Problem Scenario
...
- Profiling: Use Profile Snap from ML Analytics Snap Pack to get statistics of this dataset.
- Data Preparation: Perform data preparation on this dataset using Snaps in ML Data Preparation Snap Pack.
- Cross Validation: Use Cross Validator (Classification) Snap from ML Core Snap Pack to perform 10-fold cross validation on various Machine Learning algorithms. The result will let us know the accuracy of each algorithm in the success rate prediction.
We are going to build 4 pipelines: Profiling, Data Preparation, and 2 pipelines for Cross Validation with various algorithms. Each of these pipelines is described in the Pipelines section below.
Pipelines
Profiling
In order to get useful statistics, we need to transform the data a little bit.
...
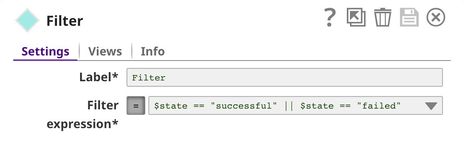
Since we only focus on successful and failed projects, we use Filter Snap to filter out live, canceled, and projects with another status.

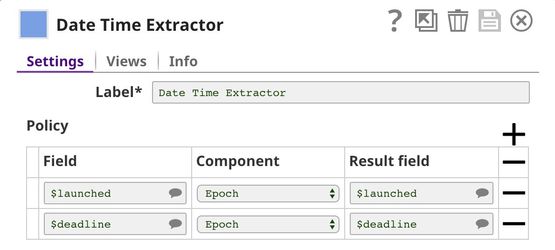
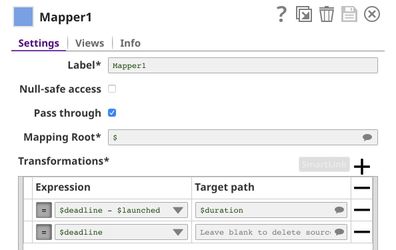
Date Time Extractor Snap is used to convert the launch date and the deadline to an epoch which are used to compute the duration in the Mapper1 Snap. With the Pass through in the Mapper1, all input fields will be sent to the output view along with the $duration. However, we drop $deadline here.


At this point, the dataset is ready to be fed into the Profile Snap.

Finally, we use Profile Snap to compute statistics and save on SLFS in JSON format.

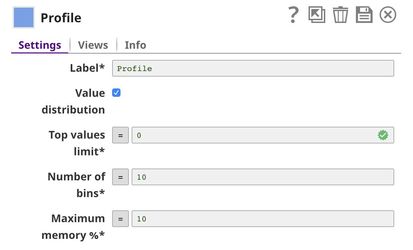
Click here to see the statistics generated by the Profile Snap.
...
In this pipeline, we want to transform the raw dataset into a format that is suitable for applying Machine Learning algorithms.

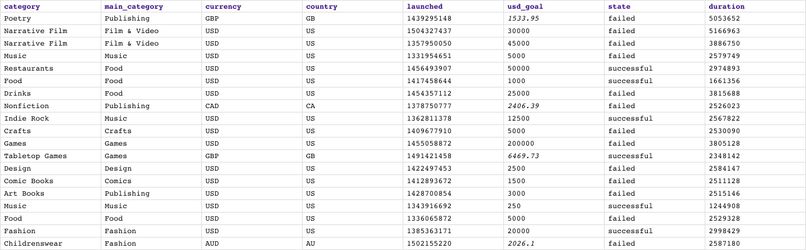
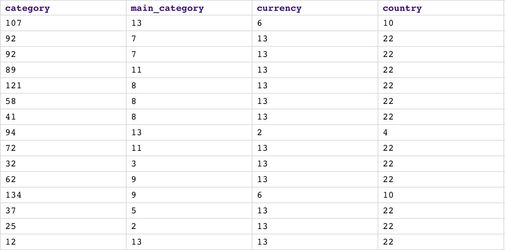
The first 7 Snaps in the top flow are the same as in the previous pipeline. We use File Reader1 Snap together with JSON Parser to read the profile (data statistics) generated in the previous pipeline. The picture below shows the output of JSON Parser Snap. Product design is the category with the most number of projects. USD is clearly the most popular currency. The country with the most number of projects is the USA.


We then use Categorical to Numeric Snap to encode categorical fields into numeric using integer encoding and one hot encoding. As you can see, each category is now represented by a number. For the state, we use one hot encoding so we get 2 fields: one for success and another one for failed.



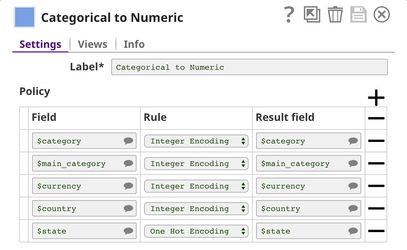
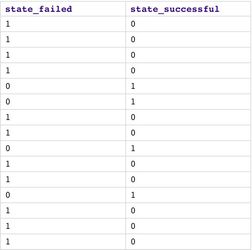
The Mapper1 Snap is used to remove $state and $state_failed.


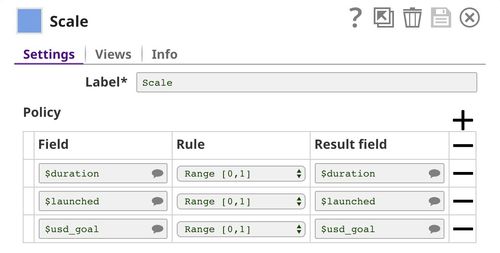
Then, we use Scale Snap to scale numeric fields into the range from 0 to 1. Having data in the same range will help in analysis, visualization, etc.

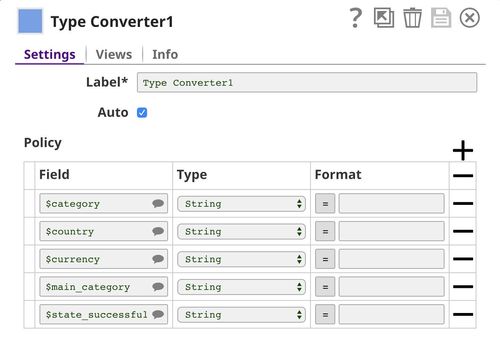
In the end, we want to make sure that categorical fields are represented as text (String data type). This is necessary since machine learning algorithms threat categorical and numeric fields differently. Profile Snap also generates a different set of statistics for categorical and numeric fields.

Click here to see the statistics generated by the Profile Snap based on the processed dataset. As you can see, the min and max of all numeric fields are 0 and 1 because of the Scale Snap.
...
The File Reader Snap reads the processed dataset generated by the data preparation pipeline and feeds into the Cross Validator (Classification) Snap. The output of this pipeline is sent to the parent pipeline.

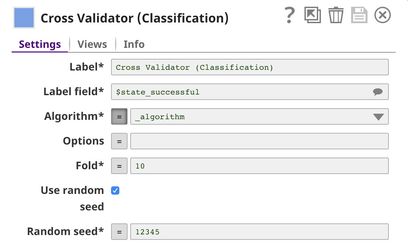
In Cross Validator (Classification) Snap, Label field is set to $state_successful which is the one we want to predict. Normally, you can select Algorithm from the list. However, we will automate trying multiple algorithms with Pipeline Execute Snap so we set the Algorithm to the pipeline parameter.


Parent Pipeline

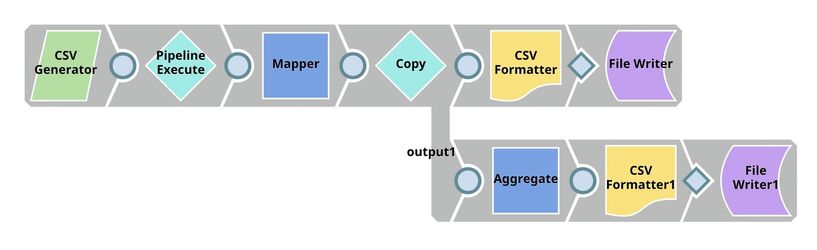
Below is the content of CSV Generator Snap. It contains a list of algorithms we want to try.
...
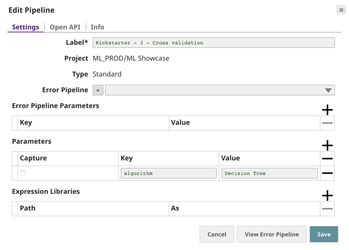
The $algorithm from CSV Generator will be passed into the child pipeline as pipeline parameter. For each algorithm, a child pipeline instance will be spawned and executed. You can execute multiple child pipelines at the same time by adjusting Pool Size. The output of the child pipeline will be the output of this Snap. Moreover, the input document of the Pipeline Execute Snap will be added to the output as $original.


The Mapper Snap is used to extract the algorithm name and accuracy from the output of the Pipeline Execute Snap.

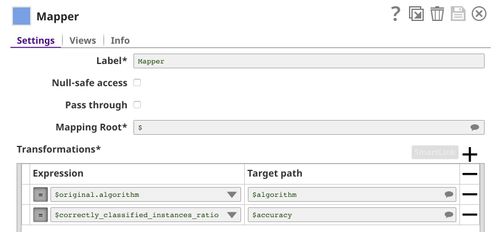
The Aggregate Snap is used to find the best accuracy among all algorithms.
...