Overview
You must create Databricks accounts to connect to Databricks Snaps in your Pipelines with the source or target CDWs (databases). This account enables you to write-and-transform data in the target databases hosted in the cloud locations listed in the following table. The JDBC URL you configure for your target database indicates the respective cloud location where the database is hosted. You can configure your Databricks accounts in SnapLogic using either the Designer or the Manager.
Target Database | Supported Cloud Location | Cloud Location in JDBC URL |
|---|---|---|
Databricks Lakehouse Platform (DLP) | jdbc:spark://<your_instance_code>.cloud.databricks.com or jdbc:databricks://<your_instance_code>.cloud.databricks.com | |
jdbc:spark://<your_instance_code>.azuredatabricks.net or jdbc:databricks://<your_instance_code>.azuredatabricks.net |
Supported JDBC JAR Version
You can configure your Databricks Account to automatically use the recommended JDBC JAR file - databricks-jdbc-2.6.25-1.jar for connecting to your target DLP instance and performing the load and transform operations.
Using Alternate JDBC JAR File Versions
We recommend that you let the Snaps use the listed JAR file versions. However, you may choose a different JAR file version.
Snap-Account Compatibility
Snaps in the Databricks Snap Pack work with the different accounts and protocols in the following table:
Snap | Databricks Account (Source-wise)# | |||||
|---|---|---|---|---|---|---|
ADLS Gen2 | ADLS Blob Storage | AWS S3 | GCS | JDBC (Any database) | Databricks File System (DBFS) | |
✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
✔ | ✔ | ✔ | ✔ | ✖ | ✖ | |
# Source type is required in
Configuring Databricks Accounts Using SnapLogic Designer
Open the SnapLogic Designer and drag a Databricks Snap to the Canvas and click the Snap to open its settings. Click the Account tab. You can now either use an existing account or create a new one.
Selecting an existing account
SnapLogic organizes and displays all accounts to which you have access, sorting them by account type and location. To select an existing account:
In the Account tab, click the List
 icon to view the accounts to which you have access, and select the account that you want to use.
icon to view the accounts to which you have access, and select the account that you want to use. Click the Save
icon.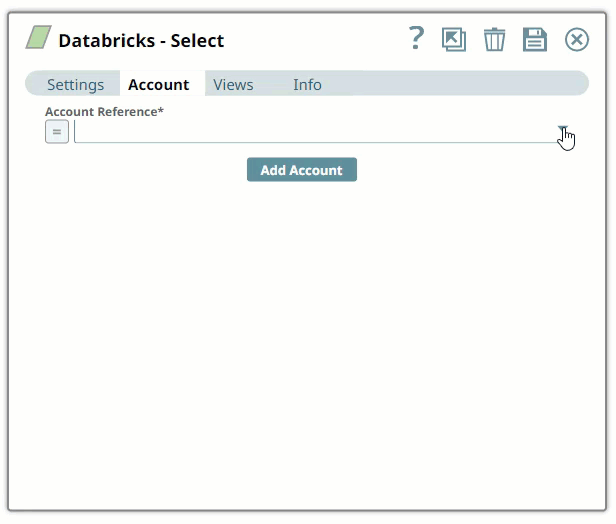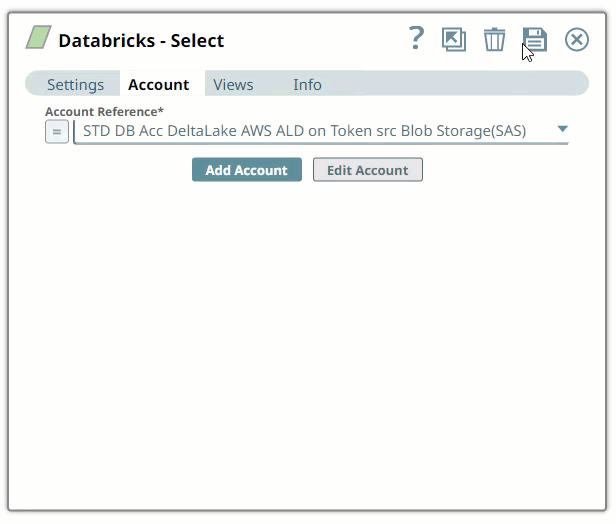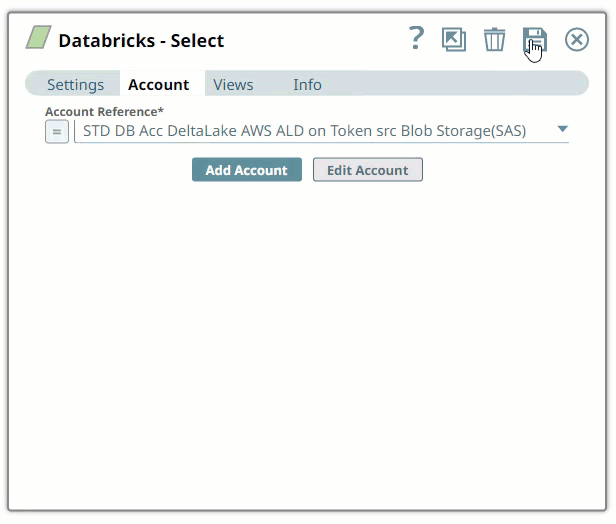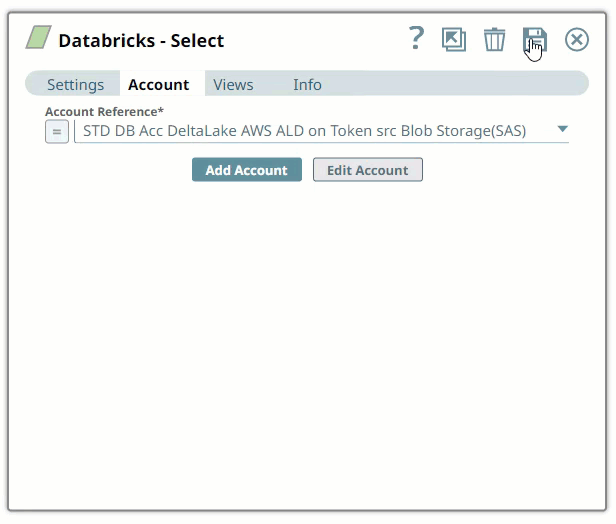
Creating an account
In the Account tab, click Add Account below the Account Reference field.
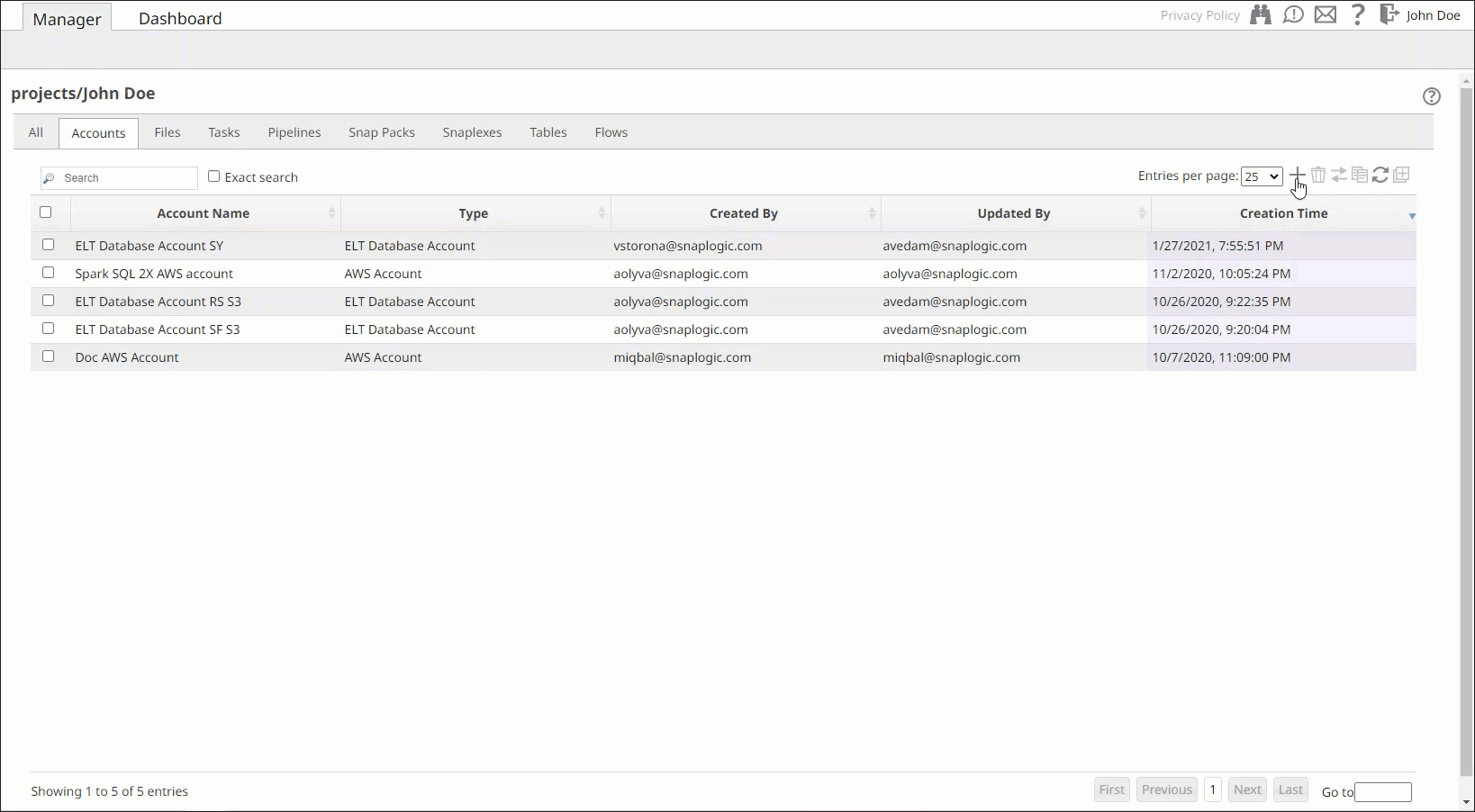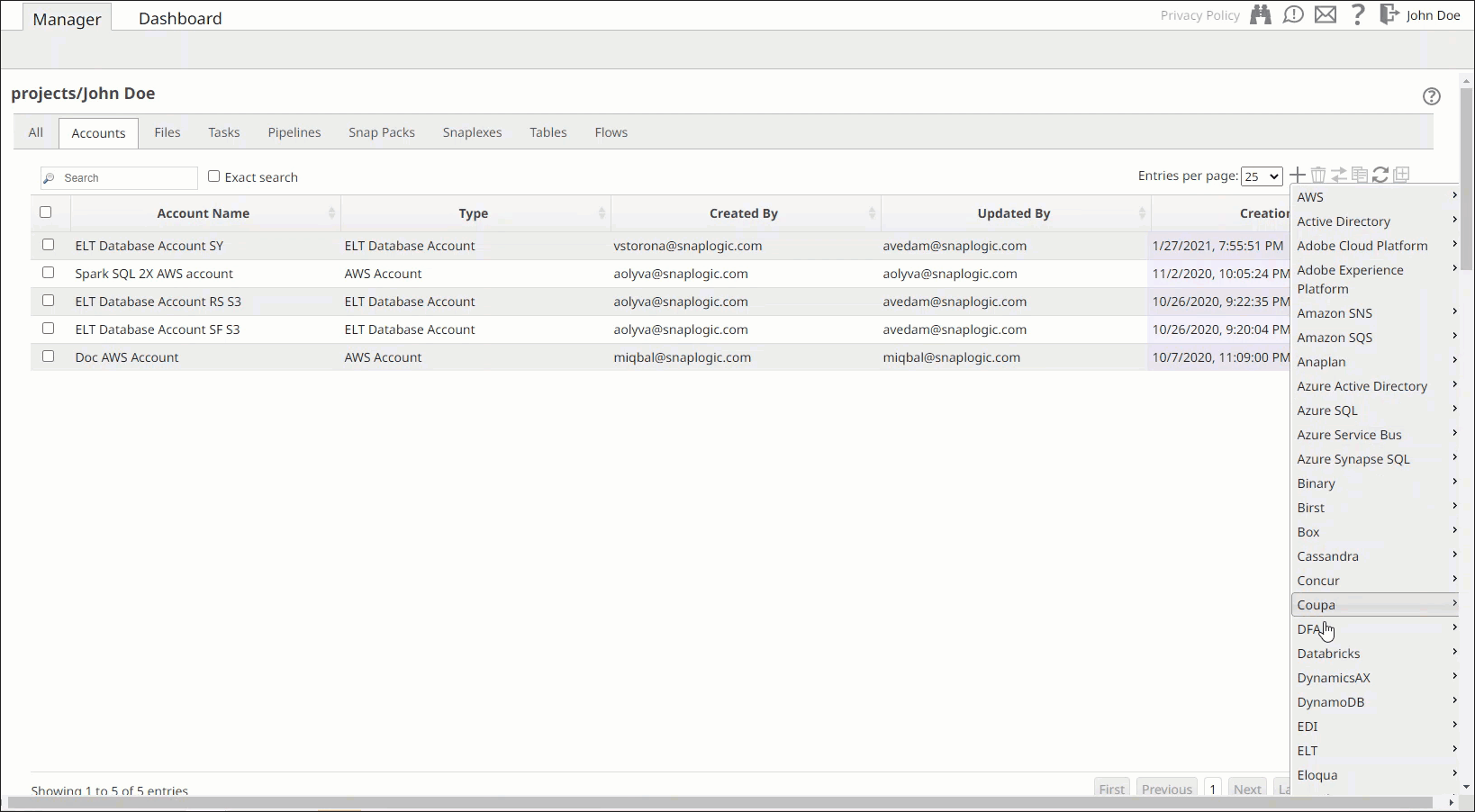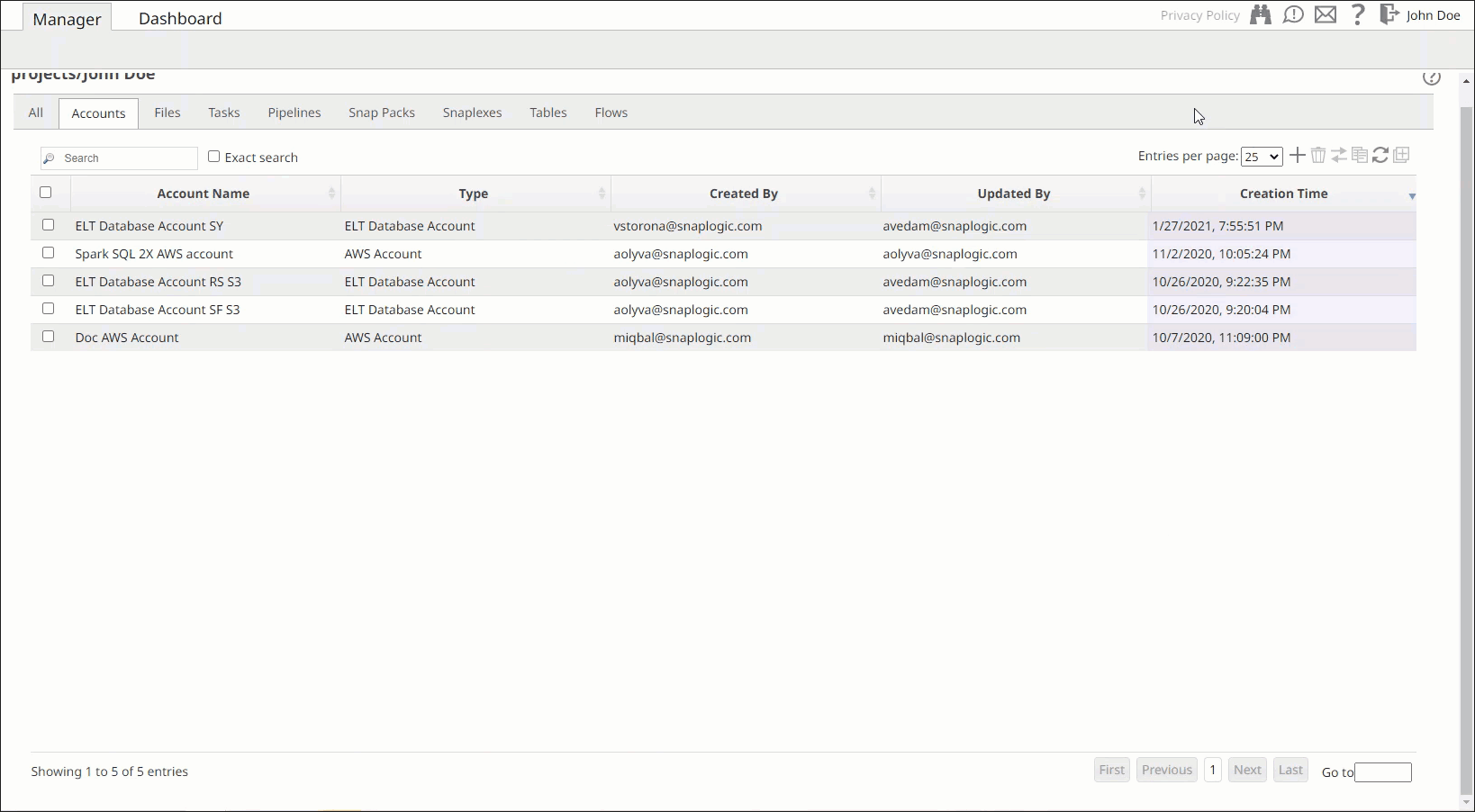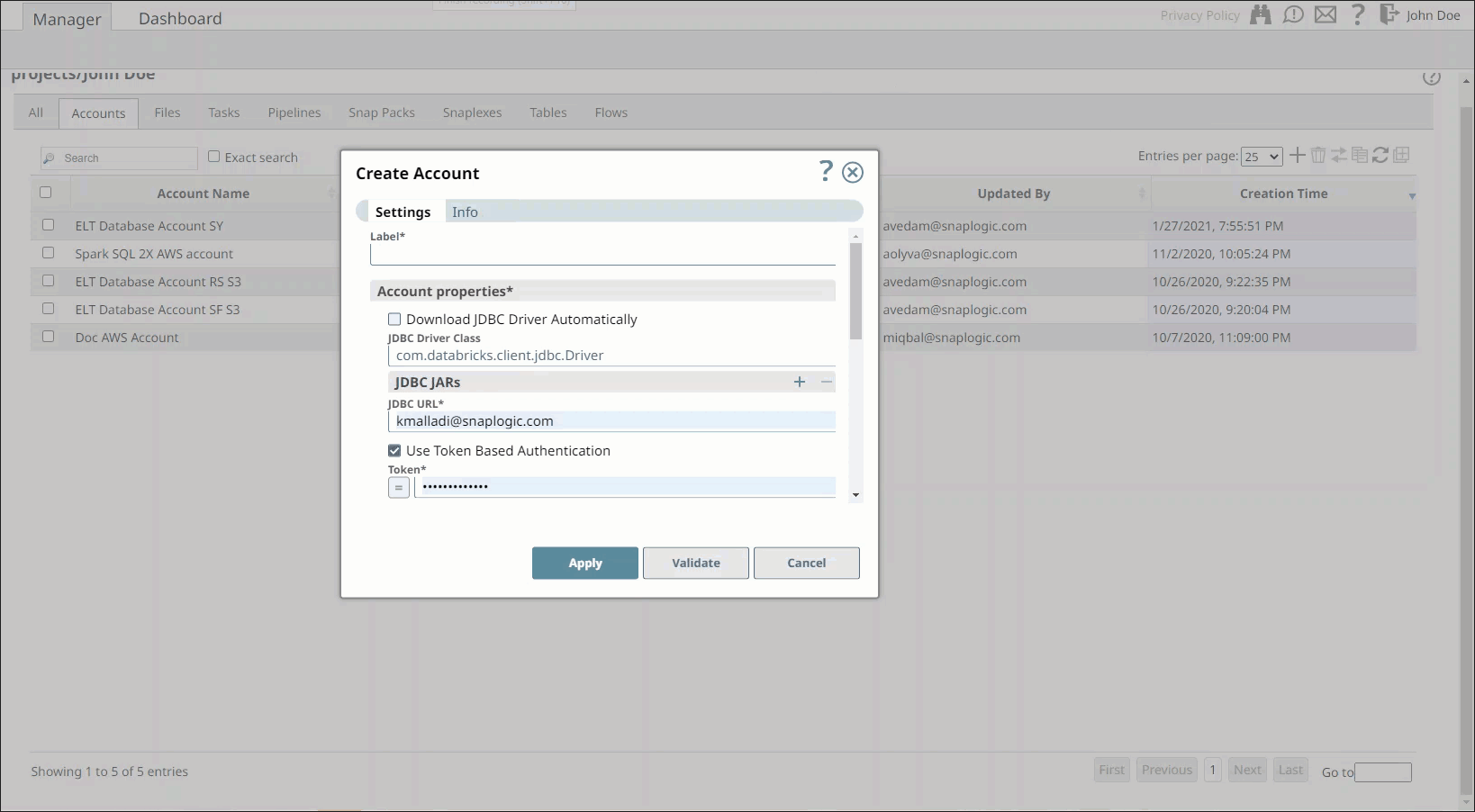
Select the Location in which you want to create the account, select the Account Type, and click Continue. The Add Account dialog window associated with the account type appears, as shown:
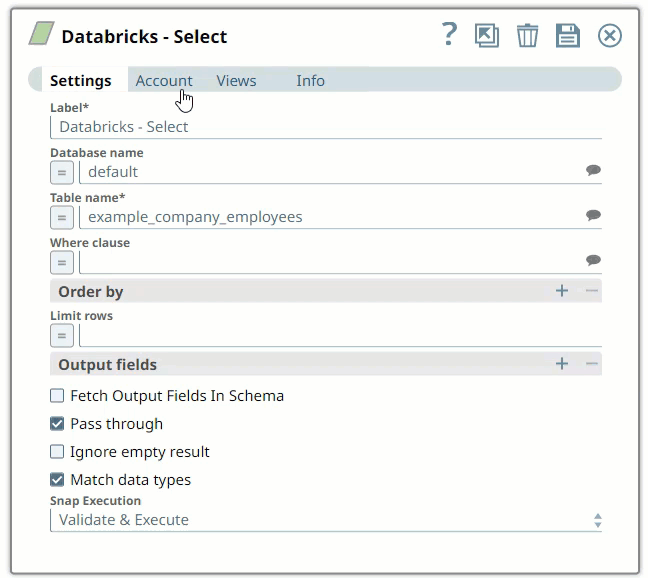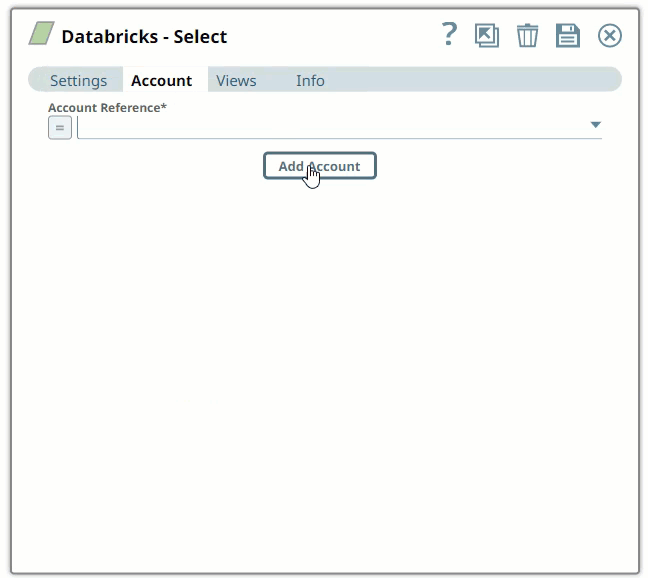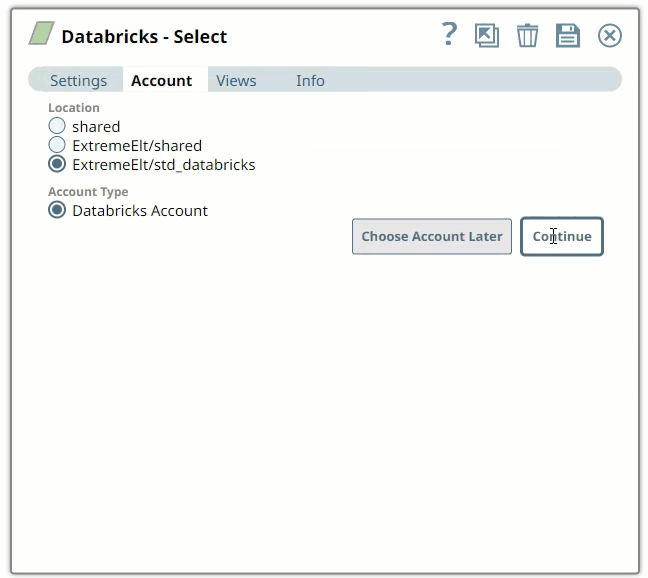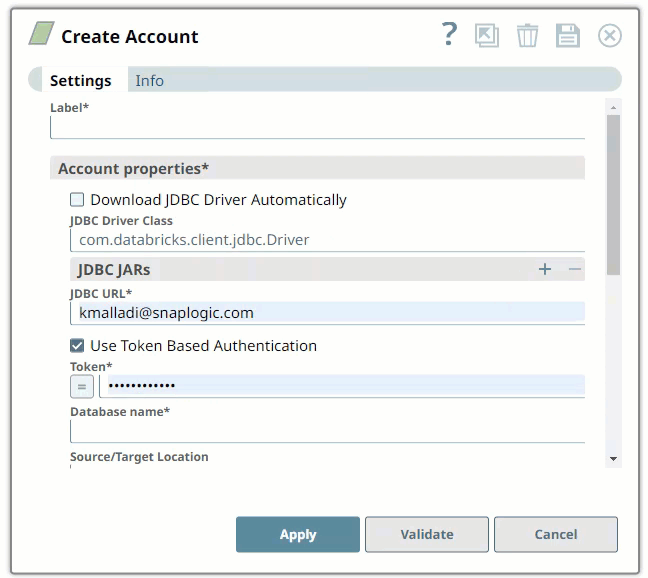
Enter the required account details. Learn more about how to provide the information required for each account type in the following articles:
Click Validate to verify the account, if the account type supports validation.
Click Apply to complete configuring the Databricks account.
You can choose the Source/Target Location as None to perform operations within the Databricks tables.
Configuring Databricks Accounts Using SnapLogic Manager
You can use Manager to create accounts without associating them immediately with Pipelines.
Accounts in SnapLogic are associated with projects. You can use accounts created in other projects only if you have at least Read access to them.
In the left pane, browse to the project in which you want to create the account and click Create > Account > Databricks, followed by the appropriate account type. The Create Account dialog associated with the selected account type appears, as shown:
Repeat steps 3 through 5 in the Creating an account section.
Avoid updating account credentials when Pipelines using that account are executing. Doing so may lead to unexpected results, including your account getting locked.