On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
Snap type: | Write | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Description: | This Snap executes an SQL Server bulk load. The Snap uses the bcp utility program internally to perform the bulk load action. The input data is first written to a temporary data file, then the bcp utility program loads the data from the data file into the target table.
Table CreationIf the table does not exist when the Snap tries to do the load, and the Create table property is set, the table will be created with the columns and data types required to hold the values in the first input document. If you would like the table to be created with the same schema as a source table, you can connect the second output view of a Select Snap to the second input view of this Snap. The extra view in the Select and Bulk Load Snaps are used to pass metadata about the table, effectively allowing you to replicate a table from one database to another. The table metadata document that is read in by the second input view contains a dump of the JDBC DatabaseMetaData class. The document can be manipulated to affect the CREATE TABLE statement that is generated by this Snap. For example, to rename the name column to full_name, you can use a Mapper (Data) Snap that sets the path $.columns. Name.COLUMN_NAME to full_name. The document contains the following fields:
SQL Server Bulk Load Snap does not accept the results by the DateTime string from the expression Date.toLocaleDateTimeString().
| |||||||||||||
| Prerequisites: | The BCP utility must be installed on the Groundplex nodes on which you want to execute this Snap. To install the BCP utility on a Groundplex:
| |||||||||||||
| Troubleshooting | Problem: Some characters appear as junk values after bulk load. Reason: The Snaplex uses character sets defined in the OS on which they are installed. Due to this, any unrecognized character set is not supported by the Snaplex as well. As a result, such characters in the data set are represented as junk values in the database after a bulk load operation. Resolution: This problem can be resolved by editing the bcp.bat file to accept custom characters. And using the absolute path to this bcp file in the BCP absolute path property. The bcp.bat file must contain the following:
| |||||||||||||
| Support and limitations: | Ultra pipelines: Does not work in Ultra Pipelines. | |||||||||||||
| Account: | This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See Configuring SQL Server AccountAccounts for information on setting up this type of account. | |||||||||||||
| Views: |
| |||||||||||||
Settings | ||||||||||||||
Label | Required. The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | |||||||||||||
Schema Name | The database schema name. In case it is not defined, then the suggestion for the Table Name will retrieve all tables names of all schemas. The property is suggestible and will retrieve available database schemas during suggest values.
Example: SYS | |||||||||||||
Table Name | Required. Table on which to execute the bulk load operation.
Example: people Default value: [None]
Examples: | |||||||||||||
Create table if not present | Whether the table should be automatically created if it is not already present.
| |||||||||||||
BCP absolute path | The absolute path of the bcp utility program in JCC's file system. If empty, the Snap looks for it in JCC's environment variable PATH. Example: C:\bcp.bat Default value: [None]
Handling Unrecognized Character sets in the Data set Since the Snaplex uses the OS's default character set, it cannot recognize characters in other languages. Due to this, unrecognized characters in the data set are replaced with junk values when performing bulk load operations. To mitigate this, create a bcp.bat file and include the following line:
Use the path to this bcp.bat file in the BCP absolute path.
| |||||||||||||
Maximum error count | Required. The maximum number of rows which can fail before the bulk load operation is stopped. Default value: 10 | |||||||||||||
|
| |||||||||||||
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|
Example
This example loads data from table bulk_test_source to table bulk_test_target with SQL Server Bulk Load Snap.
The pipeline:
.png?version=1&modificationDate=1489655245477&cacheVersion=1&api=v2)
The SQL Server Select Snap gets records in the table bulk_test_source and passes them to the SQL Server Bulk Load Snap:
.png?version=1&modificationDate=1489654755277&cacheVersion=1&api=v2&width=540)
The SQL Server Bulk Load Snap that loads inputs to table bulk_test_target looks as follows:
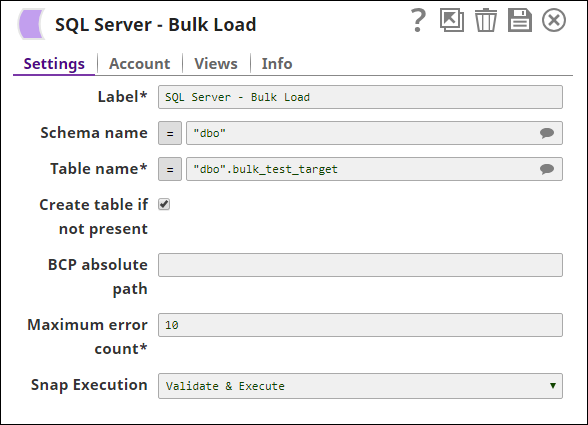
The output of the SQL Server Bulk Load Snap after executing the pipeline:
.png?version=1&modificationDate=1489654859797&cacheVersion=1&api=v2&width=650)
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|