...
Type | Format | Number of Views | Examples of Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
Input |
|
| Binary-to-Document | This Snap can have at most one document or binary input view. If you do not specify an input view, the Snap generates a downstream flow of one row. By default, this Snap has Document as the Input type is Document. You can select Binary type if your input is in Binary format. |
Output |
|
| Any Document Snap | This Snap has exactly one document or binary output view. By default, the Output type is Document. You can select the Binary type to view the output in the Binary format. |
Error | Error handling is a generic way to handle errors without losing data loss or failing the Snap execution failure. You can handle the errors that the Snap might encounter when running the pipeline with one of the following options from the When errors occur list under the Views tab. The available options are:
Learn more about Error handling in Pipelines. | |||
...
| Info |
|---|
|
Field Name | Field Type | Description | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
Label* Default Value: Mapper | String | The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | ||||||||
Null-safe access Default Value: Deselected | Checkbox | Select this checkbox to set the target value to null if the source path does not exist. For example, | ||||||||
Pass through Default Value:Deselected | Checkbox | Select this checkbox so the Snap passes all the original input data into the output document with the data transformation results. If you deselect this checkbox, only the data transformation results in the mapping section appear in the output document and the input data is discarded.
| ||||||||
Transformations* | Use this field set to configure the settings for data transformations. | |||||||||
Mapping Root Default Value: $ | String/Suggestion | Specify the subsection of the input data to map. Learn more: Understand the Mapping Root. | ||||||||
Input Schema | Dropdown list | Select the input data (from the upstream Snap) that you want to transform. Drag the item you want to map and place it under the Mapping table. | ||||||||
Sorted Default Value: Selected | Checkbox | Select this checkbox to sort the input schema and the target schema. The sort options are:
| ||||||||
Mapping table* | Use this field set to specify the source path, expression, and target path columns used to map schema structure. The mapping table makes it easier to:
Learn more about Use the Mapping Table. | |||||||||
Expression* Default Value: N/A | String/Expression | Specify the function to use to transform the data. For example, combine, concatenate, or flatten. Expressions that are evaluated replace the source targets at the end of the pipeline runtime.
Learn More: Understand Expressions in SnapLogic and Use Expressions for usage guidelines.
| ||||||||
Target path Default Value: N/A | String/Suggestion | Specify the target JSON path where the value from the evaluated expression is written. For example, after evaluation of the Target Path Recommendation
For example, you have the Expression $Emp.Emp_Personal.FirstName in one of your pipelines. You set the Target path for this expression as $FirstName. Now, if you use the expression $Emp.Emp_Personal.FirstName in a new pipeline, then Iris recommends $FirstName as one of the Target paths to help you standardize the naming standards in your org. The following shows how Iris recommends the Target path in a Mapper Snap: 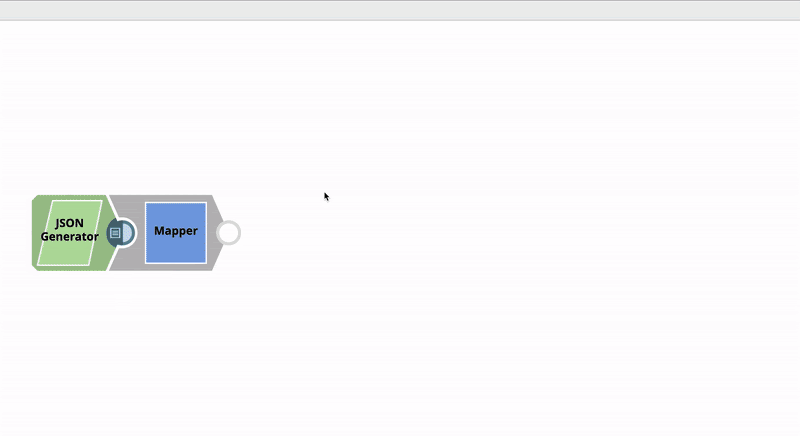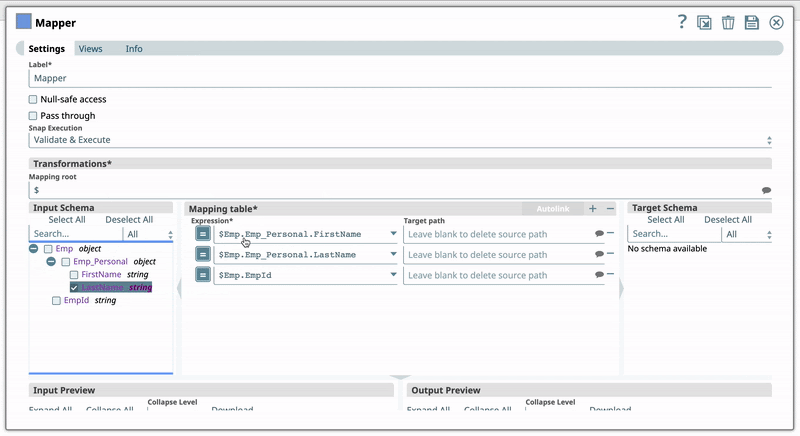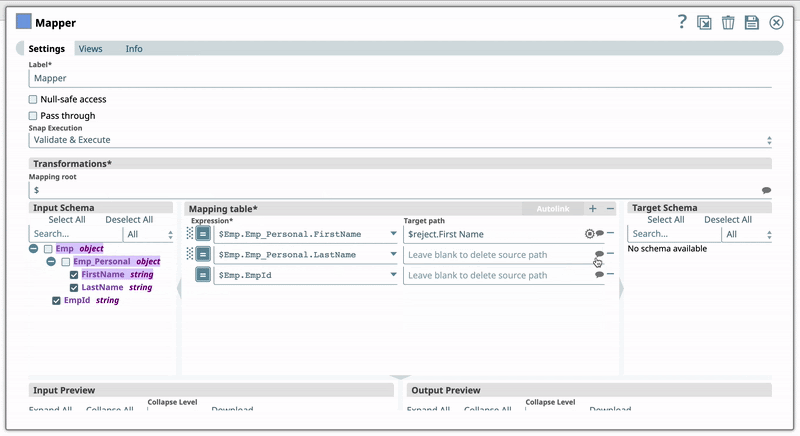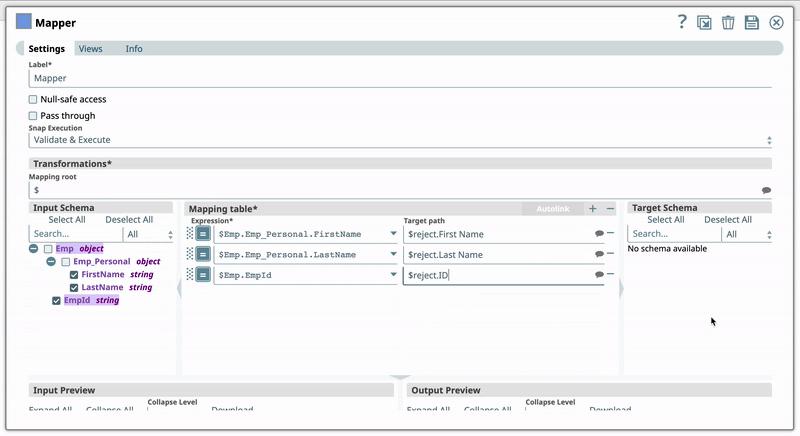 | ||||||||
Snap Execution | Dropdown list | Select one of the three modes in which the Snap executes. Available options are:
| ||||||||
...
Successful Mapping | ||||||
|---|---|---|---|---|---|---|
If your source data looks like | And your mapping looks like | Your output data will look like | ||||
|
|
| ||||
Unsuccessful Mapping | ||||||
|
| An error is displayed. | ||||
Mapper Examples
...
| Attachments | ||
|---|---|---|
|
...
Related Content
...