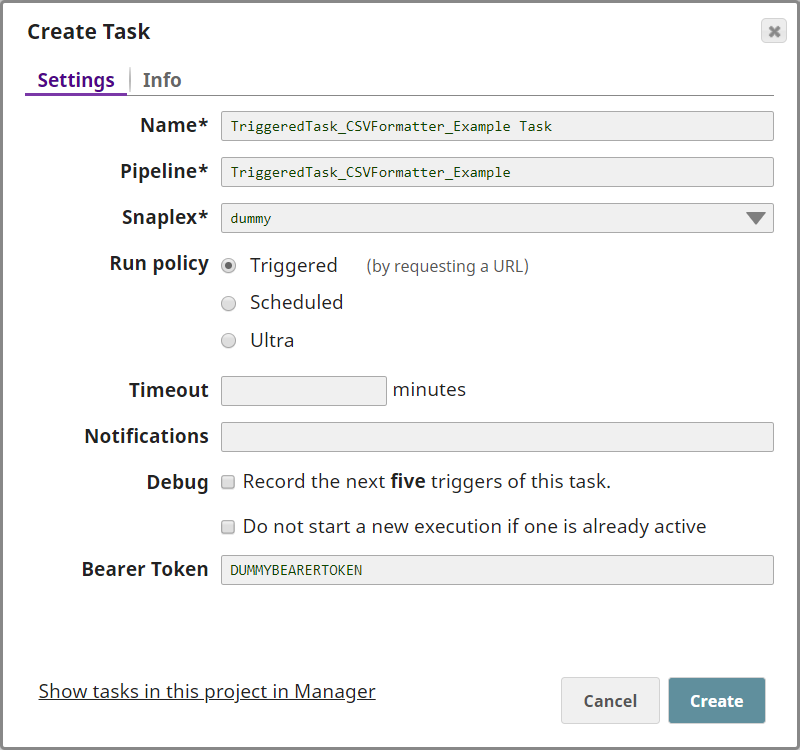
Create a Triggered Task that sends CSV data into the TriggeredTask_CSVFormatter_Example PipelineTo create a Triggered Task:
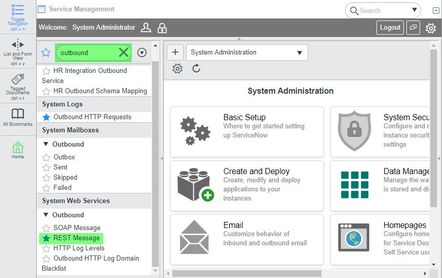
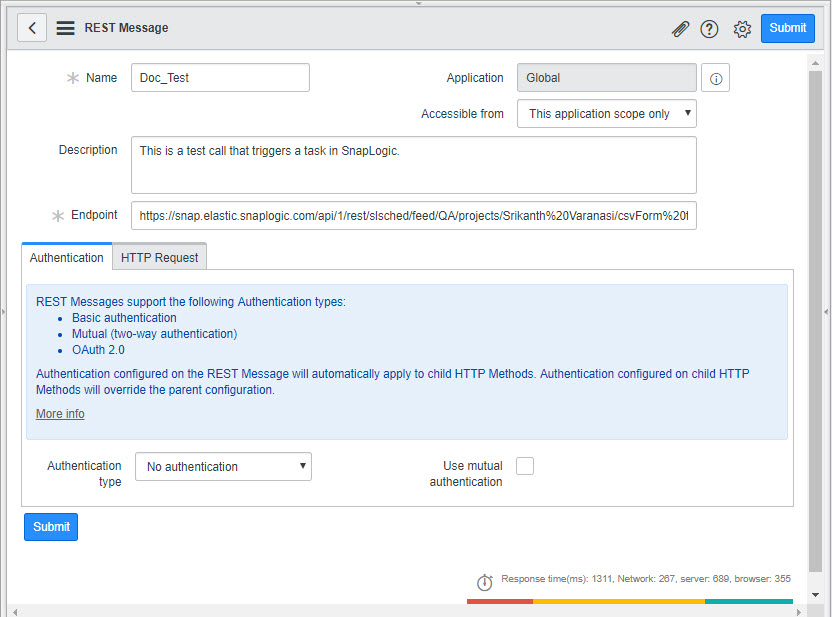
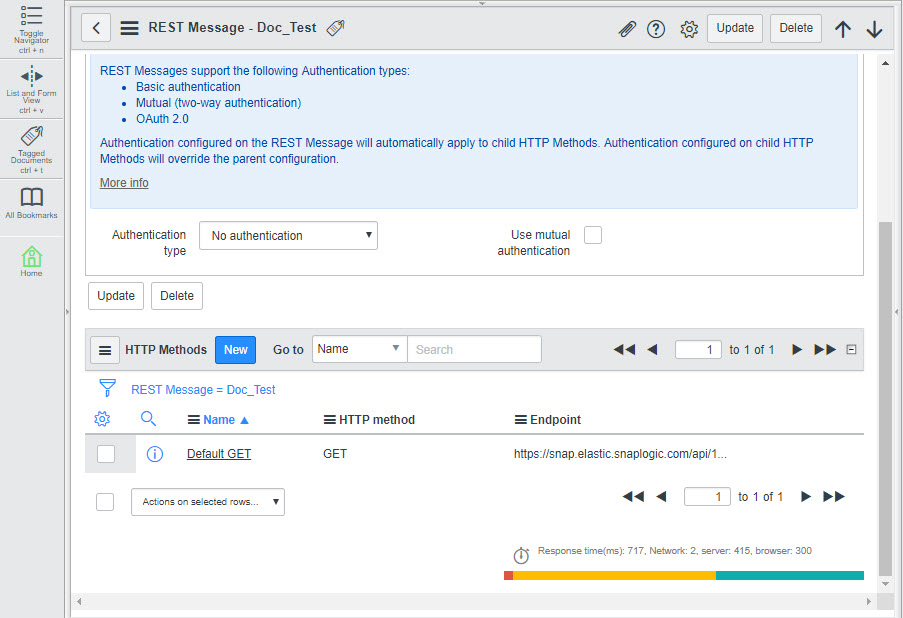
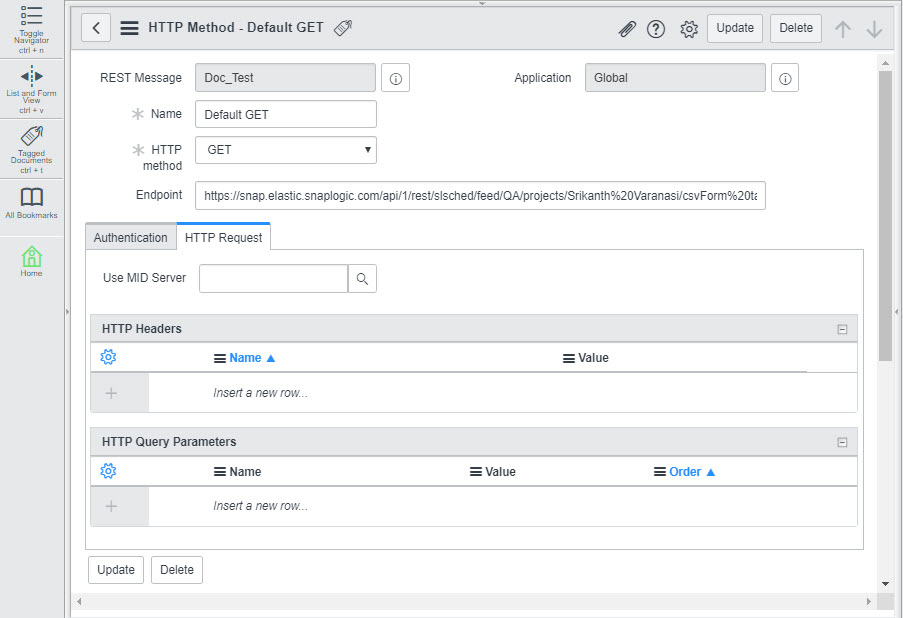
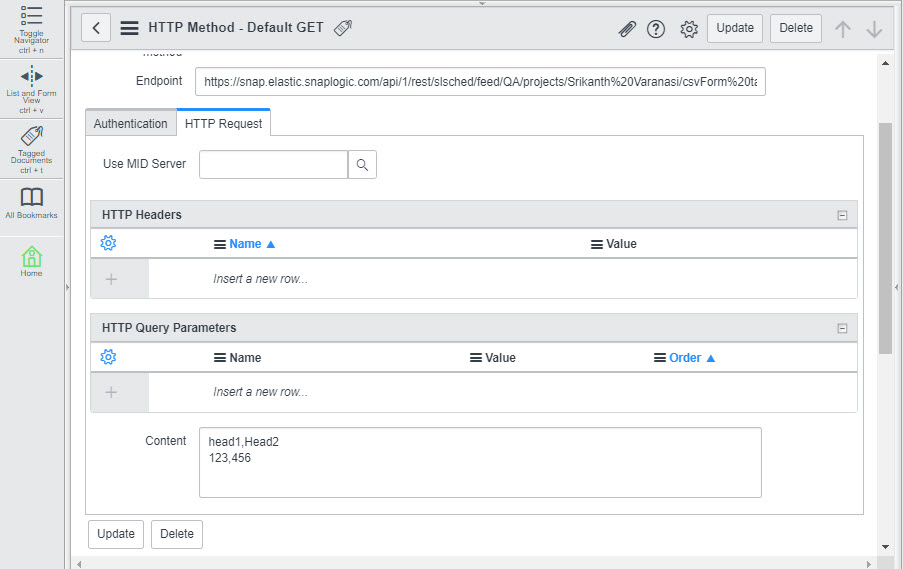
Configure ServiceNow to send and receive CSV data from the Triggered Task
To configure ServiceNow to send and receive CSV data from the Triggered Task created in Step 2:
You can similarly use the CSV Formatter Snap to update binary header values associated with any input document. |
...