On this Page
...
Type | Format | Number of Views | Examples of Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
Input | Document |
|
| Incoming documents are first written to a staging file on Snowflake's internal staging area. A temporary table is created on Snowflake with the contents of the staging file. An update operation is then run to update existing records in the target table and/or an insert operation is run to insert new records into the target table. |
Output | Document |
|
| If an output view is available, then the output document displays the number of input records and the status of the bulk upload as follows:. |
Error | Error handling is a generic way to handle errors without losing data or failing the Snap execution. You can handle the errors that the Snap might encounter when running the Pipeline by choosing one of the following options from the When errors occur list under the Views tab:
Learn more about Error handling in Pipelines. | |||
...
Error | Reason | Resolution |
|---|---|---|
Cannot lookup a property on a null value. | The value referenced in the Key Column field is null. This Snap does not support values from an upstream input document in the Key columns field when the expression button is enabled. | Update the Snap settings to use an input value from pipeline parameters and run the pipeline again. |
Data can only be read from Google Cloud Storage (GCS) with the supplied account credentials (not written to it). | Snowflake Google Storage Database accounts do not support external staging when the Data source is the Input view. Data can only be read from GCS with the supplied account credentials (not written to it). | Use internal staging if the data source is the input view or change the data source to staged files for Google Storage external staging. |
Example
Upserting Records
This example Pipeline demonstrates how you can efficiently update and delete data (rows) using the Key Column ID field and Upsert Delete condition. We use Snowflake - Bulk Upsert Snap to accomplish this task.
...
First, we configure the Mapper Snap with the required details to pass them as inputs to the downstream Snap.
...
After validation, the Mapper Snap prepares the output as shown below to pass to the Snowflake Bulk - Upsert Snap.
...
Next, we configure the Snowflake - Bulk Upsert Snap to:
Upsert the existing row for P_ID column, (so, we provide P_ID in the Key column field).
Delete the rows where the FIRSTNAME is snaplogic in the target table, (so, we specify FIRSTNAME = 'snaplogic' in the Delete Upsert Condition field).
...
After execution, this Snap inserts a new record into the existing row for the P_ID key column in Snowflake.
Inserted Records Output in JSON | Inserted Records in Snowflake |
|---|---|
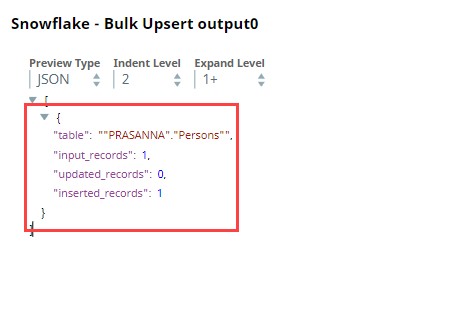 | 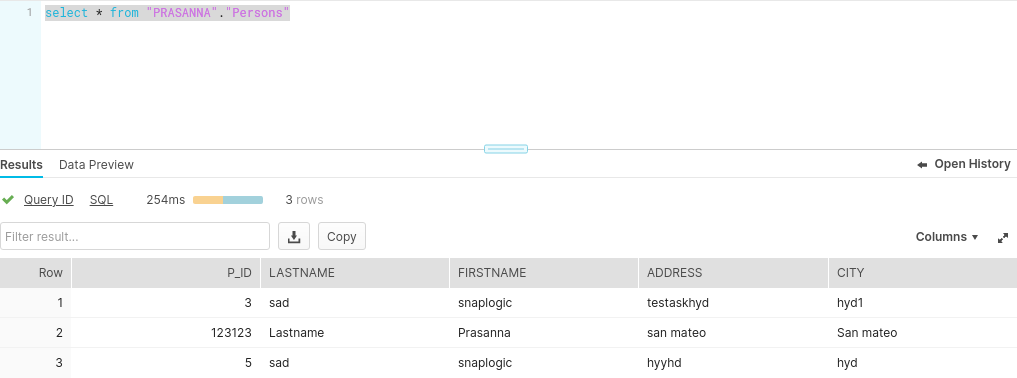 |
Upon execution, if the Delete Upsert condition is true, the Snap deletes the records in the target table as shown below.
Output in JSON | Deleted Record in Snowflake |
|---|---|
 | 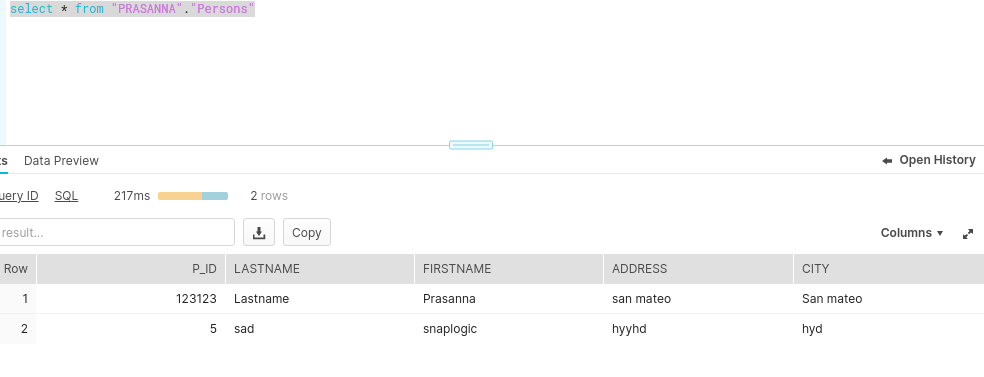 |
Bulk Loading Records
In the following example, we update a record using the Snowflake Bulk Upsert Snap. The invalid records which cannot be inserted will be routed to an error view.
...