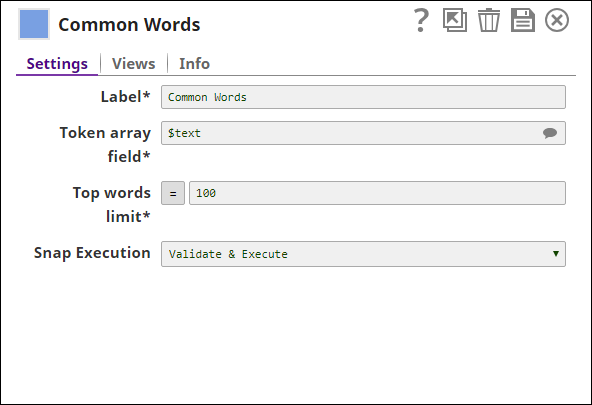
Common Words
- Rakesh Chaudhary
- Amritesh Singh
- Mohammed Iqbal
On this Page
Overview
This Snap enables you to identify the most common words in the input dataset and compute the frequency with which they occur. It also offers you the ability to specify the number of most common words you want to include in the output. The input of this Snap should be an array of tokens, which can be generated by the Tokenizer Snap.
This Snap is required for the Bag of Words Snap. The output of this Snap should be connected to the second input view of the Bag of Words Snap
Expected Input and Output
- Expected input: A document containing the field that contains the array of tokens.
- Expected output: A document containing the most common words in the input dataset along with their frequency details.
- Expected upstream Snaps: Any Snap that offers documents. For example: Tokenizer, or a combination of File Reader and JSON Parser.
- Expected downstream Snaps: Any Snap that accepts documents. For example: Bag of Words, Mapper, or a combination of JSON Formatter and File Writer.
Prerequisites
None.
Configuring Accounts
Accounts are not used with this Snap.
Configuring Views
Input | This Snap has exactly one document input view. |
|---|---|
| Output | This Snap has exactly one document output view. |
| Error | This Snap has at most one document error view. |
Troubleshooting
None.
Limitations and Known Issues
None.
Modes
- Ultra Pipelines: Does not work in Ultra Pipelines.
Snap Settings
| Label | Required. The name for the Snap. Modify this to be more specific, especially if there are more than one of the same Snap in the pipeline. |
|---|---|
| Token array field | Required. The field containing the array of tokens that must be examined for common words. This suggestible property is a JSONPath. Click the Suggestions icon to view a list of all available text fields. Default value: None. Example: $text |
| Top words limit | Required. The number of most common words to be included in the output. Default value: 100 |
Examples
Computing the Frequency of Common Words in Tokenized Text Data
In this example, we shall demonstrate how you can use the Tokenizer and Common Words Snaps to compute the frequency of the most common words in a dataset.

Download this pipeline.
This pipeline contains the following Snaps:
- File Reader: Picks up and reads the input file from SLFS.
- JSON Parser: Parses the JSON input and offers documents as output.
- Tokenizer: Converts sentences into an array of tokens.
- Common Words: Computes the frequency of the most common words in the input dataset.
The File Reader Snap reads an extract of the Yelp dataset (you can review the entire dataset here) and offers a binary stream as output. The JSON Parser Snap converts this binary stream into document stream, as shown below:
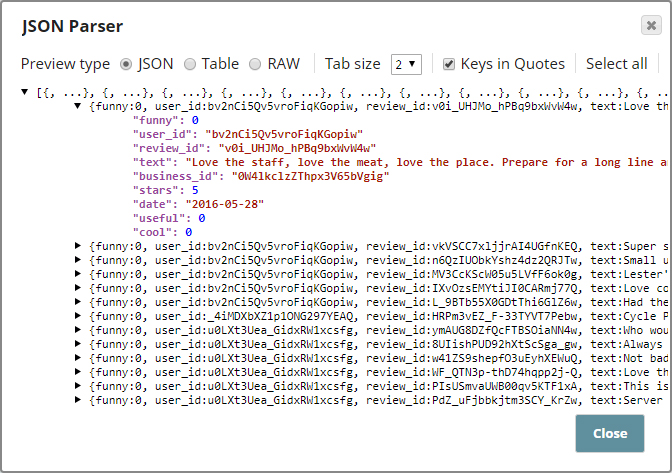
The field $text refers to sentences from Yelp user reviews. These sentences are used as input to the Tokenizer Snap using the following configurations:
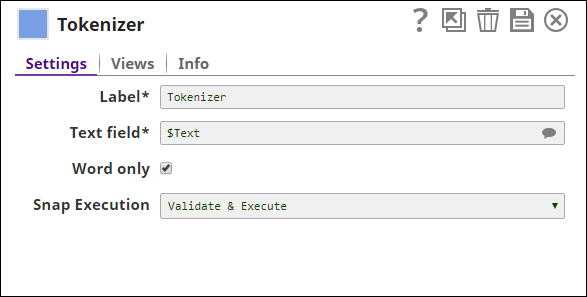
As you can see, we selected $text for the Text field property. This is the content that will be tokenized and output as an array of tokens, as shown below:
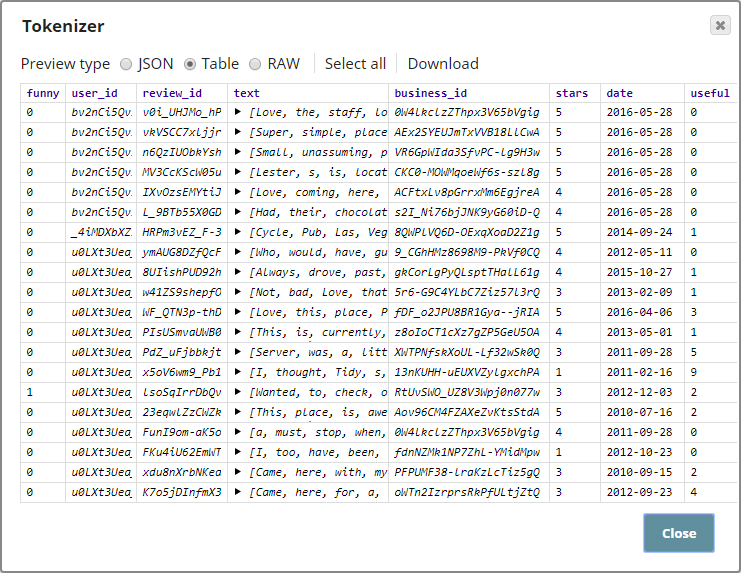
As you can see in the screenshot above, each word in the input sentences has now become a token, and sentences in each input document become an array.
The Common Words Snap computes the frequency of each word that appears in the array of tokens. We need to configure the Common Words Snap to pick up data from the Tokenizer Snap and output frequency numbers related to the top 100 most common words, as shown below:
The pipeline, when run, offers the following output:
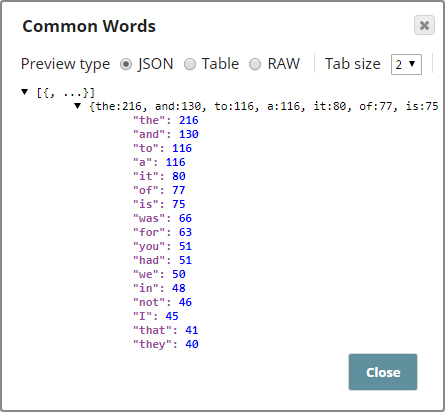
Based on the first 50 records of the Yelp dataset, during the pipeline validation, the most common words occur with the frequency shown above.
Download this pipeline.
Downloads
Important steps to successfully reuse Pipelines
- Download and import the pipeline into the SnapLogic application.
- Configure Snap accounts as applicable.
- Provide pipeline parameters as applicable.
Snap Pack History
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2024 SnapLogic, Inc.