SnapLogic Data Science (Machine Learning)
On this page
Overview
SnapLogic Data Science, in combination with the Intelligent Integration Platform, is a self-service platform for end-to-end ML that offers a low-code approach to data acquisition, data exploration and preparation, model training and validation, and model deployment. The Data Science solution includes the following Snap Packs:
- ML Analytics Snap Pack: Perform analytic operations, such as data profiling and data type inspection.
- ML Data Preparation Snap Pack: Perform preparatory operations on datasets such as data type transformation, data cleansing, sampling, shuffling, and scaling.
- ML Core Snap Pack: Perform machine learning operations on datasets, such as cross validation, model training, and model-based predictions.
- ML Natural Language Processing Snap Pack: Perform operations in natural language processing (NLP).
Checkout the Data Science Use Cases that to understand how you can leverage the above machine learning Snaps.
Data Science Project Life Cycle
The main objective of SnapLogic Data Science is to analyze and interpret data to help you gain meaningful business insights. The following are the key steps in a typical data science project lifecycle:
- Data Acquisition: Collate and integrate data from multiple sources including files, databases, on-premise applications, cloud applications, APIs, IoT devices, etc.
- Data Exploration: Perform data profiling, analytics, and visualization to better understand the data. Then, define the business problems we want to solve with that data.
- Data Preparation: Perform data cleansing, scaling, and other statistical techniques to transform the data into datasets that are suitable for Machine Learning algorithms.
- Model Development: Develop, apply, and evaluate machine learning algorithms on the dataset. The result is an ML model that can predict.
- Model Deployment: Host the ML model as an API so that it can be easily consumed by external applications.
- Optimization: Keep track of the performance of the model, gather feedback, and iterate. Data distribution changes over time; monitoring and optimization are the key success factors.
Data Science Pipelines
A SnapLogic Pipeline is a set of Snaps that connect together to perform a specific task. In a data science project, we recommend the following five Pipeline types:
- Profiling Pipeline: Compute data statistics on the dataset. Data statistics are critical to understand the dataset and its distribution, and also for selecting the appropriate data preparation techniques in the next step.
- Data Preparation Pipeline: Apply data cleansing, and other statistical transformations to prepare the dataset before applying ML algorithms.
- Cross Validation Pipeline: Perform k-fold cross validation using various ML algorithms with different sets of parameters to find an optimal algorithm for your dataset.
- Model Building Pipeline: Train the model using an optimal algorithm and parameters from the cross validation step.
- Model Hosting Pipeline: Deploy the model as a low-latency API using Ultra Tasks.
The following table displays a Pipeline set from the Telco Customer Churn Prediction use case. You can reuse these Pipelines by connecting to your data sources.
| Pipeline | Description |
|---|---|
| Profiling. This Pipeline reads the dataset from SnapLogic File System (SLFS), performs type conversion, and computes data statistics that are saved into the SLFS in JSON format. |
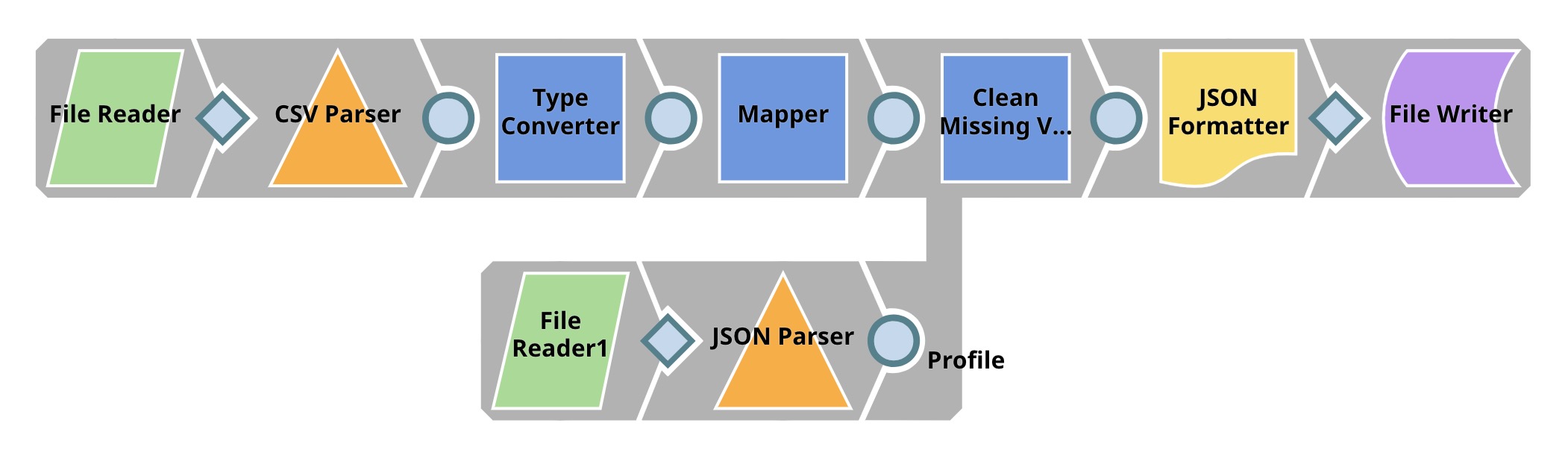
| Data Preparation. This Pipeline also reads the dataset from SLFS, performs type conversion. Then, the Mapper Snap removes id field from the dataset. The Clean Missing Value Snap replaces all missing values in the dataset with average value. The average value is included in the data statistics computed in the previous Pipeline. We use the File Reader Snap to read these statistics. |
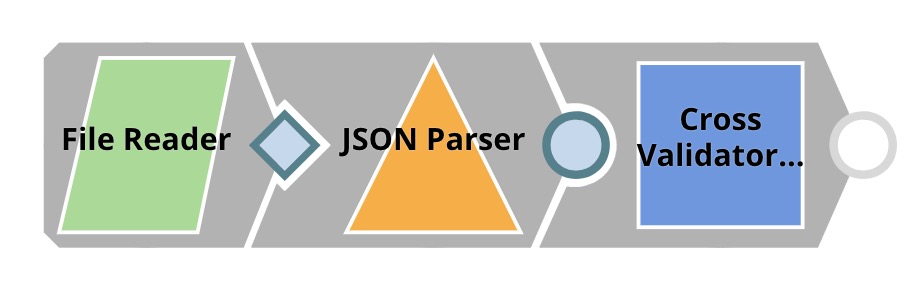
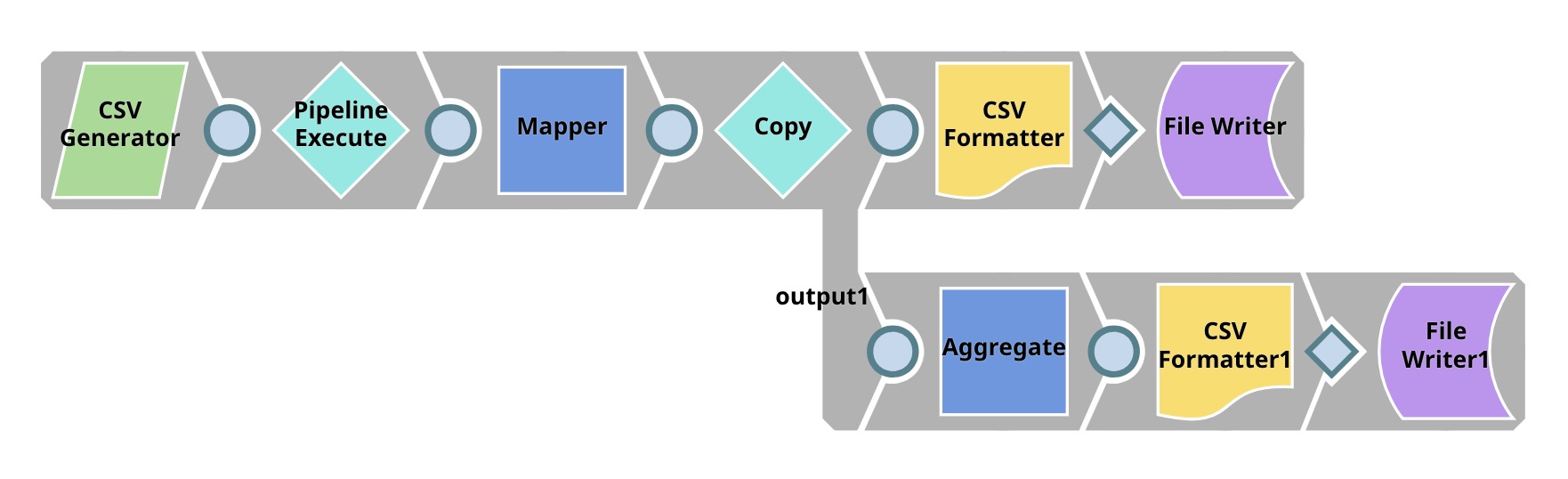
| Cross Validation. We have two Pipelines in this step. The top Pipeline (child Pipeline) performs k-fold cross validation using a specific ML algorithm. The Pipeline on the bottom (parent Pipeline) uses the Pipeline Execute Snap to automate the process of performing k-fold cross validation on multiple algorithms, the Pipeline Execute Snap spawns and executes child Pipeline multiple times with different algorithms. Instances of child Pipelines can be executed sequentially or in parallel to speed up the process by taking advantages of multi-core processor. The Aggregate Snap applies max function to find the algorithm with the best result. |
| |
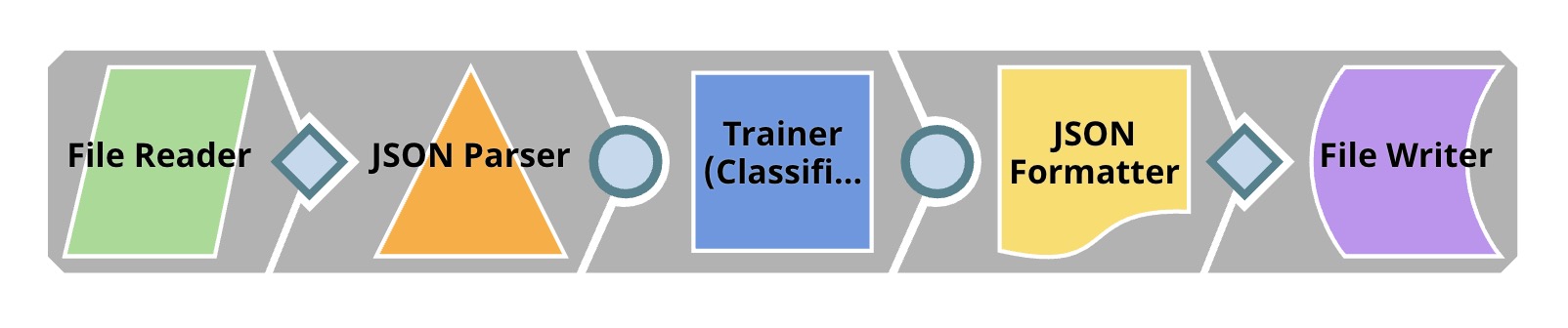
| Model Building. After knowing which algorithm performs the best on your dataset, this Pipeline builds the model using the Trainer (Classification) Snap. You can store this model in JSON, binary, or other formats. |
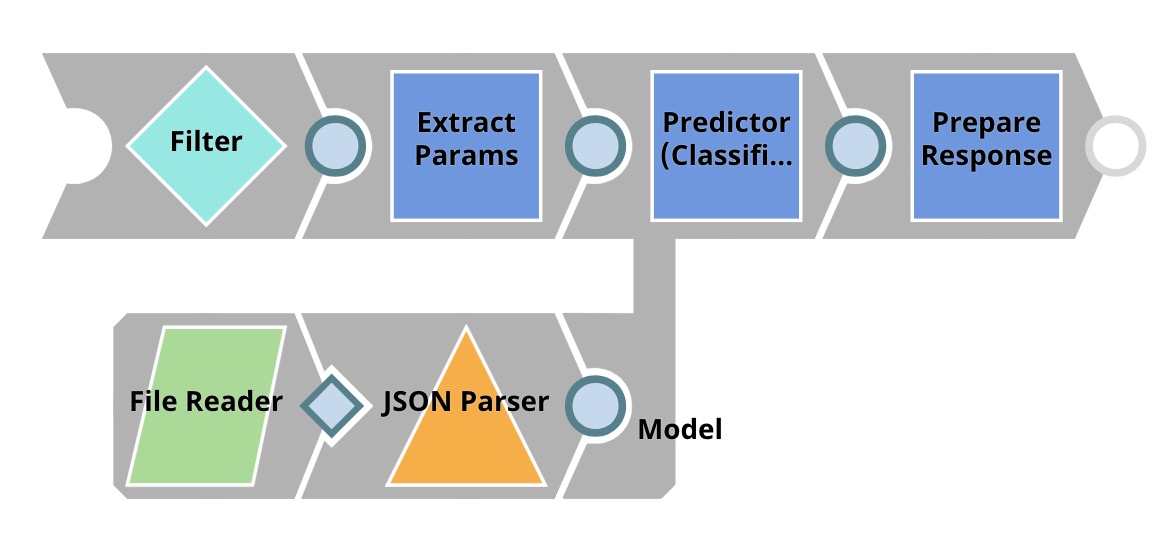
| Model Hosting. This Pipeline is scheduled as Ultra Task to provide REST API to external application. The request comes as an open input view. The key Snap in this Pipeline is Predictor (Classification), which hosts the ML model from JSON Parser and consumes requests from Extract Params (Mapper) Snap. It applies the ML model on the data in the request and generates a prediction. |

Data Science Snap Packs
ML Data Preparation Snap Pack
This Snap Pack contains Snaps to prepare the dataset. Data preparation processes include handling missing values, scaling, sampling, transforming, and others.
| Snap | Description |
|---|---|
| Clean Missing Values | Replace missing values by dropping, or imputing. |
| Type Converter | Determine types of values in columns. This Snap supports four data types: integer, floating point, text, or datetime. |
| Categorical to Numeric | Convert categorical columns into numeric columns by integer encoding or one hot encoding. |
| Numeric to Categorical | Convert numeric columns into categorical columns by custom ranging or binning. |
| Scale | Scale values in columns to specific ranges or apply statistical transformations. |
| Shuffle | Randomly shuffle rows. |
| Sample | Randomly keep/drop rows. This Snap supports Stratified sampling. |
| Date Time Extractor | Extract components from date-time objects. |
| Principal Component Analysis | Perform principal component analysis (PCA) on numeric fields (columns) to reduce the dimensions of the dataset. |
| Feature Synthesis | Create features out of multiple datasets that share a one-to-one or one-to-many relationship with each other. Features are measurements of data points. For example, height, mean, mode, min, max, etc. |
| Mask | Hide sensitive information in your dataset before exporting the dataset for analytics. |
| Match | Perform record linkage to identify documents from different data sources (input views) that may represent the same entity without relying on a common key. The Match Snap enables you to automatically identify matched records across datasets that do not have a common key field. |
| Deduplicate | Remove duplicate records from input documents. |
ML Core Snap Pack
This Snap Pack contains Snaps that experiment with machine learning algorithms, build ML models, and use ML models. It also contains Remote Python Script Snap to execute Python script natively.
| Snap | Description |
|---|---|
| AutoML | Automate the process of exploring and tuning machine learning models for a given dataset within specific resource limits. |
| Clustering | Perform exploratory data analysis to find hidden patterns or groupings in data. |
| Cross Validator (Classification) | Perform k-fold cross validation with state-of-the-art machine learning algorithms on classification dataset. |
| Cross Validator (Regression) | Perform k-fold cross validation with state-of-the-art machine learning algorithms on regression dataset. |
| Trainer (Classification) | Train the model using state-of-the-art machine learning algorithms on classification dataset. |
| Trainer (Regression) | Train the model using state-of-the-art machine learning algorithms on regression dataset. |
| Predictor (Classification) | Apply the model trained from Trainer (Classification) Snap and get prediction for unlabeled data. |
| Predictor (Regression) | Apply the model trained from Trainer (Regression) Snap and get prediction for unlabeled data. |
| Remote Python Script | Execute Python script natively on Python server. |
ML Natural Language Processing Snap Pack
This Snap Pack contains Snaps that enable you to perform operations in natural language processing (NLP).
| Snap | Description |
|---|---|
| Tokenizer | Converts sentences into an array of tokens. |
| Common Words | Finds the most popular words in the dataset of input sentences. |
| Bag of Words | Vectorizes sentences into a set of numeric fields. |
ML Analytics Snap Pack
This Snap Pack contains Snaps to analyze the data.
| Snap | Description |
|---|---|
| Profile | Compute data statistics. |
| Type Inspector | Display data types. |
Getting Started with SnapLogic Data Science
Machine Learning Showcase
The best way to learn about data science and machine learning is to try them out. We have developed and deployed demos using SnapLogic Data Science. They are available on SnapLogic Machine Learning Showcase.
Machine Learning Use Cases
You can understand how to build the above SnapLogic demos using SnapLogic Data Science by going through our use cases.
Pipeline Patterns
You can access pre-built Data Science Pipelines that reflect the use cases in the Designer > Patterns tab.
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2025 SnapLogic, Inc.