...
Known Issues
None.
Snap Views
Type | Format | Number of Views | Examples of Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
Input | Document |
|
| A JSON document containing the key-value pairs indicating the columns and values for the new rows to insert in the DLP table.
|
Output | Document |
|
| A JSON document with the details of the new rows inserted in the DLP table. |
Error | Error handling is a generic way to handle errors without losing data or failing the Snap execution. You can handle the errors that the Snap might encounter while running the Pipeline by choosing one of the following options from the When errors occur list under the Views tab. The available options are:
Learn more about Error handling in Pipelines. | |||
Snap Settings
| Info |
|---|
|
Field Name | Field Type | Description |
|---|---|---|
Label* Default Value: Databricks - Insert | String | The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your Pipeline. |
Database name Default Value: None. | String/Expression/Suggestion | Enter your corresponding DLP database name for the INSERT statement to add new rows in the table. |
Table name* Default Value: None. | String/Expression/Suggestion | Enter your table name for the INSERT statement to add new rows. |
Number of Retries Example: 3 Minimum value: 0 Default value: 0 | Integer | Specifies the maximum number of retry attempts when the Snap fails to write. |
Retry Interval (seconds) Example: 3 Minimum value: 1 Default value: 1 | Integer | Specifies the minimum number of seconds the Snap must wait before each retry attempt. |
Manage Queued Queries Default value: Continue to execute queued queries when pipeline is stopped or if it fails. Example: Cancel queued queries when pipeline is stopped or if it fails | Dropdown list | Select this property to determine whether the Snap should continue or cancel the execution of the queued Databricks SQL queries when you stop the Pipeline. If you select Cancel queued queries when pipeline is stopped or if it fails, then the read queries under execution are cancelled, whereas the write type of queries under execution are not cancelled. Databricks internally determines which queries are safe to be cancelled and cancels those queries. Due to an issue with DLP, aborting an ELT Pipeline validation (with preview data enabled) causes only those SQL statements that retrieve data using bind parameters to get aborted while all other static statements (that use values instead of bind parameters) persist.
To avoid this issue, ensure that you always configure your Snap settings to use bind parameters inside its SQL queries. |
Snap Execution Default Value: Execute only | Dropdown list | Select one of the three modes in which the Snap executes. Available options are:
|
Troubleshooting
Error | Reason | Resolution |
|---|---|---|
Missing property value | You have not specified a value for the required field where this message appears. | Ensure that you specify valid values for all required fields. |
Examples
Inserting data from a Snowflake table into a DLP table
...
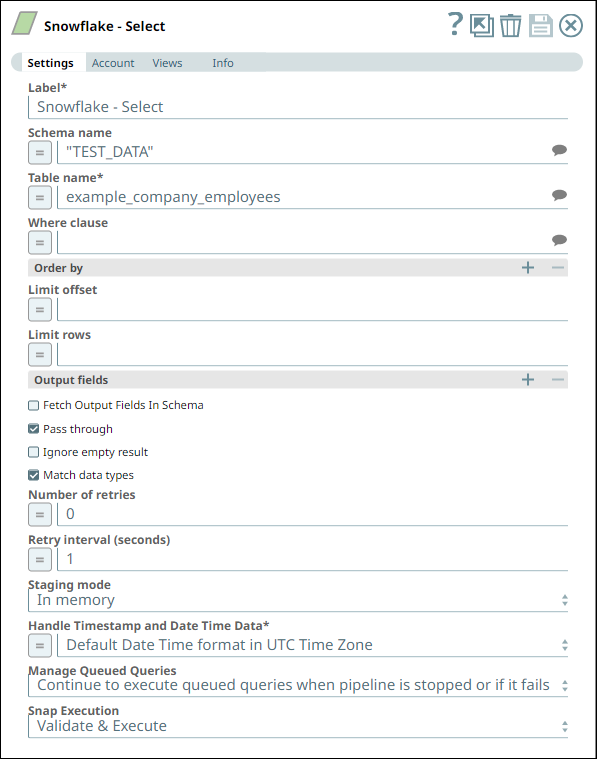
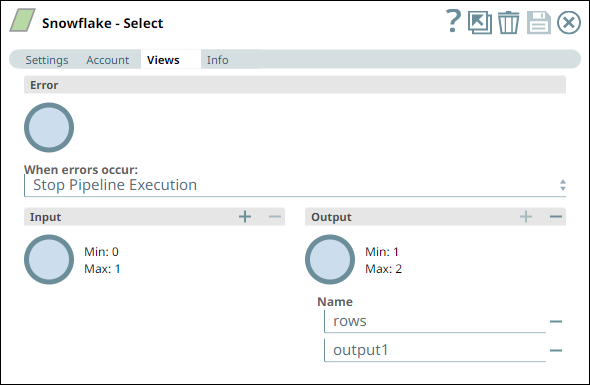
In this Pipeline, we configure the Snowflake - Select Snap from the Snowflake Snap Pack with the appropriate account, zero input views, and open two output views—one for capturing the rows data and the other for capturing the table schema (as metadata). See the sample configuration of the Snap and its account below:
Snowflake - Select Snap Settings | Snowflake - Select Snap Views |
|---|---|
 |  |
Account Settings for Snowflake - Select Snap | Notes |
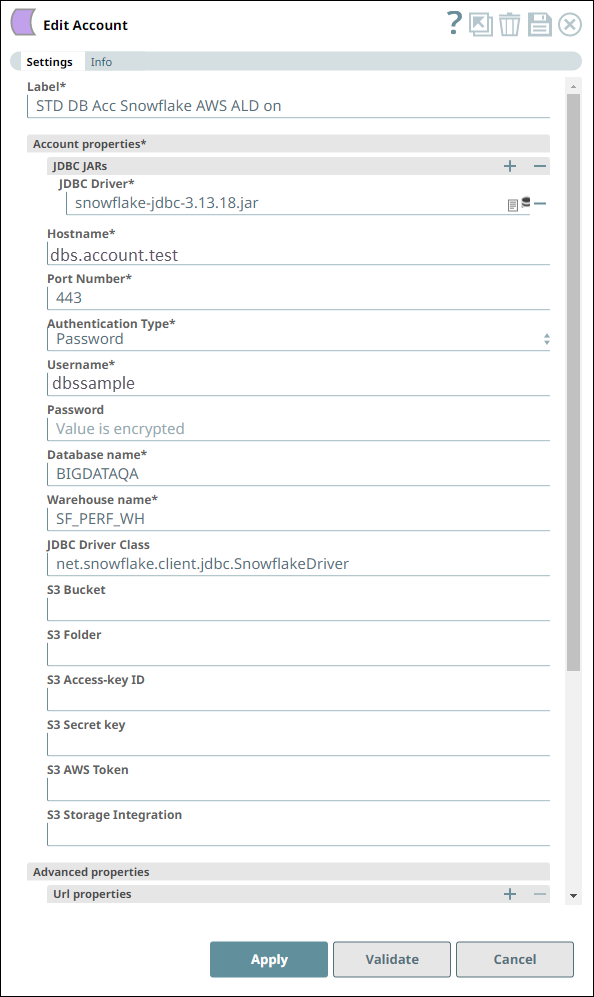
 | We configure the Snap to fetch the table schema (output1) and the table data (rows) from the example_company_employees2 table in the Snowflake instance. The Snap uses a Snowflake JDBC driver and the corresponding basic auth credentials to connect to the Snowflake instance hosted on the AWS cloud. |
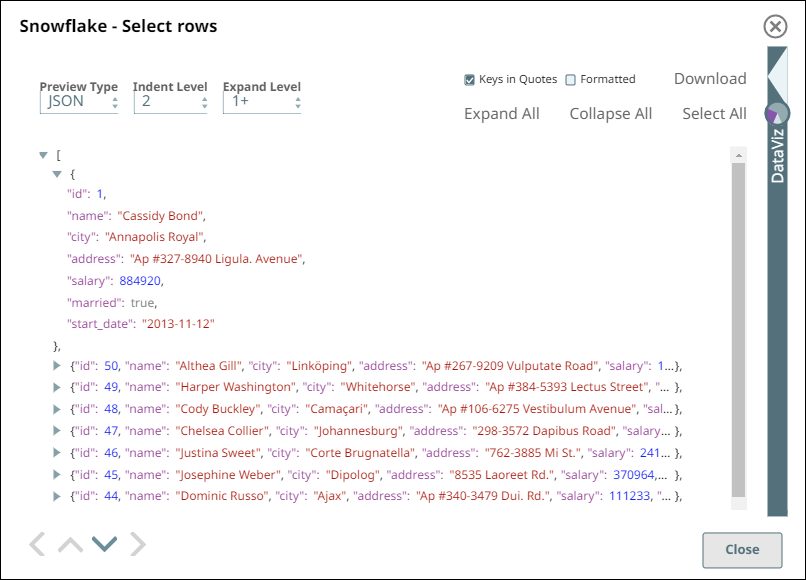
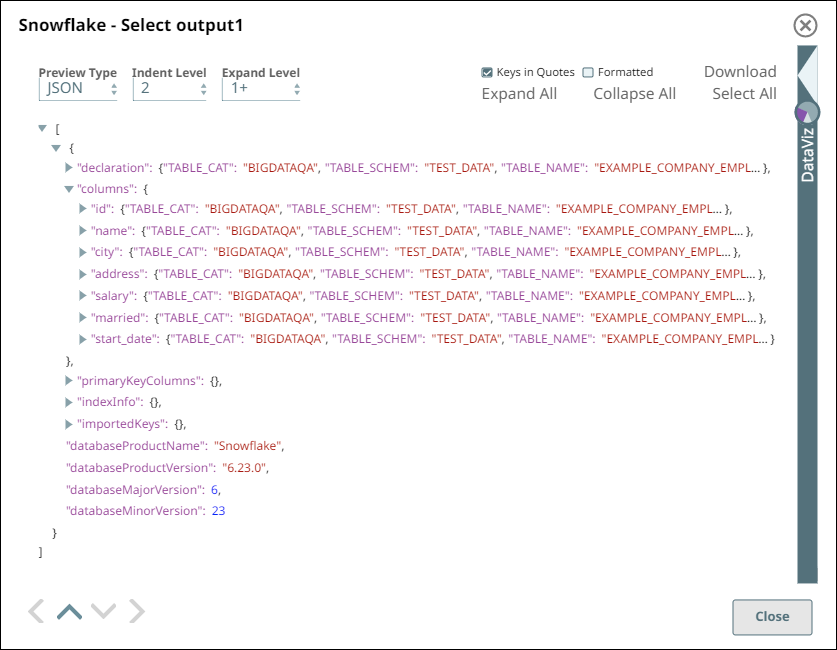
Upon validation, the Snap displays the table schema and a sample set of records from the specified table in its two output views. During runtime, the Snap retrieves all data from the example_company_employees2 table that match the Snap’s configuration (WHERE conditions, LIMIT, and so on).
Snowflake - Select Snap Output View for Table data | Snowflake - Select Snap Output View for Table Schema |
|---|---|
 |  |
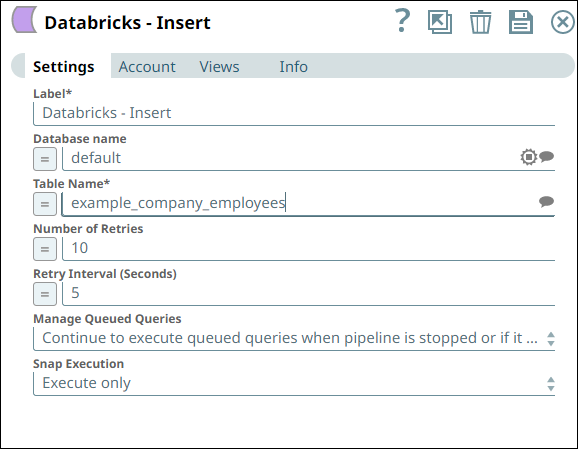
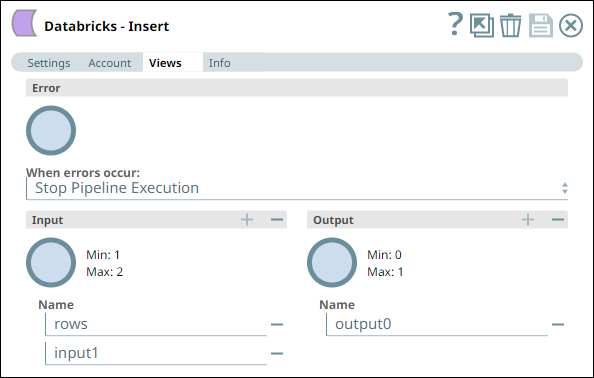
Similarly, we use a Databricks - Insert Snap with the appropriate account and two input views to consume the two outputs coming from the Databricks - Select Snap. See the sample configuration of the Snap and its account.
Databricks - Insert Snap Settings | Databricks - Insert Snap Views |
|---|---|
 |  |
Account Settings for Databricks - Insert Snap | Notes |
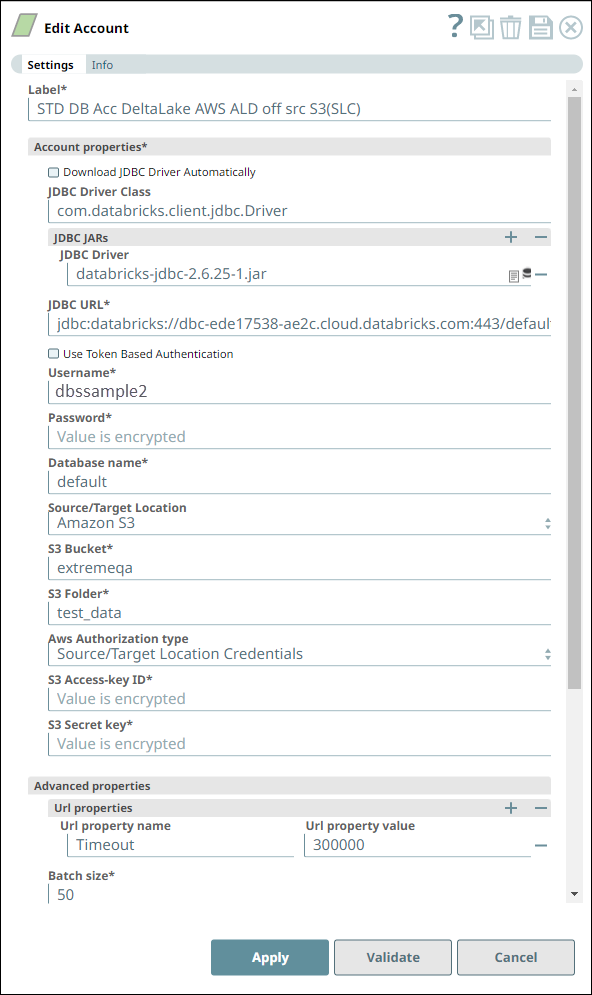
 | We configure the Snap to consume the table schema (output1) and the table data (rows) from the example_company_employees table in the Snowflake instance. The Snap uses a Databricks JDBC driver and the corresponding basic auth credentials to connect to the DLP (target) instance hosted on the AWS cloud. The Snap is configured to perform the Insert operation only during Pipeline execution and hence, it does not display any results during validation. Upon Pipeline Execution, the Snap creates a new table example_company_employees2 in the specified DLP database using the schema from the Snowflake - Select Snap and populates the retrieved rows data in this new table. |
Downloads
| Info |
|---|
|
| Attachments | ||||
|---|---|---|---|---|
|
...