Problem Scenario
...
- Profiling: Use Profile Snap from ML Analytics Snap Pack to get statistics of this dataset.
- Data Preparation: Perform data preparation on this dataset using Snaps in ML Data Preparation Snap Pack.
- Cross Validation: Use Cross Validator (Classification) Snap from ML Core Snap Pack to perform 10-fold cross validation on various Machine Learning algorithms. The result will let us know the accuracy of each algorithm in the success rate prediction.
We are going to build 4 pipelines: Profiling, Data Preparation, and 2 pipelines for Cross Validation with various algorithms. Each of these pipelines is described in the Pipelines section below.
Pipelines
Profiling
In order to get useful statistics, we need to transform the data a little bit.
...
Below is the content of CSV Generator Snap. It contains a list of algorithms we want to try.


The $algorithm from CSV Generator will be passed into the child pipeline as pipeline parameter. For each algorithm, a child pipeline instance will be spawned and executed. You can execute multiple child pipelines at the same time by adjusting Pool Size. The output of the child pipeline will be the output of this Snap. Moreover, the input document of the Pipeline Execute Snap will be added to the output as $original.
...
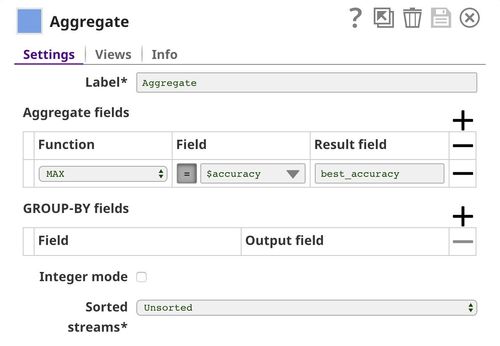
The Aggregate Snap is used to find the best accuracy among all algorithms.

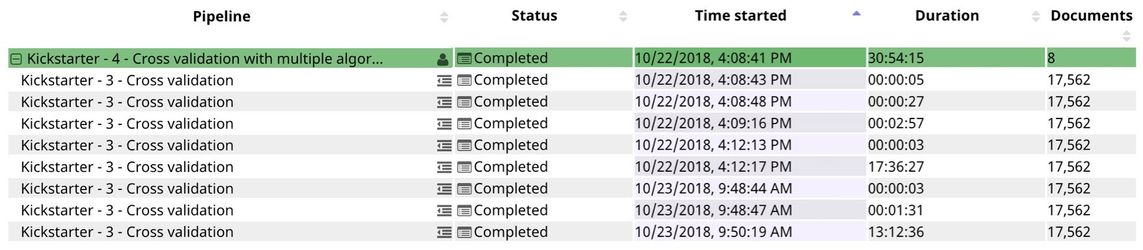
As you can see in the runtime below, 8 child pipeline instances were created and executed. The 5th algorithm (Support Vector Machines) took over 17 hours to run. The last algorithm (Multilayer Perceptron) also took a long time. The rest of the algorithms can be completed within seconds or minutes. The duration depends on the number of factors. Some of them are the data type, number of unique values, and distribution.

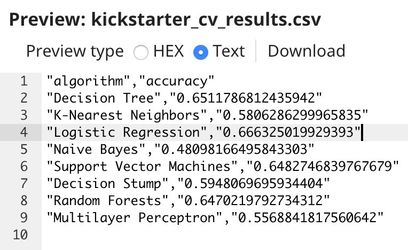
Below is the result. The logistic regression performs the best on this dataset at 66.6% accuracy. This is better than the baseline at 59.5%. However, it may not be practical to use. We may be able to do better than this by gathering more data about the project or improving the algorithm.