On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
Overview
This is a Transform type Snap that converts numeric fields into categoricalfields. There are two available splitting options: splitting by values and binning.

Input and Output
Expected input
- Dataset in the first First input view: A document that contains numeric fields.Profile information in the second
- Second input view: A document that contains data statistics computed by the Profile Snap.
Expected output: Document data containing the original dataset along with the data converted from numeric to categorical format A document that contains categorical fields.
Expected upstream Snaps:
- First Input View: Any Snap, such as the CSV Generator Snap, that offers a document view in its output.Second Input View: A Profile Snap that offers data statistics necessary for performing a numeric to categorical conversion, or a combination of a File Reader Snap and JSON Parser Snap to read the profile information from SLDBinput view: A Snap that has a document output view. Example: CSV Generator Snap.
- Second input view: A sequence of File Reader and JSON Parser Snaps. These Snaps read the data statistics computed by the Profile Snap in another pipeline.
Expected downstream Snaps: Any Snap that accepts document data in the A Snap that has a document input view. Example: Mapperthe Aggregate Snap, or a combination of JSON Formatter and File Writer to write the file to SLDB.
Prerequisites
A basic understanding of the sampling algorithms supported by the Snap is preferableNone.
Configuring Accounts
Accounts are not used with this Snap.
Configuring Views
Input | This Snap has exactly two document input views, the Data input view and the Profile input view. |
|---|---|
| Output | This Snap has exactly one document output view. |
| Error | This Snap has at most one document error view. |
Troubleshooting
None
Limitations and Known Issues
None
Modes
- Ultra pipelinesPipelines: Works with Ultra Pipelines only when the Profile Snap is not used upstream.Spark mode: Does not support Spark mode Works in Ultra Pipelines.
Snap Settings
| Label | Required. The name for the Snap. Modify this to be more specific, especially if there are more than one of the same Snap in the pipeline. |
|---|---|
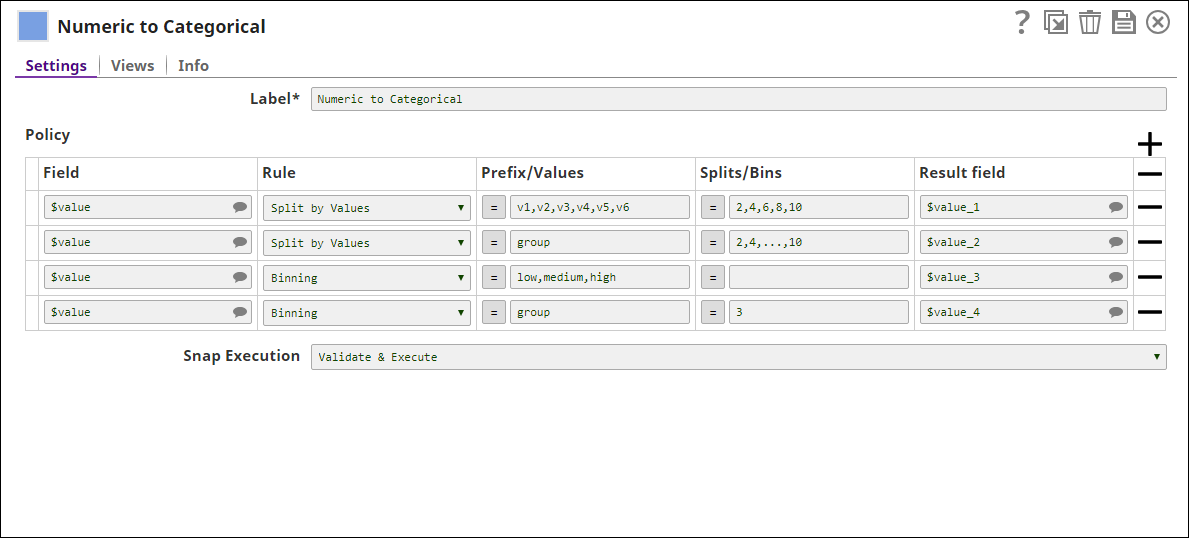
| Policy | This setting allows you to specify your preferences about The preferences for fields and transformationsencoding methods. For each policy, select the input field , it is possible to apply multiple transformations, this results in multiple output fields. Note that the policy is applied from top to bottomwith categorical values, the encoding method, and the result field. |
| Field | The field to be Required. The field that must be transformed. This is a suggestible field and will suggest all property that lists all available fields in the datasetinput documents. Default value: None |
| Rule | Required. The type of transformation to be performed on the selected field. Two options are available:
Please see the example below for better understanding.
Default value: Split by Values |
| Prefix/Values | Categorical values to be used to replace original numeric values. You can use the values in this field either as specify either a prefix or multiple values in this property. For example, if the prefix is "group", the values will be "group_1", "group_2" and so on. In case of specifying values, use comma "," to separate them. Default value: None |
| Splits/Bins | The values to be entered into this field change based property depends on the selection you made in the Rule fieldproperty.
Default value: None |
| Result field | Required. The result field that must be used in the output map. If the Result field is the same as Field, the values are overwritten. If the Result field does not exist in the original input document, a new field is added. Default value: None |
Additional Resources
Snap HistorySnap Execution | Select one of the following three modes in which the Snap executes:
Default Value: Execute only |
|---|
Examples
Converting Numeric Data into Categorical Values
This pipeline demonstrates how you can use the Numeric to Categorical Snap to convert numeric fields into categorical fields.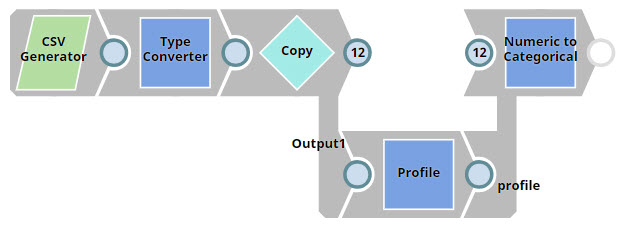
Download this pipeline.
| Expand | ||
|---|---|---|
| ||
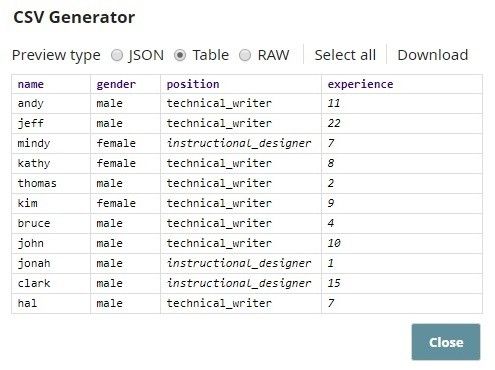
In this example, the CSV Generator Snap contains sample data with numeric fields. The Copy Snap duplicates the data flow and feeds it into the Numeric to Categorical and Profile Snaps. The Profile Snap generates input data statistics and feeds them into the Numeric to Categorical Snap. The Numeric to Categorical Snap then converts the numeric values in the fields of your choice into categorical values, based on the splitting method you select. Enter the following data into the CSV Generator Snap:
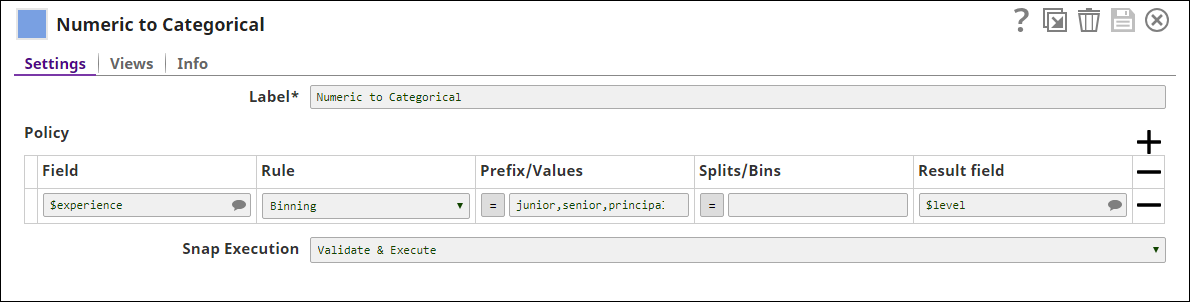
First, we need to convert values in $experience into numeric values. We do this using a Type Converter Snap with the Auto check box selected. We want to categorize employees based on their years of experience into "junior", "senior", and "principal". We choose Binning in the Rule property to ensure that the data ranges after splitting are equally spaced. The Numeric to Categorical Snap contains the following settings:
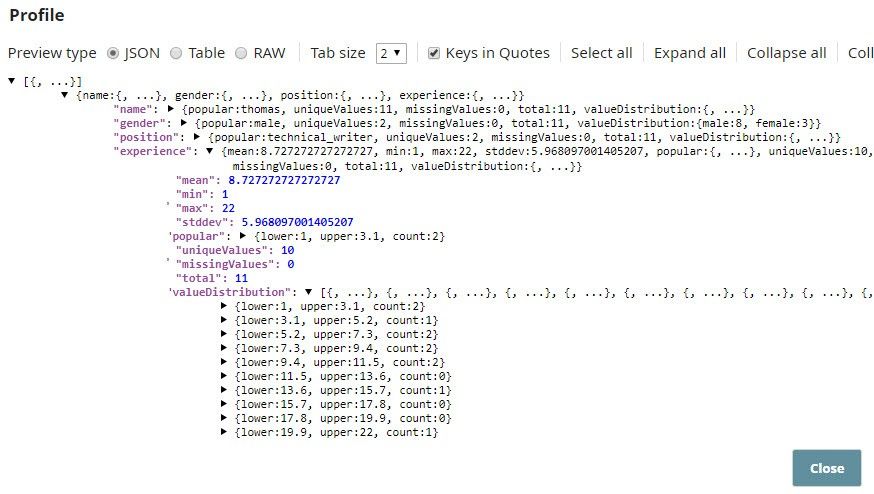
The Profile Snap computes the min and max values in the input data, which is required by Binning.
As you can see, $experience contains min and max values, which are 1 and 22 respectively.
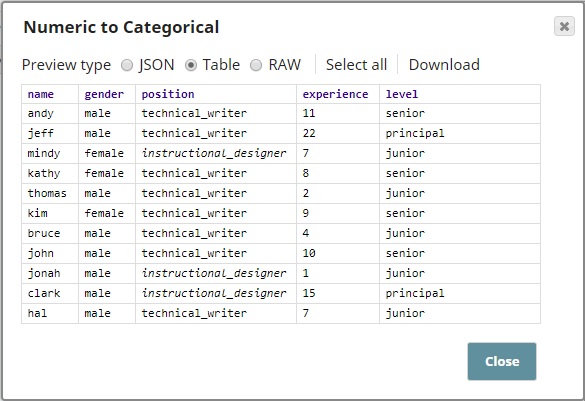
The preview output of the Numeric to Categorical Snap is shown below. This Snap adds one field to the output.
|
Downloads
| Multiexcerpt include macro | ||||
|---|---|---|---|---|
|
| Attachments | ||||||
|---|---|---|---|---|---|---|
|
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|