On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
Snap type: | Write | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Description: | This Snap allows you to execute queries on BigQuery easily leveraging the jobs and query APIs. This Snap works only with single queries. A complete list of supported queries as well as examples are documented here: https://cloud.google.com/bigquery/query-reference.
| |||||||||||||
| Prerequisites: | [None] | |||||||||||||
| Support and limitations: | Works in Ultra Task Pipelines. | |||||||||||||
| Known Issues | Google BigQuery does not support very large exponential values—larger than EXP(700). So, while displaying values of such high exponential order in the validation preview, this Snap routes to the error view, and displays the following error: | |||||||||||||
| Account: | This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See Google BigQuery Account for information on the type of account to use. | |||||||||||||
| Views: |
| |||||||||||||
Settings | ||||||||||||||
Label |
| |||||||||||||
Project ID | Required. This drop-down shows you a list of all the available projects that your user Account has access to. Clicking on the the drop-down always pulls the latest list of available projects. The project on which the query should be executed should be selected. | |||||||||||||
| Location | Specify or select a region from the list of suggested locations on which you want to execute BigQuery. | |||||||||||||
Query | The query that you want to execute on BigQuery for the selected project. For a full list of supported functions and operators for your queries, see Legacy SQL Functions and Operators and Standard SQL Functions and Operators.
This setting also supports expressions that can be enabled to parameterize a specific section of the query like table names or columns to be selected. | |||||||||||||
| Standard SQL | Select this checkbox if you want to use the Standard SQL dialect in the Query field. It is crucial that you understand how the Snap interprets the dialect used in the Query field.
Default value: Not selected | |||||||||||||
| Destination dataset ID | Dataset ID of the dataset where the destination table has to be created in case of the query returning large query results. | |||||||||||||
| Destination table ID | Table ID of the destination table to write the query results to in case of the query returning large query results. | |||||||||||||
| Action on destination table | This option specifies the action that has to be taken if the destination table already exists. Options available include OVERWRITE, APPEND, and ERROR. Default value: OVERWRITE | |||||||||||||
|
| |||||||||||||
Interpreting the SQL Query Dialect
The Snap determines the SQL dialect used in the query based on the following flags:
- Dialect specified as prefix within the Query field (
#standardSQLor#legacySQL) - Default Standard SQL check box at account level
- Standard SQL check box at Snap level
The prefix specified in the query ignores the other two flags.
- When the prefix is not specified,
- The user must select either one of the check boxes at the account level and at the Snap level to specify that the query uses Standard SQL dialect.
- Else, the query is considered to be written in Legacy SQL.
- The user must select either one of the check boxes at the account level and at the Snap level to specify that the query uses Standard SQL dialect.
The following matrix depicts all the possible real-time scenarios for resolving the query dialect:
| Prefix in Query | Check box at account level | Check box at Snap level | Query Dialect |
|---|---|---|---|
| Not specified |
|
| Legacy SQL |
| Not specified | 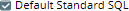 | 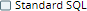 | Standard SQL |
| Not specified | 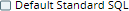 |
| Standard SQL |
| Not specified | | 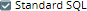 | Standard SQL |
#legacySQL | | | Legacy SQL |
#legacySQL | |
| Legacy SQL |
#legacySQL | | | Legacy SQL |
#legacySQL | | | Legacy SQL |
#standardSQL | | | Standard SQL |
#standardSQL | | | Standard SQL |
#standardSQL | | | Standard SQL |
#standardSQL | | | Standard SQL |
| Info | ||
|---|---|---|
| ||
|
Sample Queries
Here are some SQL statements in each of the two SQL dialects, that the BigQuery Execute Snap can execute:
| SQL Operation | Standard SQL | Legacy SQL | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Select |
|
| ||||||||||
| Create (DDL) table with nested array |
| Not allowed in Legacy SQL. | ||||||||||
| Insert (DML) |
| Not allowed in Legacy SQL. | ||||||||||
| Row count |
|
| ||||||||||
| Convert an Array into Table rows (Flattening) |
|
| ||||||||||
| DROP (DDL) |
| Not allowed in Legacy SQL. |
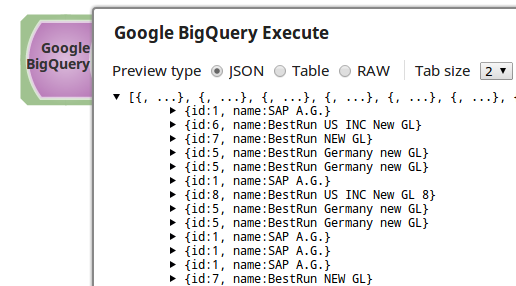
After the execution of query, the results are written to the output view. The sample output of Execute Snap looks as follows.
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|