On this Page
...
NLP is very useful and is now available in our daily life. Chatbots accurately provide solutions to people 24/7. Virtual Assistants (Alexa, Google Assistant, Siri, Cortana, etc.) understand our voices and help us in a lot of things. Machine translator can translate most of the major languages on the fly. Text summarization, content categorization, sentiment analysis, text-to-speech conversion, speech-to-text conversion, and others are bringing communication between humans and machines to the next level.
The live demo is available at our Machine Learning Showcase.
Description
There are a lot of open source projects for NLP such as Stanford's Core NLP Suite, Natural Language Toolkit, Apache OpenNLP, etc. Each of them has strengths and weaknesses. In this use case, we will use a python library called TextBlob which is very simple, easy to use and yet powerful. We will use TextBlob and build NLP API with 4 operations using Remote Python Script Snap and SnapLogic Ultra Task. Those 4 operations include noun phrase extraction, part-of-speech tagging, sentiment analysis, and tokenization.
Objectives
- Model Testing: Use Remote Python Script Snap from ML Core Snap Pack to deploy python script to use pre-built NLP model using TextBlob library. Then, test the operations using samples.
- Model Hosting: Use Remote Python Script Snap from ML Core Snap Pack to deploy python script to host the model and schedule an Ultra Task to provide API.
- API Testing: Use REST Post Snap to send sample requests to the Ultra Task to make sure the API is working as expected.
...
The JSON Generator is used to generate a text sample for each of the NLP operations: noun phrase extraction, part-of-speech tagging, sentiment analysis, and tokenization. Those samples are then fed into the Remote Python Script Snap which outputs the results.
...
We use SLTool.ensure to automatically install required libraries. SLTool class contains useful methods: ensure, execute, encode, decode, etc. In this case, we need nltk and textblob.
| Paste code macro | ||
|---|---|---|
| ||
from snaplogic.tool import SLTool as slt
slt.ensure("nltk", "3.3")
slt.ensure("textblob", "0.15.1")
# Download NLTK corpora.
import textblob.download_corpora
textblob.download_corpora.main() |
...
| Paste code macro | ||
|---|---|---|
| ||
# Imports
from textblob import TextBlob
# This function will be executed once before consuming the data.
def snaplogic_init():
return None
# This function will be executed on each document from the upstream snap.
def snaplogic_process(row):
try:
operation = row["operation"]
text = row["text"]
text_obj = TextBlob(text)
result = None
if operation == "part_of_speech_tagging":
result = {"tag": text_obj.tags}
elif operation == "noun_phrase_extraction":
result = {"noun": text_obj.noun_phrases}
elif operation == "sentiment_analysis":
result = {"polarity": text_obj.sentiment.polarity, "subjectivity": text_obj.sentiment.subjectivity}
elif operation == "tokenization":
result = {"word": text_obj.words, "sentence": [str(x) for x in text_obj.sentences]}
else:
result = {"error": "Operation " + str(operation) + " is not valid."}
return {"result": result}
except:
return {"result": {"error": "The request is not valid."}}
# This function will be executed after consuming all documents from the upstream snap.
def snaplogic_final():
return None |
Model Hosting
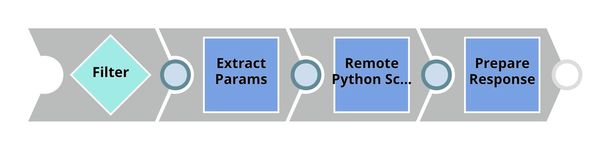
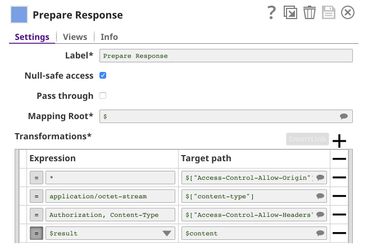
This pipeline is scheduled as an Ultra Task to provide a REST API that is accessible by external applications. The core component of this pipeline is the Remote Python Script Snap that is the same as in the Model Testing pipeline. Instead of taking the data from the JSON Generator, the Remote Python Script Snap takes the data from API request. The Filter Snap is used to authenticate the request by checking the token that can be changed in pipeline parameters. The Extract Params Snap (Mapper) extracts the required fields from the request. The Prepare Response Snap (Mapper) maps from result to $content which will be the response body. This Snap also adds headers to allow Cross-Origin Resource Sharing (CORS).

Building API
To deploy this pipeline as a REST API, click the calendar icon in the toolbar. Either Triggered Task or Ultra Task can be used.
Triggered Task is good for batch processing since it starts a new pipeline instance for each request. Ultra Task is good to provide REST API to external applications that require low latency. In this case, the Ultra Task is preferable. Bearer token is not needed here since the Filter Snap will perform authentication inside the pipeline.
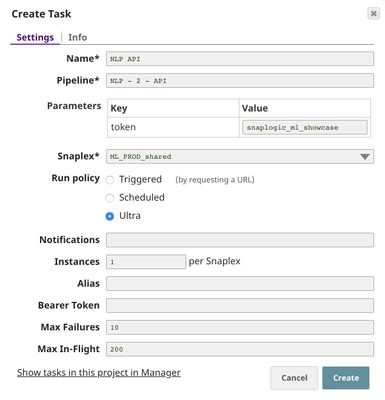
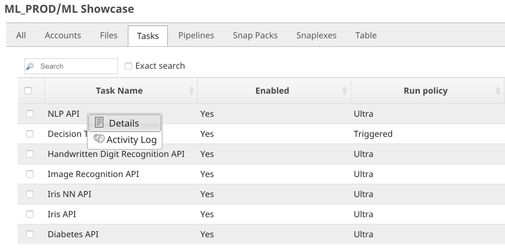
In order to get the URL, click Show tasks in this project in Manager in the Create Task window. Click the small triangle next to the task then Details. The task detail will show up with the URL.
API Testing
In this pipeline, sample requests are generated by JSON Generator. The requests are sent to the Ultra Task by REST Post Snap. The Mapper Snap is used to extract responses which are in $response.entity.
Below is the content of the JSON Generator Snap. It contains $token and $params which will be included in the request body sent by REST Post Snap.

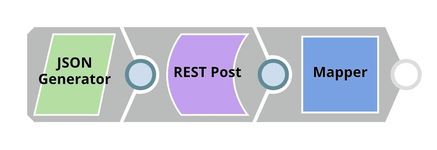
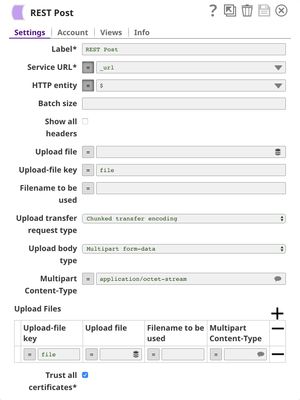
The REST Post Snap gets the URL from the pipeline parameters. Your URL can be found in the Manager page. In some cases, it is required to check Trust all certificates in the REST Post Snap.

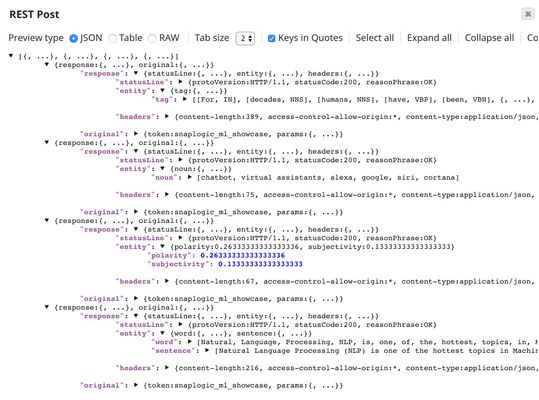
The output of the REST Post Snap is shown below. The last Mapper Snap is used to extract $response.entity from the request.
Downloads
| Multiexcerpt include macro | ||||
|---|---|---|---|---|
|
| Attachments | ||
|---|---|---|
|
...