On this Page
| Table of Contents | ||||
|---|---|---|---|---|
|
Snap Type: | Read | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Description: | This Snap outputs a list of tables in a database. The Snap will connect to the database, read its metadata, and output a document for each table found in the database. The table names are output in a topological order so that tables with the fewest dependencies are output first. In other words, if table A has a foreign key reference to table B, then table B will be output before A. The ordering is intended to ease the process of replicating a group of tables from one database to another.
Replicating a Subset of TablesThe output of the Table List Snap can be directly used to replicate an entire database. However, if you are only interested in a subset of tables, you can use a Filter Snap to select the table names you are interested in as well as the tables that they reference. For example, given the following diamond-shaped table graph where A depends on B and C and they both depend on D:
The Table List will output the following documents:
So, if you wanted to copy just table 'A' and its dependencies, you can add a Filter Snap with the following expression:
ETL Transformations & Data FlowThis snap is a data source. It works by performing a standard JDBC DatabaseMetaData#getTables() query for the tables within the database. The Schema name value is used to populate the schemaPattern parameter in that query. This snap does not require any temporary files or other external resources. Input & Output
Expected upstream Snaps: Any Snap with a document output view. Note: the contents of the input view are ignored so pipelines should only be used to sequence operations. Expected downstream Snaps: Any Snap with a document input view, such as JSON Formatter, Mapper, and so on. The CSV Formatter Snap cannot be connected directly to this Snap since the output document map data is not flat. Modes
| |||||||||||||
| Prerequisites: |
| |||||||||||||
| Limitations and Known Issues | None at the moment.
| |||||||||||||
| Configurations: | This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See Redshift Account for information on setting up this type of account. | |||||||||||||
| Views: |
| |||||||||||||
| Troubleshooting: | None at the moment. | |||||||||||||
Settings | ||||||||||||||
Label | Required The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline. | |||||||||||||
Schema name | The database schema name. In case it is not defined, then the suggestion for the table name will retrieve all tables names of all schemas. The property is suggestible and will retrieve available database schemas during suggest values.
Example: test Default value: [None] Expression property: No | |||||||||||||
| Compute table graph | Computes the dependents among tables and returns each table with a list of tables it has foreign key references to. The ordering of outputted tables is from least dependent to most-dependent.
Default value: Not selected | |||||||||||||
| page | Anaplan Read
| name | Snap Execution||||||||||||
| page | Anaplan Read | |||||||||||||
| Multiexcerpt include macro | ||||||||||||||
| name | Snap_Execution_Introduced | Default Value: Validate & Execute | Select an option to specify how the Snap must be executed. Available options are:
| |||||||||||
Troubleshooting
| Multiexcerpt include macro | ||||||||
|---|---|---|---|---|---|---|---|---|
|
Examples
Basic Use Case
The following pipeline describes how the Snap functions in a standalone Snap in a pipeline.
- Below is a preview of the output from the Redshift Table List Snap depicting that all the tables records from ALL schema:
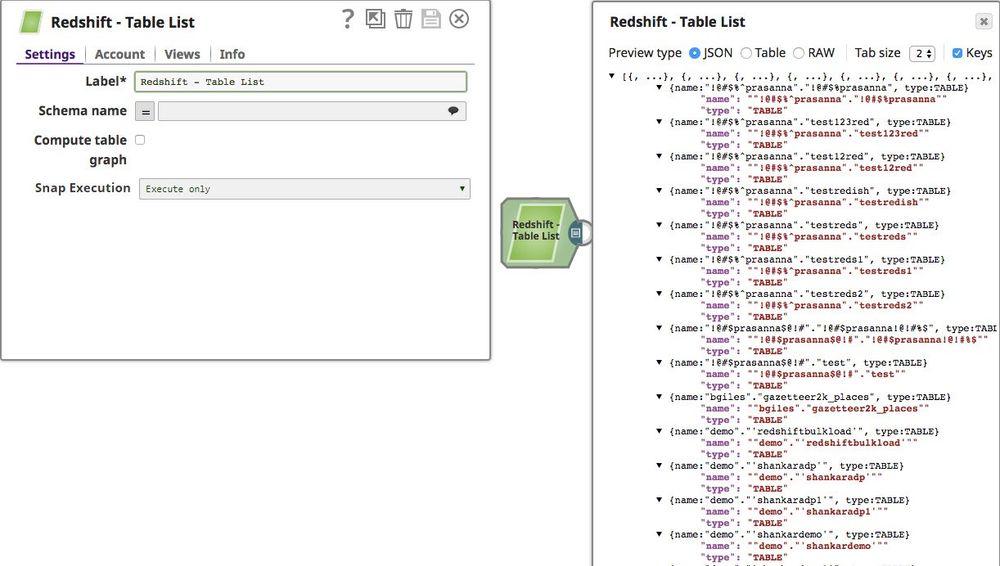
Refer to the "Redshift Table List_ALL.slp" in the Downloads section for the pipeline reference
- Below is a preview of the output from the Redshift Table List Snap depicting that all the tables records from the mentioned schema:
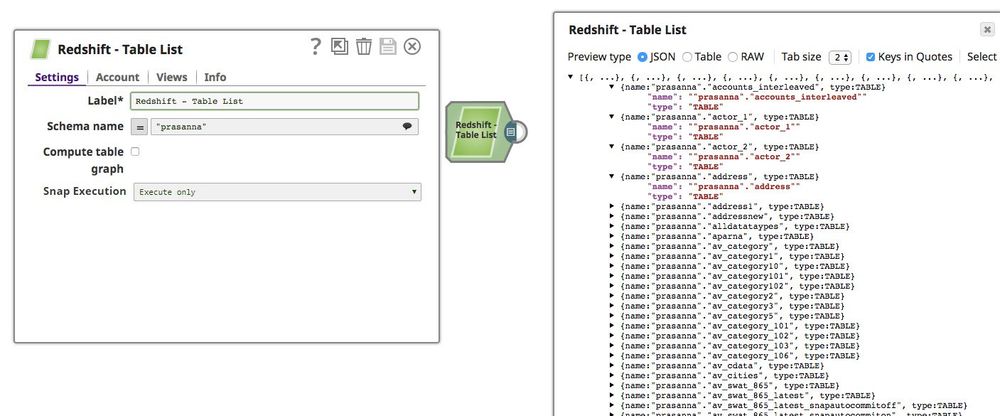
Refer to the "Redshift Table List_1.slp" in the Downloads section for the pipeline reference
- Below is a preview of the output from the Redshift Table List Snap depicting that all the tables records from the mentioned schema with the dependents:
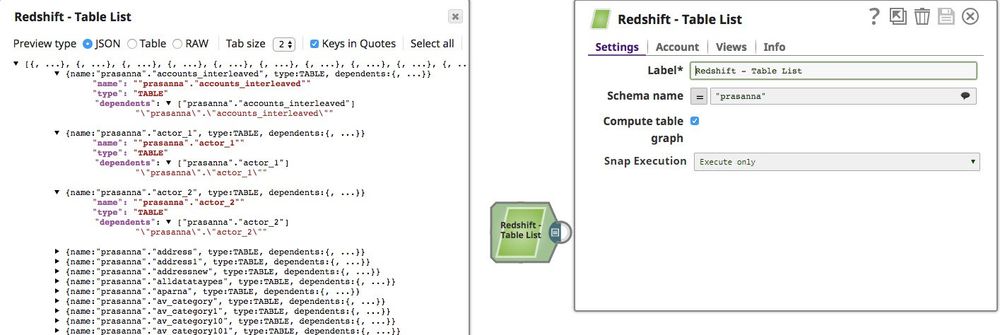
Refer to the "Redshift Table List_2.slp" in the Downloads section for the pipeline reference
Typical Snap Configurations
- Listing the tables in ALL schema without the graph of dependents as depicted in the first example of Basic Use case by providing the "Schema name"
- Listing the tables in the schema without the graph of dependents as depicted in the second example of Basic Use case by providing the "Schema name"
- Listing the tables in the schema with the graph of dependents as depicted in the third example of Basic Use case by providing the "Schema name" and selecting the "Compute table graph"
| Insert excerpt | ||||||
|---|---|---|---|---|---|---|
|